>>106297011
no one uses anything of the sort for this, retard. and the difference between a convolutional neural network vs a classic stack of 2d filters is basically just how the weights in the convolutions were derived.
>>106296547
>>106296530 (OP)
vision-language embedding models. you train an image model and a text model to embed images and text into the same vector space, reward closeness in matching pairs and punish it in non-matching ones
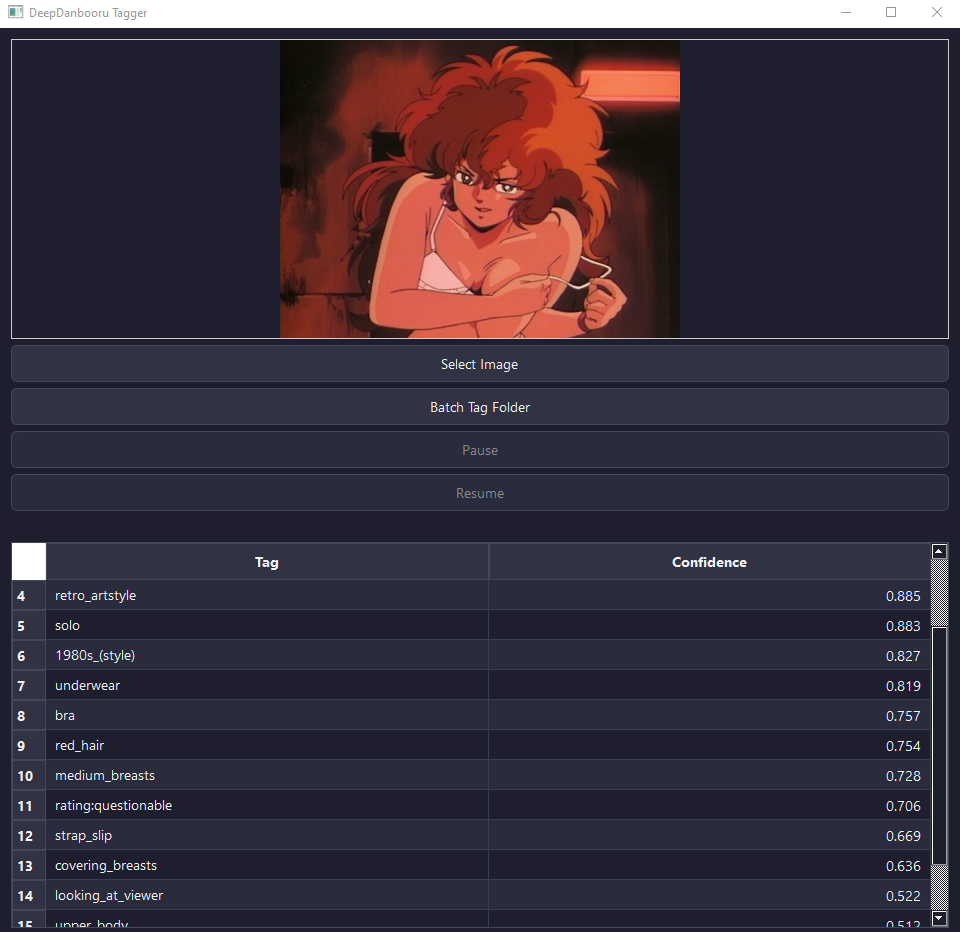
the result is that the model simply predicts how likely each tag is to be present in the image description.