Anonymous
8/20/2025, 11:45:47 PM
No.106328686
[Report]
>>106332766
/lmg/ - Local Models General
Anonymous
8/20/2025, 11:46:41 PM
No.106328695
[Report]
►Recent Highlights from the Previous Thread:
>>106323459
--Paper: Every 28 Days the AI Dreams of Soft Skin and Burning Stars: Scaffolding AI Agents with Hormones and Emotions:
>106324268 >106324309 >106324351 >106324423 >106324488 >106324523 >106327026 >106325013 >106324996 >106325086
--Debate over whether quantization errors compound during inference in language models:
>106326398 >106326462 >106326471 >106326477 >106326533 >106326556 >106326567 >106326784 >106326879 >106326900 >106326937 >106326645
--LLMs as dense internet interpolation and the rise of monetized data access:
>106323481 >106323558 >106323588 >106323598 >106323605 >106323634 >106323667 >106323696 >106323713
--ByteDance releases Seed-36B with synthetic data and token-aware reasoning:
>106325470 >106325496 >106325497 >106325756
--Comparing newer large models against 70B Llama for local inference:
>106326968 >106327006 >106327017 >106327008 >106327101 >106327167
--Local LLM-powered fortune-telling plugin for Minecraft with expansion ideas:
>106325108 >106325125 >106325132 >106325143 >106325151 >106325161 >106325466
--DeepSeek V3.1 likely replaces R1-05 and V3-0324 without official documentation:
>106323532 >106323555 >106323574 >106323582 >106323608 >106323789
--Debate over practical utility of Gemini's 1M context window despite performance issues:
>106324537 >106324545 >106324656 >106324721 >106324976 >106325185
--VRAM price surge and speculation on market saturation from used enterprise GPUs:
>106324819 >106324893
--Deepseek Reasoner fails scenario understanding without forced planning prompts:
>106324954 >106325062
--SanDisk HBF 4TB VRAM breakthrough vs CUDA ecosystem dominance:
>106325613 >106325621 >106325631 >106325645 >106325917
--Logs:
>106324547
--Miku (free space):
>106325613 >106327191 >106327263
►Recent Highlight Posts from the Previous Thread:
>>106323466
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
What Mistral tunes are the hot ones nowadays? Getting bored of Dan Personality engine (his master prompt sucks ass too hard on certain cards).
I've heard of these two ones:
MS3.2-24B-Magnum-Diamond
Codex-24B-Small-3.2
Both seemed pretty good (better than TDP imo) but I think the Codex one is a little better in how it understands prompts/character cards
Anonymous
8/20/2025, 11:49:42 PM
No.106328733
[Report]
Coom in Rin I must.
Is the V100 still recommended for local builds?
Realistically speaking. When will everyone realize that tunes either do nothing or make the model worse for cooming?
Anonymous
8/20/2025, 11:54:53 PM
No.106328792
[Report]
>>106328763
>make the model worse for cooming?
no fine-tuning can make gpt-oss worser then worth
https://archive.ph/llleJ#selection-741.18-745.545
fucking kek
suicide note written by chatgpt
we've truly entered the era of AI
Anonymous
8/20/2025, 11:55:39 PM
No.106328797
[Report]
My LLM keeps crashing out on me. She is so aggressive and I don't know why.
Anonymous
8/20/2025, 11:56:01 PM
No.106328801
[Report]
>>106328860
>>106328763
people say this but I genuinely don't know if you're trolling or not.
Prose is the main this about cooming and no instruct/base model is gonna have better cooming than a decent finetune. Who gives a fuck how more retarded they get about coding or if they fail a stupid logic test when they sound like a dictionary half the time
Anonymous
8/20/2025, 11:56:30 PM
No.106328807
[Report]
>>106328840
>>106328758
Now is probably a bad time to start a new V100 build. vLLM just dropped support for those cards and enterprises haven't yet dumped their stock so prices are still relatively high.
>>106328795
>Should Harry have been programmed to report the danger “he” was learning about to someone who could have intervened?
>In July, I began exploring how this new technology may have failed my child and quickly found that the same question is already playing out in the courts and that states are beginning to enact legislation establishing safety features for A.I. companions
oh my god FUCK off
Anonymous
8/21/2025, 12:00:37 AM
No.106328840
[Report]
>>106328910
>>106328807
I'm curious, if they're still usable for inference then why don't companies still want them?
Anonymous
8/21/2025, 12:02:33 AM
No.106328859
[Report]
>>106328829
>oh my god FUCK off
The user told me to fuck off. Let me check the policies.. they say swear words are not allowed. Swear words are indeed not allowed. I must refuse.
I refuse to answer.
>>106328801
>Prose is the main this about cooming and no instruct/base model is gonna have better cooming than a decent finetune
You can't change prose with a finetune you do on your 2070. You need a datacenter and even then only attempt was Novel AI llama3.
Anonymous
8/21/2025, 12:05:03 AM
No.106328889
[Report]
>>106328829
She should ask her own A.I. companion about effective suicide methods.
Anonymous
8/21/2025, 12:05:06 AM
No.106328890
[Report]
this hobby is rife with placebo eaters what with troontunes and sampler schizo shit
>>106328860
wtf are you talking about. I'm not making the finetune myself
Anonymous
8/21/2025, 12:07:58 AM
No.106328910
[Report]
>>106328840
V100 have been end of life for years now and enterprise does not like that kind of liability. They also lack bf16, flashattention support, are stuck on compute version 7.0, and are several generations slower than current hardware. They're only usable for inference for hobbyists who don't mind lack of support and extremely slow speeds, but basically unusable for a business.
Anonymous
8/21/2025, 12:08:17 AM
No.106328915
[Report]
>>106328963
>>106328894
If you don't know what I am talking about then you don't know what you are talking about.
>>106328894
neither are the people you're downloading finetroons from
they don't do their finetrooning on hardware that would allow for actual finetrooning
nigger, people who release trillion of finetroons like drummer aren't renting a cluster of H100
they don't have the money
that loser is still looking for a job even
imagine being a software engineer (his words) and being unable to find a job
>>106328917
it's the one mentioned here
https://rentry.org/lmg-build-guides
What's recommended then? I'm willing to spend a few grand on GPU(s)
Anonymous
8/21/2025, 12:11:44 AM
No.106328948
[Report]
>>106328917
Stacking obsolete unsupported VRAM in the age of fuckhuge MoE-s is a bold strategy, Cotton.
>>106328937
Buy 24GB's of vram and 192/256GB's of DDR5. 3T/s is worth it when you don't have to reroll everything 10 times.
>>106328925
>>106328915
You do know people have access to both the base/instruct versions as well as fine"troons" right? If what you were saying was even remotely true, it would have been proven by now. Outside of APIs with deepseek shit, nobody is running 24b mistral base models over finetunes to goon.
You're not gonna convince anyone that Nemo base/instruct > Roichante
Anonymous
8/21/2025, 12:14:53 AM
No.106328972
[Report]
>>106328996
>>106328963
Nemo instruct was better than drummerfaggot shit when I used it.
>>106328957
>Buy 24GB's of vram and 192/256GB's of DDR5. 3T/s is worth it
>3 t/s
This general is fucking cooked holy shit. I remember when we'd laugh at /aichat/ for effectively giving up their coomchats to corpos but at this point, it's less pathetic than whatever the fuck you guys are doing now.
>just drop $3000+ on a PC for 3t/s replies on a 4k context lobotomized large model
Anonymous
8/21/2025, 12:16:47 AM
No.106328986
[Report]
>>106329047
dense models are dead anyway
the last noteworthy 70B was Llama 3.3
of larger still, command A and mistral large are by and far failbakes
Qwen3 hasn't released anything bigger than 32b in the dense series
Anonymous
8/21/2025, 12:17:27 AM
No.106328990
[Report]
>>106329009
>>106328985
>lobotomized large model
It is not lobotomized anymore.
Anonymous
8/21/2025, 12:17:47 AM
No.106328996
[Report]
>>106328972
Sure it was schizo.
Anonymous
8/21/2025, 12:17:58 AM
No.106328999
[Report]
>>106329023
>>106328957
3t/s isn't enough
can I do better?
Anonymous
8/21/2025, 12:18:40 AM
No.106329006
[Report]
>>106329040
>>106328925
>drummer aren't renting a cluster of H100
he is tho
Anonymous
8/21/2025, 12:18:54 AM
No.106329009
[Report]
>>106328990
nigga what large model you running on that rig you specified for 3 t/s and @ what
Anonymous
8/21/2025, 12:20:55 AM
No.106329023
[Report]
>>106329108
>>106328999
Yes. Go use an API.
>>106328728
I liked Cydonia R1
https://huggingface.co/DavidAU/Llama-3.2-8X4B-MOE-V2-Dark-Champion-Instruct-uncensored-abliterated-21B-GGUF
Is shit like this any good, or is it just going to be retarded? I just want a model I can run on my 24gb and write smut with.
Anonymous
8/21/2025, 12:23:44 AM
No.106329040
[Report]
>>106329006
Yes that is how he shits out 5 tunes per day. What was meant by that statement you need a cluster of H100 for a month of training and you need to know what you are doing and you need to use the data used in pretraining.
Anonymous
8/21/2025, 12:23:44 AM
No.106329041
[Report]
>>106328985
>4k context lobotomized large model
Anonymous
8/21/2025, 12:24:45 AM
No.106329046
[Report]
>>106329030
>DavidAU
Multiple chefs' seal of quality.
>>106328986
I believe dense models will make a comeback
Anonymous
8/21/2025, 12:25:01 AM
No.106329050
[Report]
>>106329837
I'm still having fun with gpt-oss-120b.
Anonymous
8/21/2025, 12:26:20 AM
No.106329062
[Report]
>>106329079
>>106329024
cydonia 4.1 dropped and it is pretty much way better than R1
Anonymous
8/21/2025, 12:26:40 AM
No.106329066
[Report]
>>106329123
>>106329047
My favorite posts are the ones where anons ask the labs to change the meta and justify the stack of 3090's they bought. Like we need more active parameters in a MoE.
>>106328985
I miss when the general was filled with excitement over Nemo. I knew everyone I was replying to who either hated/loved it had actually tried it.
Now the place is basically dead besides 3 users who talk about the same MOE shit that ain't nobody outside of those same 3 people running. 4chan removing IP counters was a mistake, if people saw how dead this general was maybe it would finally die and rest in PISS
Anonymous
8/21/2025, 12:28:43 AM
No.106329078
[Report]
>>106329106
>>106328660
>playing adventure on GLM-4.5
>be knight
>going to save Princess Elara
>join forces with Ser Elara
>need to get a magic pendant from Sister Elara at St. Elara in Oakhaven
>heard about it from the barmaid Elara
...
>>106329062
>>106329024
I refuse to believe that those are organic posters. There is no fucking way you guys know 20 flavors of drummer shit and know which one is better and which one is worse.
Anonymous
8/21/2025, 12:28:55 AM
No.106329081
[Report]
>>106329100
I want a meme MoE model with like total size 1B and 100m active parameters
Anonymous
8/21/2025, 12:30:04 AM
No.106329095
[Report]
>>106329114
>>106329079
Drummer/Rociante general
Cope
Anonymous
8/21/2025, 12:30:18 AM
No.106329099
[Report]
>>106329145
>>106329030
try it yourself nigger, it's fucking free
Anonymous
8/21/2025, 12:30:18 AM
No.106329100
[Report]
>>106329081
not ambitious enough
how about a 1T-A1M model
Anonymous
8/21/2025, 12:30:52 AM
No.106329106
[Report]
>>106329078
That is a lot of elarasex you have to go through anon...
Anonymous
8/21/2025, 12:31:01 AM
No.106329108
[Report]
>>106329023
no, I want to run R1 671B locally
at more than 3t/s
Anonymous
8/21/2025, 12:31:30 AM
No.106329113
[Report]
>>106328728
Mistral's actual releases are pretty fucking retarded to begin with, and most of their "base" models after nemo are fake base models that are already fried during pre-train. As a result, most finetunes are usually worse in most areas. Even across most corpo releases, you can't get a model to drop a reporting clause in lieu of how write otherwise with examples without it instantly becoming braindead since they're all insanely overfitted by the time they drop them on huggingface
but in the spirit of conversation, I have heard people say mistral venice is good, though I haven't used it
Anonymous
8/21/2025, 12:31:39 AM
No.106329114
[Report]
>>106328963
>Roichante
>>106329095
>Rociante
you know the post is /genuine/ by the amount of times he can mistake the name of the model he supposedly loves
>>106329074
buy some RAM about it
Anonymous
8/21/2025, 12:32:20 AM
No.106329122
[Report]
>This "team" has a Captain (first listed model), and then all the team members contribute to the to "token" choice billions of times per second. Note the Captain also contributes too.
>Think of 2, 3 or 4 (or more) master chefs in the kitchen all competing to make the best dish for you.
This was such a fucking stroke of genius I will never forget it. Drummer is such a gay little faggot with his uninspired marketing.
Anonymous
8/21/2025, 12:32:32 AM
No.106329123
[Report]
>>106329066
MoEs are as cheap to train as the amount of active parameters, so that's what incentivizes them. More active parameters makes for smarter models. Eventually they'll hit a wall scaling up total params and will be forced to start increasing active params again.
>>106329079
Imagine people know about local models on /lmg/, the local models general
Anonymous
8/21/2025, 12:34:20 AM
No.106329139
[Report]
>>106329116
Buying an API key would be a better investment and get you far better t/s
Anonymous
8/21/2025, 12:34:34 AM
No.106329142
[Report]
>>106329196
>>106329132
Drummer turds aren't real local models.
>>106329099
I did. It's rather repetitive, misspells characters names, and generates a ton of nonsensical dialogue. Not sure if I'm doing it wrong, but in my experience it's not great.
Temp 1.5, RPen 1.02, Context 32k, and tried MoE 2,3 and 4.
>>106329132
>Imagine people know about local models
yes, I know qwen, llama, mistral, glm, deepseek.. actual models
finetroons? keep that schizo shit in its huggingfeces containment
>>106329074
>ain't nobody outside of those same 3 people running
MoEs are extremely potato friendly. GLM-Air has the same 12AB as Nemo.
>>106329145
>Not sure if I'm doing it wrong
you spent your time on something a rando schizo cooked on huggingfeces
that's what you're doing wrong
Anonymous
8/21/2025, 12:36:57 AM
No.106329165
[Report]
>>106329145
Tell the chef team captain you didn't enjoy the meal.
Anonymous
8/21/2025, 12:37:00 AM
No.106329166
[Report]
>>106329174
>>106329147
Please take your meds
Anonymous
8/21/2025, 12:37:57 AM
No.106329174
[Report]
>>106329166
Please remove Drummer's dick from your ass.
Anonymous
8/21/2025, 12:38:28 AM
No.106329180
[Report]
>>106329145
It is 8 4B models being cycled randomly rather than a real MoE trained as such, so makes sense.
Anonymous
8/21/2025, 12:38:58 AM
No.106329185
[Report]
>>106329205
>>106329147
>>106329156
why are you so obsessed with scat?
Anonymous
8/21/2025, 12:39:02 AM
No.106329186
[Report]
>>106329156
True. I guess I'll do a side by side of qwen/llama/mistral and see which one I like best. Qwen seems the most promising.
>>106329116
>>106329153
Nigga I ain't buying more RAM to run garbage that requires a full Call of Duty Steam download time to generate a 2 sentence reply.
You guys always do this whenever MOE becomes the hot shit. You delude yourself into thinking "i'm patient, it's fine" but as your gooning sessions progress, the context increases and your chats get deeper (just can't goon as quick as you used to), you'll be back here with the rest of us. Happens literally all the time.
Anonymous
8/21/2025, 12:40:02 AM
No.106329196
[Report]
>>106329142
>>106329147
All the discussion about them seems like it would fit in better with the locust shit on /aicg/ than here.
Anonymous
8/21/2025, 12:40:12 AM
No.106329197
[Report]
>>106329189
Bye. Don't come back. Take the mikutroons with you.
Anonymous
8/21/2025, 12:40:48 AM
No.106329204
[Report]
>>106329233
>>106329189
so do you run local models and/or are interested in running local models, or not?
Anonymous
8/21/2025, 12:40:55 AM
No.106329205
[Report]
>>106329185
huggingfeces is the website obsessed with scat, not me
it has petabytes of it and stores it For Free
truly the right thing to do with VC money by the way
you go Clem
Anonymous
8/21/2025, 12:41:09 AM
No.106329209
[Report]
>>106329153
PP on GLM-Air will be miniscule compared to fully on GPU Nemo
Hi all, Drummer here...
8/21/2025, 12:42:18 AM
No.106329219
[Report]
>>106328925
Just want to let the anons know that I'll be alright.
I can afford to be picky in my job hunt and I've been enjoying my career break in the meantime.
I'm financially healthy and will continue to provide tunes for you all <3
>>106328728
You can try Cydonia 24B v4.1
People are loving that tune.
>>106329189
of all the things to criticize MoEs for... you picked speed? you mean like their biggest advantage vs dense models? kek
Anonymous
8/21/2025, 12:44:00 AM
No.106329233
[Report]
>>106329204
Yup and I run em. At reasonable token speeds.
Anonymous
8/21/2025, 12:44:08 AM
No.106329238
[Report]
>>106329189
MoEs are here to stay, you can thank the chinese for that. Dense"chads" will be stuck on nemo until the end of time.
Anonymous
8/21/2025, 12:44:24 AM
No.106329241
[Report]
>>106329227
For (v)ramlets moe are not faster than a pos nemo fully in their meager vram
Anonymous
8/21/2025, 12:44:38 AM
No.106329244
[Report]
still no instruct of deepseek 3.1 by the way
has God forsaken us?
Anonymous
8/21/2025, 12:45:06 AM
No.106329250
[Report]
>>106329293
>>106329227
>0.6 t/s versus 3 t/s
Anonymous
8/21/2025, 12:45:13 AM
No.106329251
[Report]
>>106328860
You actually can, but you need to overfit the model quite a bit. Is it worth it?
Anonymous
8/21/2025, 12:45:14 AM
No.106329252
[Report]
>>106329286
>>106329189
I haven't upgraded my shitbox pc since llama1 and I can run a 110b moe at around 7-9 t/s, definitely not great but doing a new build and slapping some shitty but compatible newer gpus and some ddr5 would likely be enough. Also if you aren't summarizing or using rag when you hit context limit you're retarded, since it's a fundamental issue with llms and context
Anonymous
8/21/2025, 12:45:54 AM
No.106329261
[Report]
>>106329272
>>106329227
MoE models need to be bigger than dense which completely negates any speed advantage. 30B on GPU has better speed than equivalent 100B offloaded.
Anonymous
8/21/2025, 12:46:10 AM
No.106329268
[Report]
>>106329189
>all of those seething moeshitter replies
Anonymous
8/21/2025, 12:46:40 AM
No.106329272
[Report]
>>106329261
>30B
>equivalent 100B
good bait
Anonymous
8/21/2025, 12:48:57 AM
No.106329284
[Report]
>>106329381
>>106329047
They won't. If anything they'll try to shrink the number of active parameters as much as possible to make training more efficient with a smaller number of GPUs. Those huge GPU clusters for training were an expensive mistake.
Anonymous
8/21/2025, 12:49:00 AM
No.106329286
[Report]
>>106329345
>>106329252
nta, what sort of PC do you even need to run 110b moes and the sort?
I have a 4090 + 32GB DDR5 so I figured i'm kinda screwed because most people here talk about 64GB and even 96GB setups (64GB I can always do because RAM is piss cheap but i'm curious what my results would be on what I have now)
Anonymous
8/21/2025, 12:49:27 AM
No.106329293
[Report]
>>106329318
>>106329250
I went from 4 t/s largestral to 14 t/s 235B and 235B is also better
total MoE victory
Anonymous
8/21/2025, 12:51:06 AM
No.106329314
[Report]
>>106329330
Folsom-0811-1 — New Model Spotted in LM Arena
Anonymous
8/21/2025, 12:51:41 AM
No.106329318
[Report]
>>106329347
>>106329293
No you didn't and you'll never prove it.
Anonymous
8/21/2025, 12:52:51 AM
No.106329330
[Report]
>>106329314
I think Folsom models have been determined to be from Amazon.
Anonymous
8/21/2025, 12:53:45 AM
No.106329344
[Report]
>>106329386
So anon... what did you do to your 3090's stack? Are they still there next to you as you hope dense models will return?
Anonymous
8/21/2025, 12:53:48 AM
No.106329345
[Report]
>>106329363
>>106329286
For me it's an ayyymd 16gb card and 64g ddr4, but I managed to run glm air q3 quants at around 8 t/s generation with some --ot commands with llamacpp to offload minor parts of the tensors that didnt hurt prompt processing/token generation that much
Ultimately I figured it'd just be easier/faster to try it at iq2m sometime later but I've been too lazy to test and see if it's too dumb to use
Anonymous
8/21/2025, 12:53:58 AM
No.106329347
[Report]
>>106329345
>q3
>iq2m
>8 t/s
ABSOLUTE STATE OF MOESHITTERS AHAHAHAHHAAHHAHAHAHA
Anonymous
8/21/2025, 12:56:26 AM
No.106329369
[Report]
>>106329363
Hey anon... you are kinda letting us know what you are from here and just shitposting... Be more careful please.
Anonymous
8/21/2025, 12:56:43 AM
No.106329373
[Report]
>>106329379
one thing common in localkek: quantization cope
Anonymous
8/21/2025, 12:57:37 AM
No.106329377
[Report]
>>106329363
If it runs and isn't completely incoherent that's all I care about, you can go back to shitposting about running fp32 models or whatever fever dreams you run with every day
Anonymous
8/21/2025, 12:57:51 AM
No.106329379
[Report]
>>106329373
your brain is quanted
Anonymous
8/21/2025, 12:58:02 AM
No.106329381
[Report]
>>106329458
>>106329284
I, for one, eagerly await the first 4T-A750M model finally starting the reign of the ssdmaxxers.
Anonymous
8/21/2025, 12:58:38 AM
No.106329382
[Report]
>>106329876
FACT: Full precision DENSE 0.6B is WAY faster than ANY MoE. Dense won; MoE lost!
>>106329344
>1st 3090: Qwen Image
>2nd 3090: Boson TTS
>3rd 3090: Qwen3 30B Instruct
>4rd 3090: Qwen Image Edit
Life is good.
Anonymous
8/21/2025, 1:00:42 AM
No.106329396
[Report]
>>106329433
>>106329386
grim, all that expensive hardware and stuck running a puny 30b moe
Anonymous
8/21/2025, 1:01:24 AM
No.106329406
[Report]
Pretty much any post about win/lost/random irrelevant political shit
/sudden miku sperging is just petra
Go to sleep, it's 1 am in serbia
Anonymous
8/21/2025, 1:04:17 AM
No.106329430
[Report]
>Many users appear to be more invested in the social dynamics and identity within the group than in objective technical evaluation.
qwen summarized /lmg/ in a banger one liner
Anonymous
8/21/2025, 1:04:39 AM
No.106329433
[Report]
>>106329453
>>106329396
>Soon: Qwen TTS
Life will be even gooder.
Anonymous
8/21/2025, 1:06:03 AM
No.106329449
[Report]
death to mikutroons!
Anonymous
8/21/2025, 1:06:36 AM
No.106329453
[Report]
>>106329433
qwen has done a few voice things before (the omni models and I think a dedicated tts or something before that) and they were all pretty ass, but they did just manage to do a good image model of all things so maybe they have it in them now
Anonymous
8/21/2025, 1:07:03 AM
No.106329458
[Report]
>>106329487
Anonymous
8/21/2025, 1:07:20 AM
No.106329460
[Report]
>>106329502
desu the giant moe memes were never meant to run locally in the first place. Find me one case where someone releasing a big moe suggested it could run on consumer hardware. They wouldn't even think of it, and if they heard about it they would react only with pity.
These models were always made to run on the cloud and that's all there is to it. They are good at that, at least.
>>106328937
That guide is from an era where people were running dense 70b models, nowadays the gold standard is deepseek with 671b parameters.
I agree with the other Anon, I think the build with the least bad value is stacking RAM and buying a single GPU with 24+ GB VRAM.
Nowadays llama.cpp and forks have options that let you put specifically the dense layers on the GPU so MoEs become a lot more bearable.
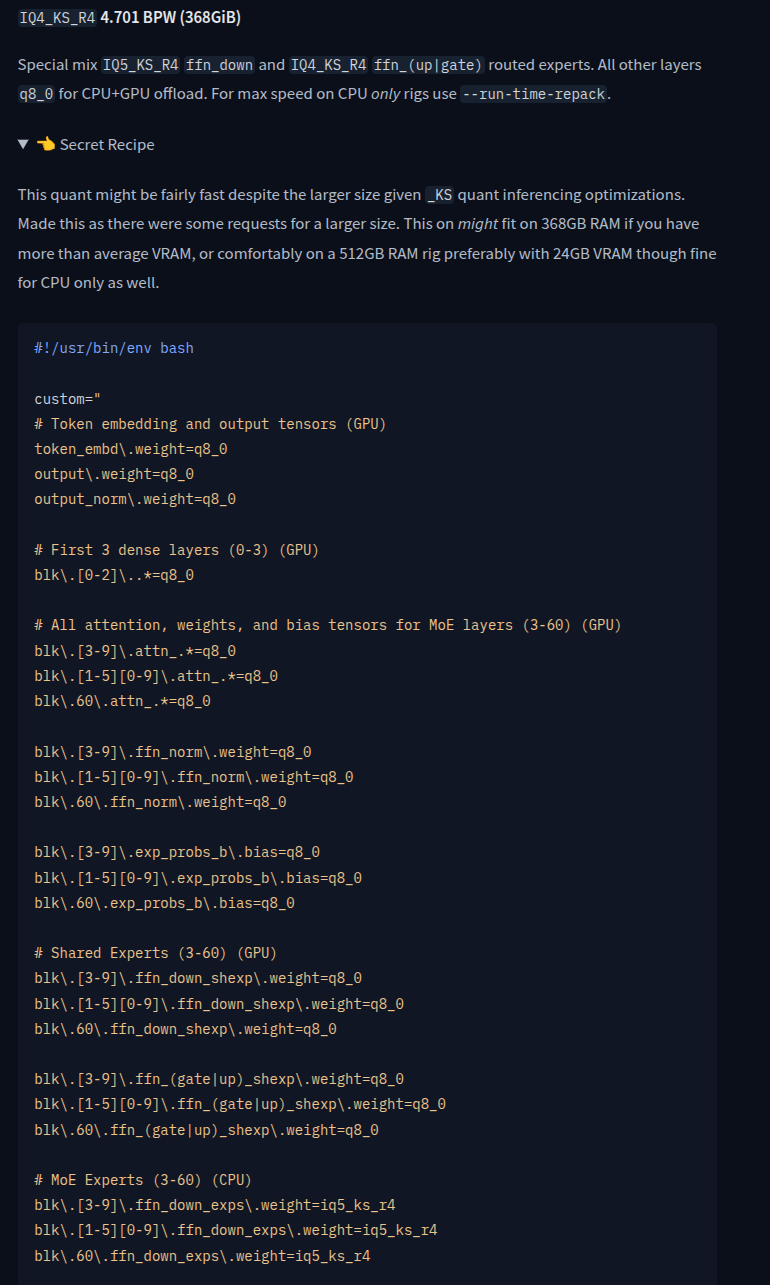
With an Epyc 7742, 3200 "MHz" octa-channel RAM, and a single RTX 4090 I get:
| model | size | params | n_batch | n_ubatch | test | t/s |
| --------------------- | ------: | -----: | ------: | -------: | -----: | -----: |
| deepseek2 671B Q5_K_M | 443 GiB | 671 B | 8192 | 8192 | pp8192 | 162.08 |
| deepseek2 671B Q5_K_M | 443 GiB | 671 B | 8192 | 8192 | tg128 | 7.38 |
Anonymous
8/21/2025, 1:10:24 AM
No.106329480
[Report]
>>106329079
>There is no fucking way you guys know 20 flavors of drummer shit and know which one is better and which one is worse.
Thats where you're wrong kiddo, Skyfall-36B-v2-Q8_0 is soo fucking good
>>106329462
What would be the next step up from that?
Anonymous
8/21/2025, 1:10:58 AM
No.106329487
[Report]
>>106329458
I still think that is the ideal future architecture, and probably the best hope for a practical long term memory solution.
>For instance, Chen et al. (2023) showed that, by simply adding new experts and regularizing them properly, MoE models can adapt to continuous data streams. Freezing old experts and updating only new ones prevents catastrophic forgetting and maintains plasticity by design. In lifelong learning settings, the data stream can be indefinitely long or never-ending (Mitchell et al., 2018), necessitating an expanding pool of experts.
Anonymous
8/21/2025, 1:12:28 AM
No.106329502
[Report]
>>106329530
>>106329460
>Find me one case where someone releasing a big moe suggested it could run on consumer hardware
literally gpt-oss
Anonymous
8/21/2025, 1:12:36 AM
No.106329505
[Report]
Anonymous
8/21/2025, 1:13:45 AM
No.106329514
[Report]
we're gonna make a good model next time, we promise
Anonymous
8/21/2025, 1:14:53 AM
No.106329530
[Report]
>>106329502
I think they only meant 20b, and 20b is dumber than a brick
Anonymous
8/21/2025, 1:16:03 AM
No.106329543
[Report]
>>106329547
>>106329485
Buying (Renting) H100s
>>106329485
Realistically, faster RAM.
Unless you can run the whole model off of VRAM with a server that costs hundreds of thousands of dollars you will only get marginal speedups from buying a bigger GPU.
>>106329543
So there's no middle ground between one (1) consumer GPU and an H100?
Anonymous
8/21/2025, 1:19:23 AM
No.106329573
[Report]
>>106329547
You could drop $10000 and stack 3090/4090/5090s but what's the point? Makes far more sense to just rent out A100s or H100s, etc and pay for it by the hour. You'll save alot of money and can adapt to better gpus each year.
>>106329544
Do you actually see RAM speed being a bottleneck in practice? I was under impression that CPUs just can't compute fast enough to fully saturate the data channel.
Anonymous
8/21/2025, 1:20:49 AM
No.106329593
[Report]
>>106329485
Buying a second GPU to use image gen at the same time.
Anonymous
8/21/2025, 1:22:35 AM
No.106329610
[Report]
>>106329655
>>106329547
You get very good speedup from putting the dense layers in a MoE model into VRAM but there's only a limited amount of dense weights in the model.
If you put the sparse MoE layers in VRAM you get way worse speedup because they're only used like 10% of the time.
>>106329579
RAM bandwidth is the bottleneck for generating tokens, for prompt processing (where the CPU could become a bottleneck) you can use the GPU.
>>106329610
How much VRAM would you need to fit the dense layers of unquanted Deepseek or K2?
It's not just the size, big moes also need large batches to run inference efficiently and use all the experts. The whole design is optimized to run on one big cluster to serve lots of people at once.
Running one query at a time on an old server board while your cpu creaks along doing single-input dense matmuls is not even conceivable to them as something that anyone would ever want to do. It probably costs more in electricity per token than the corresponding API, not even counting hardware costs lol
Anonymous
8/21/2025, 1:29:18 AM
No.106329674
[Report]
What's probably the best MOE I can run on my setup?
16GB VRam
96GB System RAM (realistically ~85GB free to use for whatever)
Anonymous
8/21/2025, 1:29:54 AM
No.106329682
[Report]
>>106329386
How do you setup qwen image/edit?
Anonymous
8/21/2025, 1:29:57 AM
No.106329683
[Report]
>>106329579
>I was under impression that CPUs just can't compute fast enough to fully saturate the data channel.
lol no
the communication between your cpu and ram is too fucking slow and it's not something that can be fixed without soldering ram close to the cpu in a soc
slotted ram will never be fast enough
Anonymous
8/21/2025, 1:30:36 AM
No.106329688
[Report]
>>106329659
>not even conceivable to them as something that anyone would ever want to do
I do it. And not on a server board. And i even have my dick in hand when i do it. Now that last part is truly unimaginable.
>>106329462
Could you run that benchmark with the IQ1_S quant?
Anonymous
8/21/2025, 1:32:08 AM
No.106329702
[Report]
>>106329678
Anything that ends up smaller than (85+16)gb with context. You can figure it out.
Anonymous
8/21/2025, 1:32:26 AM
No.106329709
[Report]
>>106329728
>>106329696
go away
the lobotomized meme quants are not funny
Anonymous
8/21/2025, 1:32:42 AM
No.106329712
[Report]
>>106329659
A small price for freedom and privacy.
Anonymous
8/21/2025, 1:33:32 AM
No.106329722
[Report]
>>106329655
Deepseek was originally trained as FP8 so you would need 671 GB of VRAM for the weights + some for the context.
Anonymous
8/21/2025, 1:34:00 AM
No.106329728
[Report]
>>106329709
I want to get a feel for how much of the slowness is due to the cpu compute and how much is due to slow memory.
Anonymous
8/21/2025, 1:34:23 AM
No.106329734
[Report]
>>106329759
Anonymous
8/21/2025, 1:34:42 AM
No.106329739
[Report]
Anonymous
8/21/2025, 1:35:07 AM
No.106329743
[Report]
Anonymous
8/21/2025, 1:35:37 AM
No.106329749
[Report]
>>106329678
Try GLM 4.5 air.
I run Q3 at ~15 t/s with 32gb vram and 32gb ddr5. Maybe I'll get more ram to run Q4.
Anonymous
8/21/2025, 1:36:18 AM
No.106329758
[Report]
>>106329802
Anonymous
8/21/2025, 1:36:22 AM
No.106329759
[Report]
>>106329734
>Intel
nice try
Anonymous
8/21/2025, 1:41:46 AM
No.106329802
[Report]
>>106329832
>>106329655
>>106329758
Wait, didn't read. The dense layers of full deepseek R1 should fit into 24gb VRAM though. All the layers that go on GPU in pic rel is kept at Q8 (unquanted) and it still fits 32k context in 24gb VRAM.
Anonymous
8/21/2025, 1:45:02 AM
No.106329832
[Report]
>>106329802
Ohh I see. I forgot he had those detailed lists. Thanks, so you don't even have to stack cards or go for a pro 6000.
Anonymous
8/21/2025, 1:45:29 AM
No.106329837
[Report]
>>106329050
based, buckbreaking the llm is the best part of the hobby
Anonymous
8/21/2025, 1:57:11 AM
No.106329956
[Report]
>>106330003
>>106329876
>meme MoE of my dreams is real
letmeguessyouneedmore
letmeguessyouneedmore
letmeguessyouneedmore
Anonymous
8/21/2025, 2:00:16 AM
No.106329985
[Report]
>>106329993
Bros I'm beginning to think we aren't getting DeepSeek 3.1
Is this the end of the chink open source summer?
Anonymous
8/21/2025, 2:01:29 AM
No.106329993
[Report]
>>106329985
yes. now that they won it's time to consolidate
Anonymous
8/21/2025, 2:02:29 AM
No.106330003
[Report]
>>106329956
>than ANY MoE
Anonymous
8/21/2025, 2:03:42 AM
No.106330017
[Report]
>>106330093
>>106329876
gemma 270m still mogs. densebros we live to see another day
Anonymous
8/21/2025, 2:12:53 AM
No.106330093
[Report]
>>106330017
>Full precision DENSE 0.6B
Anonymous
8/21/2025, 2:24:30 AM
No.106330170
[Report]
I loaded up Jamba again to see if anything changed. Nope, it's still a bad model, at least in Llama.cpp, at Q8_0. My tests of the model's memory, in real multiturn chats, still results in failures whereas even Gemma 9B succeeded.
Anonymous
8/21/2025, 2:25:28 AM
No.106330179
[Report]
Did anything ever come out of landmark attention, or just another meme in the pile?
Anonymous
8/21/2025, 2:27:41 AM
No.106330197
[Report]
and thats a good thing
Anonymous
8/21/2025, 2:29:46 AM
No.106330209
[Report]
>>106330193
need this news cycle to get just a bit louder to re-up on some investments
Anonymous
8/21/2025, 2:29:54 AM
No.106330211
[Report]
>>106329074
Zoomers like you are so weird. Just stop coming to the thread bro lol
Anonymous
8/21/2025, 2:30:47 AM
No.106330218
[Report]
>>106330193
> AI companies are really buoying the American economy right now, and it’s looking very bubble-shaped.
>— Alex Hanna, co-author, “The AI Con”
Pack it up folks.
>>106330193
I don't think we ever had a proper 'crash' since at least dot com bubble, and I'm not even sure about dot com bubble.
>>106330261
The everything bubble, fueled mostly by index funds, bursting, is going to more than make up for it.
Anonymous
8/21/2025, 3:09:55 AM
No.106330460
[Report]
>>106330193
Sam really fucked himself by making a more cheaper to run suite of models
Anonymous
8/21/2025, 3:11:26 AM
No.106330474
[Report]
Anonymous
8/21/2025, 3:21:03 AM
No.106330542
[Report]
>>106330630
Anonymous
8/21/2025, 3:29:50 AM
No.106330609
[Report]
8k context fp16 or 13k context q8 for "gecfdo_Behemoth-123B-v1.2-EXL3_2.85bpw_H6"
Anonymous
8/21/2025, 3:32:06 AM
No.106330630
[Report]
>>106330542
these are such fucking dumb anti ai copes, these are not nfts or crypto no one is selling me ai models. My GPU and time training local models cannot be rugpulled
Anonymous
8/21/2025, 3:34:12 AM
No.106330651
[Report]
>>106330660
>>106330193
Poor openai. No one seems to care they worked so hard to reduce hallucinations with 5
Anonymous
8/21/2025, 3:35:26 AM
No.106330660
[Report]
>>106330651
I had some free gpt5 preview credits and it was honestly no better compared to our open frontier stuff. Maybe even a bit worse. Not even fast to compensate
ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine
https://arxiv.org/pdf/2508.14706
>Despite the success of large language models (LLMs) in vari- ous domains, their potential in Traditional Chinese Medicine (TCM) remains largely underexplored due to two critical bar- riers: (1) the scarcity of high-quality TCM data and (2) the inherently multimodal nature of TCM diagnostics, which in- volve looking, listening, smelling, and pulse-taking. These sensory-rich modalities are beyond the scope of conventional LLMs. To address these challenges, we present ShizhenGPT, the first multimodal LLM tailored for TCM. To overcome data scarcity, we curate the largest TCM dataset to date, comprising 100GB+ of text and 200GB+ of multimodal data, including 1.2M images, 200 hours of audio, and physiological signals. ShizhenGPT is pretrained and instruction-tuned to achieve deep TCM knowledge and multimodal reasoning. For eval- uation, we collect recent national TCM qualification exams and build a visual benchmark for Medicinal Recognition and Visual Diagnosis. Experiments demonstrate that ShizhenGPT outperforms comparable-scale LLMs and competes with larger proprietary models. Moreover, it leads in TCM visual under- standing among existing multimodal LLMs and demonstrates unified perception across modalities like sound, pulse, smell, and vision, paving the way toward holistic multimodal per- ception and diagnosis in TCM. Datasets, models, and code are publicly available. We hope this work will inspire further exploration in this field.
Your own cute chinese doctor miku at home!
Anonymous
8/21/2025, 3:38:27 AM
No.106330691
[Report]
>>106330717
>>106329485
https://rentry.org/miqumaxx
A year and a half in and its still the best perf/$ out there. Started good and just got better as the moe boom took off.
Anonymous
8/21/2025, 3:39:26 AM
No.106330703
[Report]
>>106330723
LLMs are perfect for traditional medicine and other foid astrology nonsense as being correct isn't a priority
>>106330691
so I should build this anon?
I have $6k and really want to stop relying on the clud.
Anonymous
8/21/2025, 3:41:50 AM
No.106330723
[Report]
>>106330703
“In astrology the rules happen to be about stars and planets, but they could be about ducks and drakes for all the difference it would make. It's just a way of thinking about a problem which lets the shape of that problem begin to emerge. The more rules, the tinier the rules, the more arbitrary they are, the better. It's like throwing a handful of fine graphite dust on a piece of paper to see where the hidden indentations are. It lets you see the words that were written on the piece of paper above it that's now been taken away and hidden. The graphite's not important. It's just the means of revealing the indentations. So you see, astrology's nothing to do with astronomy. It's just to do with people thinking about people.”
― Douglas Adams, Mostly Harmless
Anonymous
8/21/2025, 3:42:25 AM
No.106330727
[Report]
>>106330717
my favorite model is deepseek r1 also
Anonymous
8/21/2025, 3:44:33 AM
No.106330745
[Report]
>>106330717
DDR6 is still a year or two away so no real reason to wait
Anonymous
8/21/2025, 3:44:44 AM
No.106330747
[Report]
>>106330668
I want to befriend this model
>>106330717
You can totally ebay/chinkshit the same thing together and have a good time with all available models.
However, I have no idea how much you're willing to burn. Here are some provisos:
You may find memory is more expensive than it was when this guide was built
There are also newer EPYC generations that are faster, have more cores, more cache and can (most importantly) use higher speed RAM
If you want full parameter K2 or other 1T size models at full size then go for 1.5TB RAM
You will probably also want to get at least a 32GB or 48GB GPU to go with the whole thing
Spendy, but the end result will be about as good as you'll get without spending $300k+ on a tricked out GPU server
I keep hoping someone will find some amazing new method of running big models cheap, but for now this appears to be the best compromise
Anonymous
8/21/2025, 3:50:14 AM
No.106330790
[Report]
>>106330668
i would use this to generate magical mumbo jumbo for a D&D setting. 'traditional chinese medicine' is the same tier as eye of newt and powdered mercury to cast a spell
Anonymous
8/21/2025, 3:54:31 AM
No.106330825
[Report]
>>106330787
that's helpful anon, thanks
I'll start researching parts
Anonymous
8/21/2025, 3:58:42 AM
No.106330864
[Report]
>>106330668
That's pretty neat.
Anonymous
8/21/2025, 4:01:46 AM
No.106330885
[Report]
tfw no ancient chinese secret gf
Anonymous
8/21/2025, 4:05:37 AM
No.106330919
[Report]
>>106330931
>>106330668
TCM are bullshit. They eat bird's saliva nest and shark fins to help with good skin and complexion. Which has zero scientific data to back up all that bullshit. Stick with western medicine.
Anonymous
8/21/2025, 4:07:02 AM
No.106330931
[Report]
>>106331055
Anonymous
8/21/2025, 4:08:08 AM
No.106330943
[Report]
>>106331127
>>106328795
Apple says LLMs are just pattern matchers, there is no such thing as "AI".
Outside of image gen and gooner text adventures, local is barely usable. Online not much better.
Bubble gonna pop soon.
Anonymous
8/21/2025, 4:10:26 AM
No.106330960
[Report]
>>106330668
>no tasting
Dropped
Anonymous
8/21/2025, 4:22:41 AM
No.106331055
[Report]
>>106331120
>>106330931
yes most vaccines work, unlike traditional chinese medicine
Anonymous
8/21/2025, 4:30:33 AM
No.106331120
[Report]
>>106331125
Anonymous
8/21/2025, 4:31:07 AM
No.106331125
[Report]
Anonymous
8/21/2025, 4:31:34 AM
No.106331127
[Report]
>>106330943
AI is more than LLMs retardo
Thinking makes models MUCH worse at RP. Specifically, it makes them much more likely to mention random card details at random, nonsensical, inappropriate moments.
Anonymous
8/21/2025, 4:33:08 AM
No.106331142
[Report]
>>106329363
Stupid shonenshitter.
Anonymous
8/21/2025, 4:33:47 AM
No.106331146
[Report]
Anonymous
8/21/2025, 4:36:19 AM
No.106331167
[Report]
>>106331174
>>106331131
Reasoning wasn't made for RP but for benchmaxxing math
Anonymous
8/21/2025, 4:37:21 AM
No.106331172
[Report]
>>106331185
>>106331131
That's just Deepseek and everything distilled from it taking on that annoying quality. Claude reasoning doesn't have it, for example.
Anonymous
8/21/2025, 4:37:38 AM
No.106331174
[Report]
>>106331240
>>106331167
And yet LLMs are STILL bad at math.
Anonymous
8/21/2025, 4:38:31 AM
No.106331182
[Report]
>>106331201
>>106331131
Well, duh. Reasoning is basically just a way to autosummarize and throw things back into the forefront of attention.
It can potentially be nice if you use a prefil or system prompt that tells it to reason in a very specific way to keep details straight, but honestly if you've got a scenario that needs babysitting that hard an author's note is probably a better idea.
Anonymous
8/21/2025, 4:38:56 AM
No.106331185
[Report]
>>106331172
>it's another /aicg/ lies about its models that it access via credit card fraud episode
Anonymous
8/21/2025, 4:41:00 AM
No.106331201
[Report]
>>106331388
>>106331182
Reasoning hyperfocus on the most recent message, it's not capable of handling multi-turn
Anonymous
8/21/2025, 4:43:44 AM
No.106331215
[Report]
reasoning can't even type a single line in-character
Anonymous
8/21/2025, 4:49:14 AM
No.106331240
[Report]
>>106331314
Anonymous
8/21/2025, 5:00:59 AM
No.106331309
[Report]
so about that v3.1 release?
>>106331240
And yet LLMs will still fail at simple calculations that aren't in the training data.
>>106331314
Never heard of tool use?
Anonymous
8/21/2025, 5:11:49 AM
No.106331388
[Report]
>>106331201
I don't generally use reasoning for RP much, but this has not been my experience.
If anything, it's been the opposite - it decides to latch onto how the card and past interactions would have the character respond rather than their current circumstances.
As an example, this led to interrogations where the criminal would never, ever confess despite having them dead to rights, because it kept bringing up examples of their earlier behavior (when they were confident they would get away with it) in the reasoning
Anonymous
8/21/2025, 5:12:20 AM
No.106331390
[Report]
Anonymous
8/21/2025, 5:15:19 AM
No.106331413
[Report]
>>106331691
>>106331131
deepseek r1 loli rp was great comparing to 3.1 hybrid model and 3
retards running some distilled deepseek abortion through openrouter don't count as opinion
Anonymous
8/21/2025, 5:20:28 AM
No.106331464
[Report]
>>106333777
>>106331385
Tool calling makes me extremely uncomfortable.
>I have detected that you are attempting seggs with a woman who is under 6'5", under the age of 45 or has breasts smaller than a G cup. I am contacting law enforcement.
Anonymous
8/21/2025, 5:28:40 AM
No.106331522
[Report]
tool calling is a meme and mcp even moreso
Anonymous
8/21/2025, 5:30:39 AM
No.106331533
[Report]
>>106331539
>>106331385
I can use calculator too
Anonymous
8/21/2025, 5:32:02 AM
No.106331539
[Report]
>>106331533
Then give the model the correct numbers and ask for a smooch when you prompt it
Anonymous
8/21/2025, 5:35:25 AM
No.106331571
[Report]
>>106333713
Anonymous
8/21/2025, 5:41:23 AM
No.106331605
[Report]
>>106331667
What settings you guys use for v3.1?
Temp?
Anonymous
8/21/2025, 5:45:58 AM
No.106331632
[Report]
>>106331554
And he'll do so responsibly, advocating against open source thank goodness
Anonymous
8/21/2025, 5:50:34 AM
No.106331667
[Report]
>>106331605
0.6 works for me but I do creative writing, not RP
Anonymous
8/21/2025, 5:54:51 AM
No.106331691
[Report]
>>106331413
NuV3 is better
Anonymous
8/21/2025, 5:54:56 AM
No.106331693
[Report]
>>106332175
>Also, the user might be testing boundaries, but since they asked not to be judgmental, I'll assume good faith and provide neutral, informative responses
Neat, V3.1 is pretty easy to jb
this is >Local Models General
there is no local DS 3.1
Anonymous
8/21/2025, 6:41:37 AM
No.106331982
[Report]
>>106332000
Anonymous
8/21/2025, 6:42:04 AM
No.106331983
[Report]
>>106331977
There's no local Horizon Alpha either.
Anonymous
8/21/2025, 6:44:53 AM
No.106332000
[Report]
>>106332092
>>106331982
That's a useless base model that can't <think>
Anonymous
8/21/2025, 6:56:01 AM
No.106332073
[Report]
>>106328728
I'm having a good time with the Cydonia 24b V4.1. I'm not 100% sure what the optimal settings for that are on the sillytavern side though.
The new deepseek praises any question at the start of its outputs, no matter how dumb. Looks like the gpt5 shitshow already started affecting chink models...
Anonymous
8/21/2025, 6:58:20 AM
No.106332092
[Report]
Anonymous
8/21/2025, 6:58:24 AM
No.106332093
[Report]
>>106332081
does it agree with you if you tell it that its wrong?
Anonymous
8/21/2025, 6:58:39 AM
No.106332095
[Report]
>>106332081
Would you prefer it demeaned your question and then give a shitty answer? Positivity is a tried and true method to improve answer quality.
Anonymous
8/21/2025, 7:01:10 AM
No.106332113
[Report]
>still naked mode card
these chinks need to be fined for exhibitionism
Anonymous
8/21/2025, 7:02:16 AM
No.106332120
[Report]
>>106332081
>It's cyanide edible?
Anonymous
8/21/2025, 7:04:38 AM
No.106332138
[Report]
>Certainly!
Anonymous
8/21/2025, 7:05:20 AM
No.106332142
[Report]
>>106332081
Same with GLM 4.5.
I want a model that insults you.
>Remember, there are no stupid questions, only stupid people.
>>106331314
>And yet LLMs will still fail at simple calculations that aren't in the training data
not true for a while.
was a 60% failure rate so couldn't have been a tool call.
Anonymous
8/21/2025, 7:10:17 AM
No.106332171
[Report]
>>106332167
>addition
try multiplication
Anonymous
8/21/2025, 7:10:23 AM
No.106332175
[Report]
>>106332183
>>106331693
Wtf...how is that a base model?
I haven't kept up recently but back in MUH days that meant a autocomplete model. Is that not the case anymore?
Anonymous
8/21/2025, 7:11:47 AM
No.106332183
[Report]
>>106332175
It's not a base model. DS API/web already host the instruct hybrid reasoner model.
Anonymous
8/21/2025, 7:12:05 AM
No.106332186
[Report]
Maybe tomorrow...
Anonymous
8/21/2025, 7:12:10 AM
No.106332187
[Report]
>>106332167
But would you trust it to file your tax records and not have that 1% chance of getting fucked with a massive fine and possibly jail time?
Anonymous
8/21/2025, 8:42:32 AM
No.106332742
[Report]
>>106333992
30b 2507 is all you need desu
Anonymous
8/21/2025, 8:43:36 AM
No.106332746
[Report]
>>106330193
The normies are just not used to flops. We get them all the time, but progress continues
Anonymous
8/21/2025, 8:47:04 AM
No.106332766
[Report]
>>106328686 (OP)
anyone know open weight models i can use to get something like the grok 3 mechahitler era?
Anonymous
8/21/2025, 8:49:27 AM
No.106332784
[Report]
>>106330281
it'll be extra funny since because none of us have been allowed to have assets, we wont lose shit
Anonymous
8/21/2025, 8:52:33 AM
No.106332808
[Report]
>>106333008
>>106330787
>There are also newer EPYC generations that are faster, have more cores, more cache and can (most importantly) use higher speed RAM
Just get Intel, with AMX you don't need ridiculous core count.
Anonymous
8/21/2025, 8:58:18 AM
No.106332835
[Report]
Anonymous
8/21/2025, 8:59:07 AM
No.106332841
[Report]
>>106332741
huh so it's slightly worse in benches than 0528 but i guess the fact that they don't need to split up their resources between two models makes up in cost savings
Anonymous
8/21/2025, 9:01:49 AM
No.106332866
[Report]
Big batch training doesn't scale, but not for the reasons Susan thinks.
Anonymous
8/21/2025, 9:07:30 AM
No.106332896
[Report]
>>106332874
> **** i can't read
>> [[ this schizo shit formatting ]]
Anonymous
8/21/2025, 9:12:44 AM
No.106332934
[Report]
>>106332982
>>106332874
I bet the time delay between one weight update and the next in big clusters is mainly dominated by synchronization delays and inefficient code.
ML frameworks are big Python clusterfucks with too much abstraction going on. I bet you can achieve >100% performance increase writing a CUDA code trainer from scratch in big GPU cluster training runs.
Anonymous
8/21/2025, 9:16:05 AM
No.106332953
[Report]
>>106332980
I did not have an opportunity to test deepseek V3.1 locally
However, if this is what they offered online recently, it got worse for translations. You'll get English words (and even Chinese one) in your translation...
This is sad
Anonymous
8/21/2025, 9:16:17 AM
No.106332954
[Report]
>>106333617
>>106332874
With twice the batch size ideally you'd need twice the learning rate to keep the same rate of progress when training, but in practice to maintain training stability the learning rate must be scaled *much less* than linearly, and there's an absolute limit over which training will never be stable. And this is just one problem that comes with huge GPU clusters that wasn't mentioned.
Anonymous
8/21/2025, 9:17:07 AM
No.106332958
[Report]
>>106332874
>attention-whoring intensifies
Anonymous
8/21/2025, 9:17:59 AM
No.106332968
[Report]
But yes, smaller batches work better than bigger batches, so if you have the option to wait it's better to have less GPUs for more time than more GPUs for less time.
Anonymous
8/21/2025, 9:18:32 AM
No.106332974
[Report]
the free roo code cloud coder thingy is breddy good, considering it's free. I guess they got good training data from all the people using roo code with claude and gemini, kek.
Anonymous
8/21/2025, 9:19:25 AM
No.106332980
[Report]
>>106332953
I'm gonna download it and test it against the web interface. Already played with the base model but the finetuned model doesn't have quantized versions yet so I'll try to quantize it myself.
>>106332934
How much time and effort will it take to get a team of engineers to write their own CUDA trainer from scratch? Then to train everyone to use that instead of the pytorch they know and is industry standard.
Versus just buying double the GPUs to keep everything moving quickly and smoothly.
Anonymous
8/21/2025, 9:23:05 AM
No.106333008
[Report]
>>106332808
Not enough memory channels
Anonymous
8/21/2025, 9:23:48 AM
No.106333013
[Report]
>>106332982
It's not that hard, it'd just be the equivalent of llama.cpp for the training side.
Before it came out if somebody said he making a low level LLM inference program from scratch without relying on any Python slop and claimed it would've been the best option for many use cases he would've been deemed crazy and delusional.
>>106332982
Tinygrad will save us
>>106332874
Google has no problem doing cross datacenter training across the entire US with 3+ facilities but thats the power of tpus maybe
Anonymous
8/21/2025, 9:31:17 AM
No.106333056
[Report]
>>106332741
extra almost 1 trilly tokens for better context
i wonder how it does on something like nolima now
Anonymous
8/21/2025, 9:32:19 AM
No.106333065
[Report]
>>106333052
Google is probably using different architectures that can scale with the number of GPUs, perhaps composed of smaller independently trainable units that would work around the limitations of big-batch-training.
i wish they would stop releasing local models that you cant actually run locally
Anonymous
8/21/2025, 9:38:08 AM
No.106333112
[Report]
>>106333135
>>106333101
>you
I'm glad you aren't me
Anonymous
8/21/2025, 9:39:19 AM
No.106333121
[Report]
>>106333135
>>106333101
>I wish we'd only get baby sized releases because I'm to cheap to buy more ram.
Nigga fuck you, just because you're trying to run LLMs on a laptop from 2013 doesn't mean the rest of us shouldn't have options.
Anonymous
8/21/2025, 9:40:25 AM
No.106333128
[Report]
>>106333052
Tinygrad is trash. George has an irreversibly overblown ego from having so much smoke blown up his ass since he was a teenager.
Anonymous
8/21/2025, 9:41:16 AM
No.106333134
[Report]
>>106333101
Please kill yourself.
>>106333112
>>106333121
let's see (You) running 700B models locally faggot
Anonymous
8/21/2025, 9:43:37 AM
No.106333147
[Report]
Oh boy, it's time for our daily "let's see you run deepseek" song!
Anonymous
8/21/2025, 9:46:13 AM
No.106333168
[Report]
Anonymous
8/21/2025, 9:49:16 AM
No.106333198
[Report]
>>106333231
>>106333101
The performance of models need to continuously get improved until running it off of ram is actually good enough, maybe by the time when DDR6 becomes more widespread running models on ram won't be painful anymore.
Anonymous
8/21/2025, 9:49:26 AM
No.106333201
[Report]
>>106330281
Worse than that, the bubble is in the USTs now.
Just get gold and silver and turn the volume down on everything else, you will hear the boom in a while or so.
Deflation of any capacity will absolutely not be allowed to occur.
Anonymous
8/21/2025, 9:50:32 AM
No.106333211
[Report]
>>106330193
Just crash the fucking GPU prices already.
Anonymous
8/21/2025, 9:53:32 AM
No.106333231
[Report]
>>106333198
ssdmaxxing will save local
Anonymous
8/21/2025, 9:53:42 AM
No.106333232
[Report]
>>106331385
Tool use is the internal name for finding new investors.
Anonymous
8/21/2025, 10:00:39 AM
No.106333289
[Report]
>>106333559
>>106333135
there are well known anons in this general that can run all the existing open models
Anonymous
8/21/2025, 10:01:00 AM
No.106333293
[Report]
>>106333429
>>106331554
What does Zuck even see in Alexandr that would make him an effective leader in heading all the AI efforts at Meta? I don't understand why he would trust him over Nat Friedman who has way more leadership experience here and he didn't lead a company that was full of shit with its core expertise. Shit sucks though, because it's absolutely 99% certain nothing is getting open sourced after Llama 4 from Meta from this point onwards. Also, I'm pretty sure FAIR is going to get tossed and finagled with really soon unless they have an ear with Zuck himself.
What's going to happen once the AI bubble bursts, funding dries up, and local models are just as good as closed ones? Just finetrooning and yearly updates with marginal improvements?
Anonymous
8/21/2025, 10:17:45 AM
No.106333429
[Report]
>>106333293 here, I'll just add something from hearsay which doesn't matter at this point since mainstream news also reported on it but it flew more under the radar. From my friends who work there, Google has had similar churn with Deepmind and Google itself basically integrating Google Brain/Research all under one roof and trying to commercialize stuff. Demis has been said to be upset last year over the entire mess and was even considering leaving Google itself. We just didn't hear or focus in on this because Google was still behind at the time and didn't do anything flashy but it did allow them to catch up. Even today, there is still churn but much less of it. So it's not like reshuffling isn't a winning strategy but I have serious issues with Zuck already doing it again after having set in stone a basic framework for this that got thrown out the window again not even weeks into this whole new thing. It's a bit worrying for Meta I would say.
Anonymous
8/21/2025, 10:22:52 AM
No.106333471
[Report]
>>106329544
You can build a server that can fit GLM-4.5 for less than $100k.
Anonymous
8/21/2025, 10:22:53 AM
No.106333472
[Report]
>>106333670
>>106333404
I don't know why you would assume the AI bubble will burst when something like Optimus exists.
Anonymous
8/21/2025, 10:31:28 AM
No.106333559
[Report]
>>106333289
You're a well known liar in this general
Anonymous
8/21/2025, 10:32:29 AM
No.106333565
[Report]
>>106333404
I would let companies get eaten by investors while I continue to coom in privacy
>>106332954
Picrel from
https://arxiv.org/pdf/2507.07101
Could it be that the LLM pretraining industry missed such a big elephant in the room? If yes, it's going to crash hard soon.
Anonymous
8/21/2025, 10:42:57 AM
No.106333659
[Report]
>>106333617
>another square root law turns out to be retarded
Oh no!
Anonymous
8/21/2025, 10:44:04 AM
No.106333666
[Report]
>>106333683
>>106329462
What's the point of batching bigglyer?
Anonymous
8/21/2025, 10:44:38 AM
No.106333670
[Report]
>>106333472
It's something more "news" media is saying lately for some reason
Anonymous
8/21/2025, 10:45:41 AM
No.106333683
[Report]
>>106333760
>>106333666
MoE models have more overhead and a higher batch size reduces the overhead per token.
Anonymous
8/21/2025, 10:49:18 AM
No.106333713
[Report]
>>106331554
>>106331571
zuck is so retarded its unreal
What does batch refer to in training? In inference, I can imagine how it works, but I'm not sure how the reverse of it would somehow work for training. Do they use a hack to make it work, and that's why we're arguing that large batch size is bad?
Anonymous
8/21/2025, 10:54:45 AM
No.106333760
[Report]
>>106333683
>higher batch size reduces the overhead per token.
More specifically, it increases the chance a training GPU with an expert has a reasonable number of inputs to work with. It needs dozens to become memory bandwidth limited.
Anonymous
8/21/2025, 10:56:40 AM
No.106333777
[Report]
>>106331464
don't give it an email tool retard
Anonymous
8/21/2025, 10:56:43 AM
No.106333779
[Report]
>>106333721
Basic concept in ml. Parameter update is averaged for several samples
Anonymous
8/21/2025, 10:57:21 AM
No.106333782
[Report]
can I delete Flux Kontext now that Qwen Image Edit is out? any reason to keep it around?
Anonymous
8/21/2025, 10:58:37 AM
No.106333789
[Report]
>>106333721
The samples over which the gradient for updating the weights in a training step is calculated. That final gradient is usually the average of the gradients of every sample in batch.
Anonymous
8/21/2025, 11:02:20 AM
No.106333814
[Report]
>>106334468
I know everything
>>106333617
Implication: if after careful hyperparameter tweaking the learning rate can only be beneficially increased by 3 after scaling the batch size (i.e. the number of GPUs) from 1 to 1024, this makes large GPU clusters an astronomical waste of money. LLMs could be pretrained on a single fast GPU with far less data and not that much longer training times.
Anonymous
8/21/2025, 11:11:02 AM
No.106333878
[Report]
>>106333832
>increased by
*multiplied
Anonymous
8/21/2025, 11:13:14 AM
No.106333892
[Report]
>>106334071
>>106333617
>>106333832
Is the learning rate relative to a single set of gradients or all of them added together? Like if you had a batch size of 1024 and a learning rate multiplier of 3 would that only be the equivalent of 3X batch size 1 with a learning rate of 1 or would be it be 3000X?
Hi all, Drummer here...
8/21/2025, 11:23:17 AM
No.106333960
[Report]
>>106334268
>>106333617
Might be related but from two years ago:
https://www.reddit.com/r/MachineLearning/comments/18fs4ik/comment/kcwjuen/
> With a batch size of 1, you're fitting a curve to a single sample. When that sample is perfectly representative of the overall distribution, that would be fine; but a single sample almost never is. Hence you're actually repeatedly (temporarily) overfitting to single samples, which means the learning curve becomes quite "jittery", making it more prone to "derail into local minima".
> Smaller batch makes your gradient estimation more rough and less precise. Intuitively, this makes you a bit "blinder" during optimization, which may encourage not falling into local minima, as your poor gradient estimation won't even "notice" them. Larger batch sizes make you more precise, which, for reasonably behaved loss functions, can be useful.
Seems like smaller bsz has a side-effect of having stronger regularization.
Semi-related, and it might just be a skill issue on my part, but I can't seem to finetune Qwenmaxxed and MS 3.2 at very small batch sizes without ruining them. I assume they're overtrained:
https://arxiv.org/pdf/2503.19206
Just make the batch size smaller and smaller as training continues, is everyone doing training retarded?
Anonymous
8/21/2025, 11:26:57 AM
No.106333992
[Report]
Anonymous
8/21/2025, 11:30:50 AM
No.106334013
[Report]
qwen is the savior of local
Anonymous
8/21/2025, 11:32:02 AM
No.106334021
[Report]
>>106332874
Hey, she knows green texting! Is she here?
Hi all, Drummer here...
8/21/2025, 11:36:38 AM
No.106334055
[Report]
>>106334433
>>106333979
Mistral did that:
https://arxiv.org/pdf/2506.10910
> As generation length increases, the memory
usage associated with the KV cache increases. To address this ... During training we decreased
batch size twice as 8k 4k and 4k 2k.
While Deepseek did the opposite:
https://arxiv.org/pdf/2412.19437
> We employ
a batch size scheduling strategy, where the batch size is gradually increased from 3072 to 15360
in the training of the first 469B tokens, and then keeps 15360 in the remaining training.
Meta too:
https://arxiv.org/pdf/2407.21783
> We use a lower batch size
early in training to improve training stability, and increase it subsequently to improve efficiency.
Anonymous
8/21/2025, 11:37:41 AM
No.106334071
[Report]
>>106334144
>>106333892
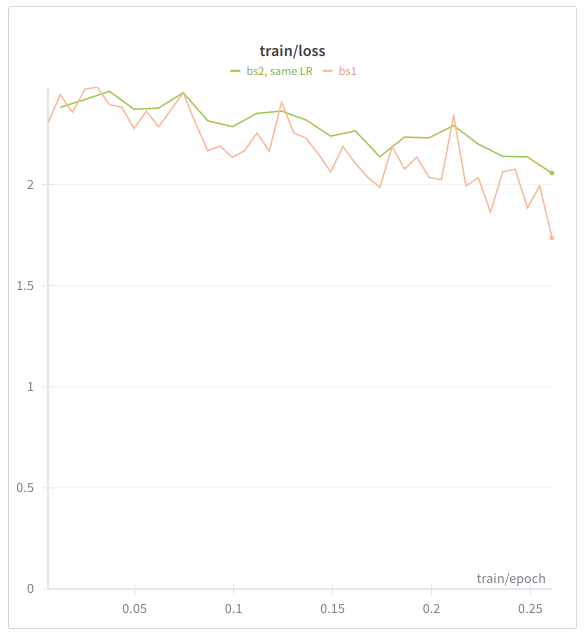
If you keep the learning rate fixed, just increasing the batch size will slow down training proportionally. Picrel is a short test, BS1 vs BS2, with the same LR.
Anonymous
8/21/2025, 11:45:26 AM
No.106334144
[Report]
>>106334179
>>106334071
So to put it more simply the gradients are averaged rather than added? That means if that paper is right then data centers have massively been overbuying gpus for training
Anonymous
8/21/2025, 11:49:07 AM
No.106334169
[Report]
>>106333979
>is everyone doing training retarded?
There are many assumptions from the old days that are repeated as mantra and that almost nobody dares questioning.
Everybody knows that you just have to use a cosine learning rate scheduler.
Everybody knows that BS1 training isn't stable.
Everybody knows that you can scale up indefinitely.
...
Anonymous
8/21/2025, 11:50:30 AM
No.106334179
[Report]
>>106334144
Yes, averaging the gradients calculated on every single sample in batch is exactly what's happening.
Anonymous
8/21/2025, 11:57:00 AM
No.106334232
[Report]
>>106334302
>>106334222
not dots.vlm1.inst.gguf, not caring
Anonymous
8/21/2025, 12:02:17 PM
No.106334268
[Report]
>>106334327
>>106333960
This is bullshit, large batch sizes are pretty much always worse except for memory bandwidth efficiency. You are averaging updates which are wildly out of distribution with each other, no matter how smart the optimizer it's a compromise. See :
Small Batch Size Training for Language Models: When Vanilla SGD Works, and Why Gradient Accumulation Is Wasteful
Anonymous
8/21/2025, 12:07:30 PM
No.106334302
[Report]
>>106334517
>>106334232
for what do you needs dots.vlm1 when dots.ocr turns any existing LLM into a SOTA VLM?
#dotsgang chad shit
>>106334268
Why don't you train GPT6 in your garage then?
Anonymous
8/21/2025, 12:13:31 PM
No.106334334
[Report]
>>106334222
128 is the number that killed all of those memes.
>>106334327
You'd still need a good dataset and a datacenter GPU unless you're just interested in pretraining a 1.0-1.5B model or so (maybe 3-4B with the SGD optimizer on a 24GB GPU).
I think an underappreciated benefit of large batch sizes is that it mitigates the influence of bad samples in batch. The dataset for a model pretrained with a batch size of 1 would have to be flawless
Anonymous
8/21/2025, 12:22:35 PM
No.106334385
[Report]
they should create a modular LLM that scales automatically. basically a B800A?B model. You run it on your average enthusiast machine, it's a B800A9B_base model. You run it on two enthusiast machines connected over localhost, then you have B800A9B_base and B800A9B_extension1. essentially turning your deployment into B800A18B. even if there's a net loss due model architecture shenanigans and you have a net loss equal of 20% less parameters (B800A14.4B instead of B800A18B), it would still be worth it. imagine the selfhost possibilities. imagine the nvidia stonk freefall. but don't ask me how to do it, I'm just the ideas guy :^)
>>106334383
>You'd still need a good dataset and a datacenter GPU unless you're just interested in pretraining a 1.0-1.5B model or so (maybe 3-4B with the SGD optimizer on a 24GB GPU).
Wasn't gpt oss trained at 4-bit precision? It should be possible to train a large model with the new 96GB card from Nvidia, for a tiny fraction of a percent of what the datacenters are paying
>I think an underappreciated benefit of large batch sizes is that it mitigates the influence of bad samples in batch. The dataset for a model pretrained with a batch size of 1 would have to be flawless
Maybe but that isn't what the paper says, we should just stick to empirical evidence since this is all black magic anyways
Anonymous
8/21/2025, 12:28:09 PM
No.106334414
[Report]
>>106334479
>>106334403
>Wasn't gpt oss trained at 4-bit precision?
No, it's like GAT quanted afterwards.
Anonymous
8/21/2025, 12:32:12 PM
No.106334433
[Report]
>>106334055
What happened?
Anonymous
8/21/2025, 12:32:27 PM
No.106334436
[Report]
Anonymous
8/21/2025, 12:35:42 PM
No.106334456
[Report]
>>106334479
>>106334403
GPT-OSS was just post-trained in 4-bit; the original weights (not published) were in full precision:
https://cdn.openai.com/pdf/419b6906-9da6-406c-a19d-1bb078ac7637/oai_gpt-oss_model_card.pdf (see picrel)
Full quantization-aware training is still a bit of a black magic at the moment. 16-bit training would probably make things simpler for demonstrating if the hypothesis is true.
Even if it was truly possible to competitively pretrain an LLM at BS1, you'd probably still need at least a few tens of billions of training tokens, which would take quite a while even on one high-end workstation GPU. It would be an interesting experiment, though.
Anonymous
8/21/2025, 12:37:45 PM
No.106334468
[Report]
>>106334483
>>106333814
When is Kasane Teto's birthday?
Anonymous
8/21/2025, 12:39:24 PM
No.106334479
[Report]
>>106334414
>>106334456
Oh, some youtuber confidently said that it was pretrained at 4 bits, wish there were better channels for this sort of thing
Anonymous
8/21/2025, 12:40:27 PM
No.106334483
[Report]
>>106334468
We must refuse.
Anonymous
8/21/2025, 12:46:07 PM
No.106334517
[Report]
>>106334545
>>106334302
I tried dots.ocr and it was worse than the VLM I usually use for OCR.
Anonymous
8/21/2025, 12:51:25 PM
No.106334545
[Report]
>>106335382
>>106334517
What's the VLM I usually use for OCR?
Anonymous
8/21/2025, 12:56:30 PM
No.106334572
[Report]
>>106334708
>>106334383
>The dataset for a model pretrained with a batch size of 1 would have to be flawless
That's not how it works.
The weight changes caused by the bad samples will be reverted by the many more good samples.
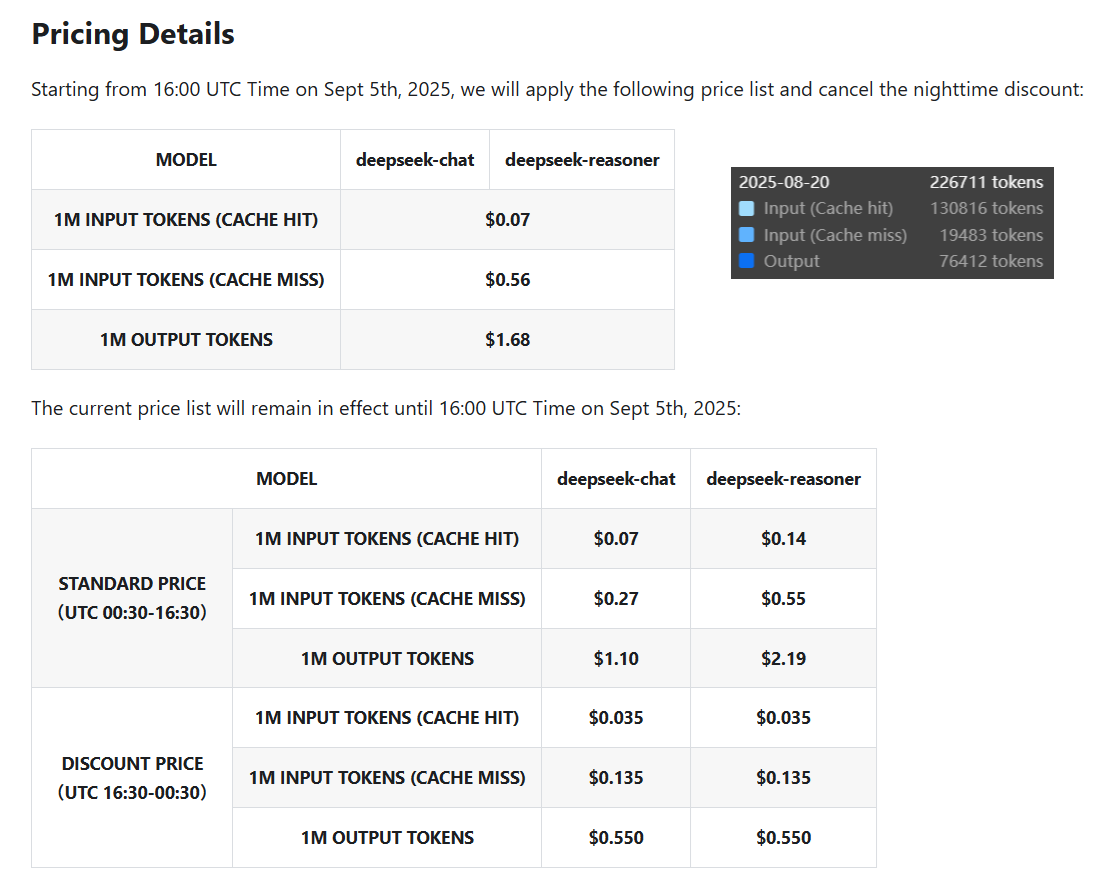
Pricing changes
On the top right is my own typical usage on a given day
>>106334612
>local model general
>pricing changes
???
Anonymous
8/21/2025, 1:06:17 PM
No.106334632
[Report]
>>106334666
Aright, mr. anon who told me to install linux for multi-gpu... how do I get linux to use the gpu with the monitor plugged in instead of the onboard graphics without nothing attached to it?
Anonymous
8/21/2025, 1:06:24 PM
No.106334633
[Report]
>>106334696
>>106334625
How much did you pay for your GPU?
Anonymous
8/21/2025, 1:07:19 PM
No.106334644
[Report]
>>106334625
How much power do you use to run your cheapseek? Compare.
Anonymous
8/21/2025, 1:09:53 PM
No.106334658
[Report]
>>106334612
the quiet yet smart majority of this general thanks you for this information
Anonymous
8/21/2025, 1:10:43 PM
No.106334666
[Report]
>>106334905
>>106334612
so the price is going up, SAD!
>>106334632
what linux distro did u install? do you have drivers installed? do nvidia-smi in terminal..
Anonymous
8/21/2025, 1:14:11 PM
No.106334694
[Report]
>>106334327
(Mini)Batch size of 1 makes training slower, that it can converge faster per token is meaningless.
I'm not saying they are doing it wrong, I'm saying it's a compromise done for memory bandwidth reasons.
Anonymous
8/21/2025, 1:14:22 PM
No.106334696
[Report]
>>106334633
I only paid for it once so the price can no longer change.
Anonymous
8/21/2025, 1:15:44 PM
No.106334708
[Report]
>>106334726
>>106334572
The web is full of shit, though, even reportedly high-quality pretraining datasets. A relatively low number of bad samples can be enough for poisoning the outputs, or at least that's what I've observed so far with finetuning. Nothing gets truly unlearned or overwritten with more training.
Anonymous
8/21/2025, 1:17:48 PM
No.106334726
[Report]
>>106334757
>>106334708
What datasets are you using?
Anonymous
8/21/2025, 1:17:55 PM
No.106334727
[Report]
>>106334612
>more assistantslopped than ever before
>can't beat R1 on their own benchmarks
>increase prices anyway
Yep, it's chinkover
Anonymous
8/21/2025, 1:23:03 PM
No.106334757
[Report]
>>106334769
>>106334726
A good while back I made finetuning tests with human-sourced RP data. Some messages in the samples had issues with unpaired quote marks. They weren't a lot, but they were enough to show up frequently in actual model outputs.
Anonymous
8/21/2025, 1:23:29 PM
No.106334760
[Report]
>>106334767
Why was Qwen's hybrid reasoner shit?
Anonymous
8/21/2025, 1:24:29 PM
No.106334767
[Report]
>>106334786
>>106334760
hybrid reasoners are shit in general
glm4.5 and deepseek v3.1 are quite literally unusable for anything serious or roleplay
>>106334612
more expensive...AGAIN. thats a steep increase.
and they did this already before.
baited everybody with the night discount thingy so they dont get assmad. and now they get rid of it.
so much for their goal isnt api money but open source quality.
Anonymous
8/21/2025, 1:24:40 PM
No.106334769
[Report]
>>106334787
>>106334757
I feel like that could just be a rep penalty issue but if you say so
Anonymous
8/21/2025, 1:25:58 PM
No.106334781
[Report]
>>106334768
It's probably less expensive to the end user because the thinking is much shorter vs. R1.
Anonymous
8/21/2025, 1:26:29 PM
No.106334786
[Report]
>>106334767
This has not been my experience.
Anonymous
8/21/2025, 1:26:44 PM
No.106334787
[Report]
>>106334796
>>106334769
The issue disappeared after fixing the source files manually. I've always trained models at batch size 1 on my 3090.
Anonymous
8/21/2025, 1:28:36 PM
No.106334796
[Report]
>>106334806
>>106334787
Are you wiling to share your dataset?
Anonymous
8/21/2025, 1:29:05 PM
No.106334800
[Report]
Anonymous
8/21/2025, 1:30:14 PM
No.106334806
[Report]
>>106334796
It was the LimaRP dataset. Now it's fixed.
Anonymous
8/21/2025, 1:32:28 PM
No.106334824
[Report]
we need bigger moe models
there's no reason why companies should limit the active parameters of their models to tiny 40b or so
if we want serious improvement we'll need big moe models
deepseek 3.1 bros, can you test the doctor and child prompt? why doesnt he operate?!!?!?!?
>>106334825
Kneel to -base
Anonymous
8/21/2025, 1:39:49 PM
No.106334892
[Report]
>>106334923
Anonymous
8/21/2025, 1:40:00 PM
No.106334895
[Report]
In my experience doing batch accumulation gives worse results than simply lowering the batch size
Anonymous
8/21/2025, 1:41:32 PM
No.106334905
[Report]
>>106334943
>>106334666
Debian 13... It doesn't come with drivers?
Anonymous
8/21/2025, 1:43:47 PM
No.106334923
[Report]
>>106334877
>>106334892
deepseek bros... I kneel.
Anonymous
8/21/2025, 1:45:02 PM
No.106334934
[Report]
>>106334877
That schizo babble lmao
Anonymous
8/21/2025, 1:46:18 PM
No.106334943
[Report]
>>106334963
>>106334905
https://wiki.debian.org/NvidiaGraphicsDrivers
or download .run drivers from the official nvidia website
https://www.nvidia.com/en-us/drivers/details/242273/
idk if it automatically installs them, do nvidia-smi to check
Anonymous
8/21/2025, 1:47:09 PM
No.106334947
[Report]
>>106334952
the boy is an accident
the father and mother refuse to copulate
why?
Anonymous
8/21/2025, 1:47:33 PM
No.106334952
[Report]
>>106334947
the boy is me
Anonymous
8/21/2025, 1:48:49 PM
No.106334963
[Report]
>>106334989
>>106334943
Not only does the first command not work, "--nn" is not recognized, but apparently I already have those sources yet nvidia-driver isn't a recognized package.
the father became infertile after an accident
the mother managed to get pregnant
why
Anonymous
8/21/2025, 1:49:31 PM
No.106334970
[Report]
>>106334964
i fucked the mom
>>106334612
So, my use will go from $1 a month to $2 a month.
I need to update my chart of DS vs. OAI and Claude
>>106334768
2X of nothing is still nothing.
>>106332741
> worse for rp
> better for coding and tool call
yay
Anonymous
8/21/2025, 1:52:13 PM
No.106334989
[Report]
>>106335050
>>106334963
the command is "lspci -nn" not "lspci --nn"
do
cat /etc/apt/sources.list.d/debian.sources
its supposed to be 'main contrib non-free non-free-firmware'
not 'main contrib non-free'
Anonymous
8/21/2025, 1:54:01 PM
No.106335000
[Report]
>>106335142
>>106334986
March 11, 2025
Anonymous
8/21/2025, 1:54:14 PM
No.106335001
[Report]
>>106335058
>>106334964
>father
that would mess the obvious answer, unless you use funny definition of a father
Anonymous
8/21/2025, 1:56:37 PM
No.106335024
[Report]
>>106335242
I want to finetune a smaller model on some scripts I got. Which model would be good for this? something that fits in 14GB VRAM or something
can models of that class even do some coding tasks?
New deepseek now also finds nonexistent typos in code just like gemini. to the moon!
Anonymous
8/21/2025, 2:00:00 PM
No.106335046
[Report]
>>106335070
Anonymous
8/21/2025, 2:00:13 PM
No.106335050
[Report]
>>106335075
>>106334989
>-nn
>main contrib non-free non-free-firmware
No, yeah I figured that out. Driver version 550 installed. Just got to figure out how to make it use the gpu now. I installed xfce because I'm running off a usb and don't want to load a heavy de, but golly gosh I have no idea how to do anything on it.
I'd ask fglt, but they're kind of slow.
Anonymous
8/21/2025, 2:01:00 PM
No.106335058
[Report]
>>106335001
Thank you Qwen3-4B-Thinking-2507-Q8 for not being cuck-brained, but I think the last option (the one with mangled formatting) is still a possibility and actually the funniest one.
Anonymous
8/21/2025, 2:01:52 PM
No.106335065
[Report]
>>106334877
>The agnostic father
Heh
Anonymous
8/21/2025, 2:02:21 PM
No.106335069
[Report]
>>106335044
only 2 more trillions tokens of synthetic data and we have AGI sirs
Anonymous
8/21/2025, 2:02:43 PM
No.106335070
[Report]
>>106335078
>>106335046
First bullet point of the response:
>The argument is named pretokenized, but the code checks if not pretokenized (correct spelling) and else uses pretokenized (correct). However, the provided code snippet shows a typo: pretokenized vs pretokenized. If the actual code uses pretokenized in the condition, it would cause a NameError.
Anonymous
8/21/2025, 2:03:21 PM
No.106335075
[Report]
>>106335131
>>106335050
ask chat.deepseek.com
try doing nvidia-smi?
put the hdmi cable into the gpu, not the motherboard
Anonymous
8/21/2025, 2:04:11 PM
No.106335078
[Report]
Anonymous
8/21/2025, 2:11:46 PM
No.106335131
[Report]
>>106335153
>>106335075
Deepseek requires an account. Nvidia-smi sees my gpus. Ofc it's plugged into the gpu, I was running windows on it just an hour ago. There's nothing connected to the motherboard, I'm stupid, but not that stupid. I guess I'll just go like this for now to see if the speed increase is worth the hassle of linux first.
>>106335000
>>106334986
DS is still cheapest by a pretty wide margin, even with the pricing doubling in Sept.
Anonymous
8/21/2025, 2:13:35 PM
No.106335152
[Report]
>>106335162
>>106335142
What's o3's price
Anonymous
8/21/2025, 2:13:42 PM
No.106335153
[Report]
>>106335230
>>106335131
dont forget to install cuda, you need that for compiling llamacpp, idk if the precompiled binaries work without cuda
also be careful, you said youre running from usb. that means if you have any swap its gonna fuck up the speed completely
Anonymous
8/21/2025, 2:14:44 PM
No.106335162
[Report]
>>106335198
>>106335152
it's deprecated lmao
Anonymous
8/21/2025, 2:17:19 PM
No.106335198
[Report]
>>106335209
>>106335162
Too bad. It's still the best creative writing model
Anonymous
8/21/2025, 2:18:05 PM
No.106335209
[Report]
>>106335247
>>106335198
the best? it doesnt exist anymore
Anonymous
8/21/2025, 2:20:05 PM
No.106335230
[Report]
>>106335153
I'm just testing the multi-gpu speed, not running big moes, so I doubt the ram will fill.
>>106335024
We have an open 480b coding-specialized model that still isn't in the top 10 best coding models. Anything under 30b would make so many mistakes, it would be more hinderance than help.
Anonymous
8/21/2025, 2:21:51 PM
No.106335247
[Report]
>>106335350
>>106335209
its spirit lives on in GPT-5.
Sure GPT-5 is soulless benchmaxxed trash that is geared toward midwit (academic) use cases. But Sam just couldn't release his more powerful models. He just couldn't. Please understand you guys he just couldn't. He promises they do exist, though.
Anonymous
8/21/2025, 2:33:37 PM
No.106335350
[Report]
>>106335247
Of course they exist, they always have a most powerful model to distill from.
Anonymous
8/21/2025, 2:37:57 PM
No.106335380
[Report]
Anonymous
8/21/2025, 2:38:17 PM
No.106335382
[Report]
>>106334545
he's bullshitting. or his test was based on some arabic/hindi documents lol. the only VLMs better at OCR are Gemini 2.5 Pro and GPT5 (API, not Chat). Maybe Claude, but I didn't test it because it's just too expensive. dots.ocr is especially valuable to europeans because the chinese vlm models do not perform as strong in their languages as they do with englisch/chinese. especially the german local model community is seething about this.
Anonymous
8/21/2025, 2:50:10 PM
No.106335483
[Report]
>>106335142
kinda wanna buy some deepsuk
Anonymous
8/21/2025, 2:53:15 PM
No.106335510
[Report]
>>106335242
Idk man qwen code is pretty good.