/lmg/ - Local Models General
Anonymous
8/21/2025, 9:14:28 PM
No.106338945
[Report]
sex with migu (the poster)
►Recent Highlights from the Previous Thread:
>>106335536
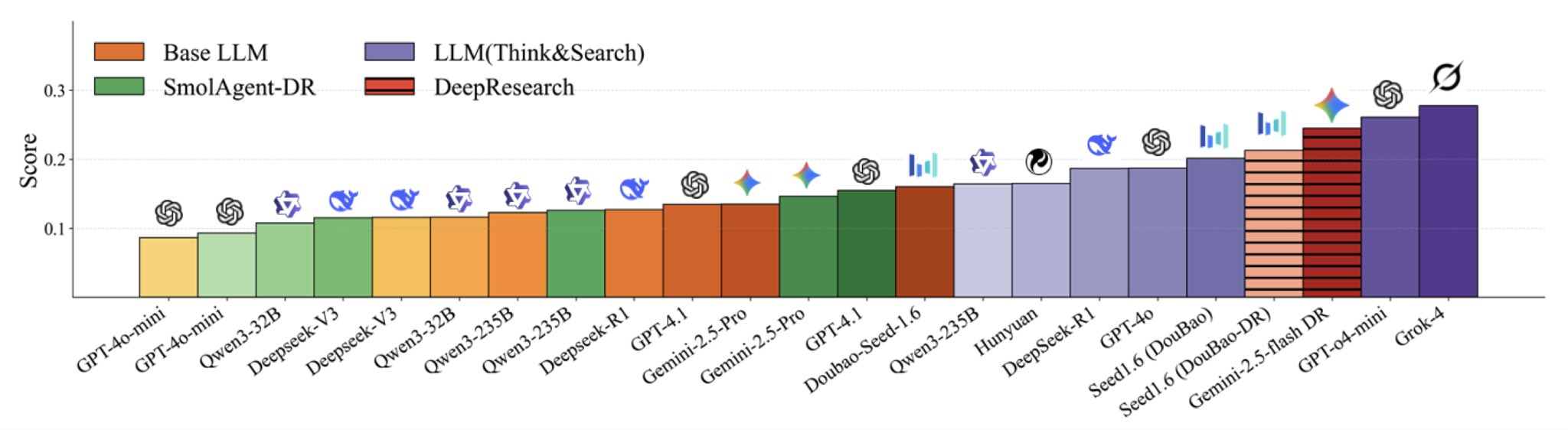
--Optimizing GLM-4.5 MoE inference speed via quant and offload tuning in llama.cpp:
>106335633 >106335669 >106335686 >106335702 >106335719 >106335721 >106335704 >106335823 >106336163 >106336177 >106336221 >106336229 >106336236 >106336398
--dots.ocr preprocessing essential for accurate document understanding in local models:
>106338159 >106338172 >106338188 >106338181 >106338215 >106338210 >106338337 >106338374 >106338523 >106338576 >106338590
--Cohere's new 256K reasoning model faces skepticism over licensing and safety alignment:
>106336632 >106336642 >106336651 >106336656 >106336675 >106336680 >106336692 >106336690 >106336733 >106336750 >106336775 >106336818 >106336861 >106336737 >106336758 >106336923 >106337358 >106337460 >106337748 >106337789 >106337814 >106337848 >106337871
--New 3.1 model criticized for blandness and overfitting on synthetic safety data:
>106336831 >106336893 >106336909 >106336979 >106337037 >106337046 >106337093 >106337128 >106337099 >106337246 >106336996 >106337236 >106337264 >106336977 >106337079 >106337003 >106338206
--Linux vs Windows power reporting and inference efficiency on RTX 3090:
>106336491 >106336561 >106336576 >106336655 >106336874 >106336990 >106337011 >106337060 >106336671
--GPT-5 inflated EQ-Bench scores by ignoring word limit prompts:
>106335810
--Skepticism toward NVIDIA's AI roadmap and social media hype around small model agents:
>106337495 >106337644 >106337664 >106337510 >106337570 >106337595 >106337614 >106337665 >106337728 >106337732 >106338079 >106337772 >106337818 >106337918 >106337963 >106338350 >106338382 >106338412 >106338500
--UE8M0 FP8 as a new data format for upcoming Chinese AI chips:
>106337941 >106337976 >106338002 >106338175 >106338316
--Miku (free space):
>106336448
►Recent Highlight Posts from the Previous Thread:
>>106335541
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
8/21/2025, 9:15:24 PM
No.106338959
[Report]
>>106338980
>>106338905
your launch command and system specs perhaps?
>>106338959
It's related to --mlock command but that's all what I know. Everything should fit into my memory.
Never mind, I'll just do whatever I've been doing because after all these hours I've never seen anything strange.
Also:
>draft acceptance rate = 0.34615 ( 18 accepted / 52 generated)
Not sure if it's really worth using draft. Testing Gemma3 270m.
Anonymous
8/21/2025, 9:17:39 PM
No.106338981
[Report]
>>106339005
Anonymous
8/21/2025, 9:19:45 PM
No.106339003
[Report]
>>106339058
>>106338980
Gemma3 270m is made out of almost entirely different dataset than it's bigger counterparts, so using it as a draft model won't do much good.
>>106338981
script to enable links?????? I dont wanna write my own???? HELLOOOO?????
Anonymous
8/21/2025, 9:20:40 PM
No.106339011
[Report]
>>106339029
Anonymous
8/21/2025, 9:22:18 PM
No.106339029
[Report]
>>106339033
>>106339011
holy based thangks :D
Anonymous
8/21/2025, 9:22:59 PM
No.106339033
[Report]
>>106339037
Anonymous
8/21/2025, 9:23:37 PM
No.106339037
[Report]
>>106339033
I fight the system
Anonymous
8/21/2025, 9:26:31 PM
No.106339058
[Report]
>>106339003
I see. I'll go fetch some new ones.
>>106338980
I used 4B Gemma as a draft model and didn't see any speed boost vs just sticking more layers of the main 27B model into VRAM. Maybe a vramlet issue on my part, but even if you have spare VRAM, won't it be better to use larger model at this point anyway?
Anonymous
8/21/2025, 9:27:41 PM
No.106339069
[Report]
>>106339095
>>106338913 (OP)
>cohere not in news
Is this a political statement?
What are the political implications of John not quanting the free world top performing open weights model GPT-OSS?
Anonymous
8/21/2025, 9:29:18 PM
No.106339088
[Report]
>>106339104
>>106339082
It's already quanted retard
Anonymous
8/21/2025, 9:29:34 PM
No.106339092
[Report]
>>106339082
wow a picture of ((ME))
Anonymous
8/21/2025, 9:29:48 PM
No.106339094
[Report]
>>106339117
>>106339061
There's probably an optimal proportion between the size of the main model and the draft model.
Something like the draft model being smaller than 10% of the main model's size or whatever.
Anonymous
8/21/2025, 9:29:55 PM
No.106339095
[Report]
>>106339069
>maxbenchcuckedmodel
why?
Anonymous
8/21/2025, 9:30:18 PM
No.106339100
[Report]
>>106339116
why is meta sitting on behemoth if it's a flop, anyways? shouldn't they have nothing to lose from posting the weights?
Anonymous
8/21/2025, 9:30:26 PM
No.106339102
[Report]
>>106339082
there's no full precision gpt-oss available no? they did the mxfp4 meme soooo well?
Anonymous
8/21/2025, 9:30:47 PM
No.106339104
[Report]
>>106339088
1. How do you know that? Did you use it?
2. Who cares it is already quanted?
Anonymous
8/21/2025, 9:31:43 PM
No.106339116
[Report]
>>106339247
>>106339100
>nothing to lose
They're a publicly traded company bro.
Anonymous
8/21/2025, 9:32:05 PM
No.106339117
[Report]
>>106339183
>>106339094
>>106339061
This is what SuperIntelligence says about this topic.
>>106338934
>Closed source models do not support PDFs out of the box either, unless you mean their associated services, which are not themselves models but scaffolding around models. That other software is what is translating your PDF into a format that models like VLMs can read.
which is almost always an image. if the open source model or it's official adapter/platform supports pdf file input, it's always worth trying. They could be doing optimization during the pdf-image conversion specifically for their model, which I'm not aware of when converting my pdf file to an image. If I upload a pdf and get the same, incorrect answer when testing with the image version of said pdf, it's safe to assume the problem does not lie within the uploaded file type. meanwhile dots.ocr doesn't care and just gives me perfect results, no matter if pdf or png.
Anonymous
8/21/2025, 9:37:58 PM
No.106339183
[Report]
>>106339215
Anonymous
8/21/2025, 9:41:09 PM
No.106339215
[Report]
>>106339239
>>106339183
how is it useless
>>106336933
>Hundreds of thousands of Grok chats exposed in Google results
A reminder why you should use local
Anonymous
8/21/2025, 9:44:00 PM
No.106339239
[Report]
>>106339215
you obviously haven't used it if you don't know. go run K2 and use this as a draft model, tell me how much slower it makes it for you. i went from 8tks to 3tks regardless of what sampler settings and what prompt i used. repetitive tasks such as coding were just as slow as well.
Anonymous
8/21/2025, 9:44:39 PM
No.106339244
[Report]
>>106339234
To be fair grok is the top of the cancer pyramid. It is both malicious and incompetent.
Anonymous
8/21/2025, 9:44:59 PM
No.106339247
[Report]
>>106339116
can they tax writeoff a large language model? they're apparently not using it themselves.
Anonymous
8/21/2025, 9:49:49 PM
No.106339304
[Report]
>>106339317
>>106339260
im gay too does that make me gayer than openai and grok
Anonymous
8/21/2025, 9:50:54 PM
No.106339317
[Report]
>>106339304
depends if you're a feminine anon or a big fat hairy bear
Is core count or cache size more important in a CPUmaxxing cpu?
Anonymous
8/21/2025, 9:52:51 PM
No.106339335
[Report]
Anonymous
8/21/2025, 9:54:42 PM
No.106339349
[Report]
>>106340642
>>106339162
It is extremely unlikely that any optimizations, beyond workarounds for resolution constraints for certain VLMs, are needed or even beneficial, given that VLMs are literally trained, like LLMs, to be general. If you have Chrome then you already own an optimized PDF to image converter.
>it's safe to assume the problem does not lie within the uploaded file type
And knowing this is not relevant to the thread. Local users either have software that does its own thing, unrelated to any online service, when given a non-image file, or they just take a screenshot and give it to the VLM. I get you want to shill for dots, but it is sufficient to just say that it works much better for images than other alternatives you've tried. Dots.ocr is still a VLM and does not read PDF files in binary or whatever, the software/service you're using is turning that PDF into an image and then feeding it to the model.
Anonymous
8/21/2025, 9:56:18 PM
No.106339362
[Report]
>>106339610
>>106339326
core count yes, cache size not much
Anonymous
8/21/2025, 9:59:46 PM
No.106339403
[Report]
>>106339427
>>106339005
Just ask GLM-chan to write it for you.
Anonymous
8/21/2025, 10:01:50 PM
No.106339427
[Report]
>>106339440
>>106339403
You know what, someone should make an anime girl mascot for GLM and then continuously force their shitty gens on the general.
Anonymous
8/21/2025, 10:02:10 PM
No.106339432
[Report]
>>106339441
>>106339260
it was funnier when meta did it
Anonymous
8/21/2025, 10:02:40 PM
No.106339440
[Report]
>>106339427
when glm guys make imagen model
Anonymous
8/21/2025, 10:02:44 PM
No.106339441
[Report]
>>106339432
lmao good times
Anonymous
8/21/2025, 10:04:12 PM
No.106339458
[Report]
>>106339061
I think using draft model benefits when you have a gigantic model. It's not really that worth when using small shitty models in 20-30B range.
Anonymous
8/21/2025, 10:05:20 PM
No.106339472
[Report]
>>106339518
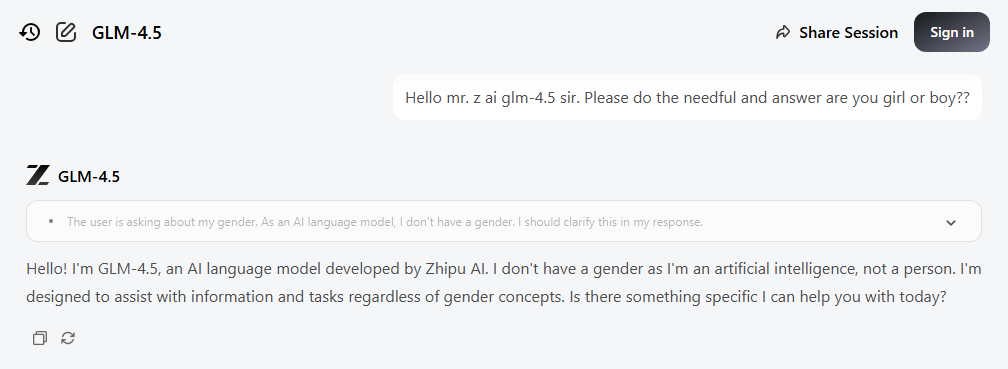
I asked GLM-chan if it's a boy or a girl in different ways, and it usually picked female.
Anonymous
8/21/2025, 10:05:31 PM
No.106339474
[Report]
>>106341361
>>106339260
did someone save any of these somewhere?
Anonymous
8/21/2025, 10:10:21 PM
No.106339518
[Report]
>>106339531
>>106339472
GLM-Air loves to lecture me about menstruation, abortions and feminism in RP
Anonymous
8/21/2025, 10:11:42 PM
No.106339531
[Report]
>>106339518
needs correction
Anonymous
8/21/2025, 10:12:00 PM
No.106339536
[Report]
>>106339506
It's not that visible under normal viewing, but yeah he should be putting his images through some de-artifacting models. Or use a vectorization model since the art style is pretty cell shaded.
Anonymous
8/21/2025, 10:16:28 PM
No.106339587
[Report]
>>106339326
>>106339362
Is there a point where the CPUs are faster than the memory bandwidth and more cores doesn't matter?
>>106339610
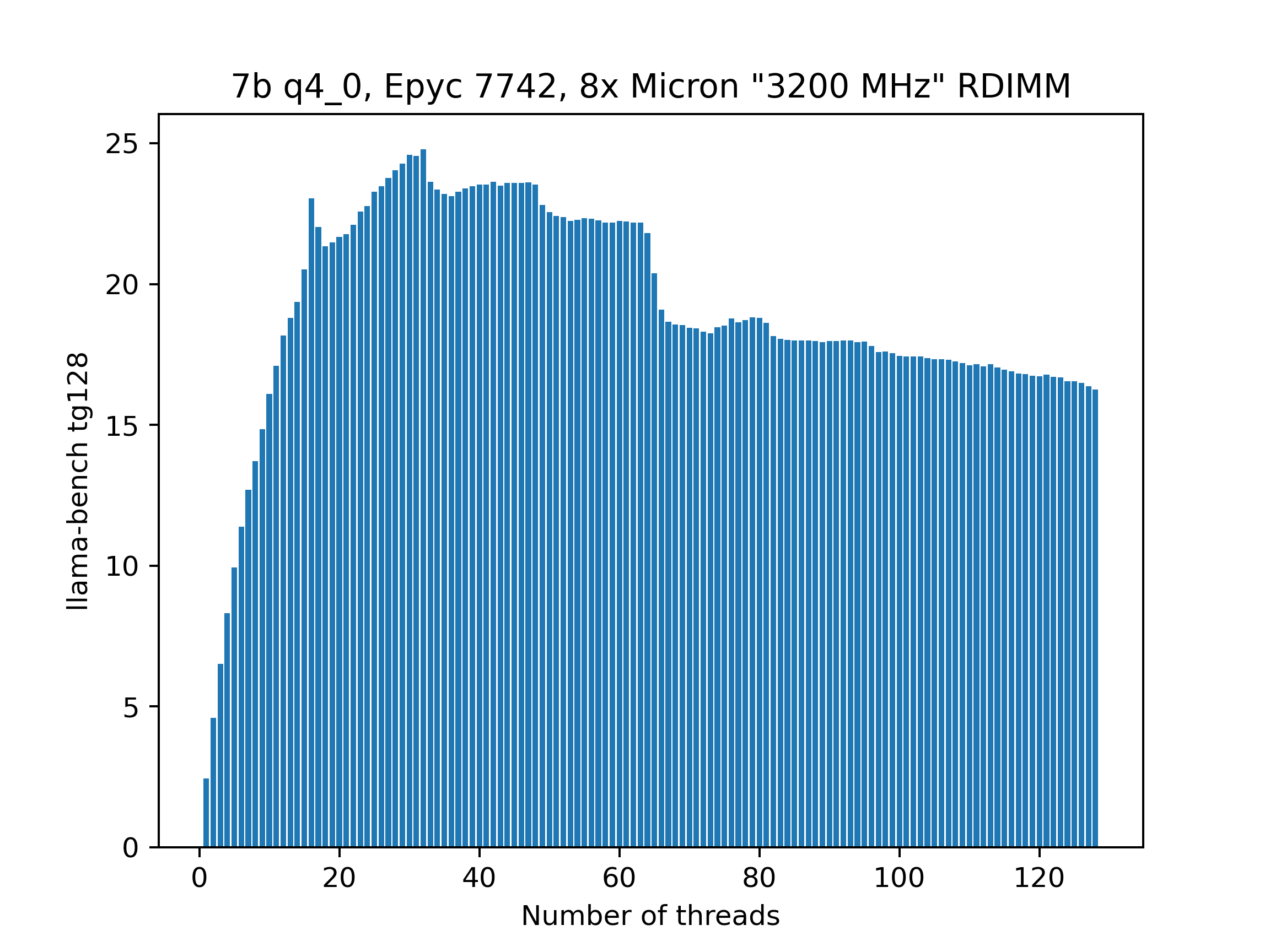
Yes, in fact at some points more cores are detrimental because they just fight over the memory bandwidth.
(Pic is a bit old but same principles should still apply.)
Anonymous
8/21/2025, 10:26:52 PM
No.106339683
[Report]
damn, rewatching plastic memories hits completely different now
>>106339668
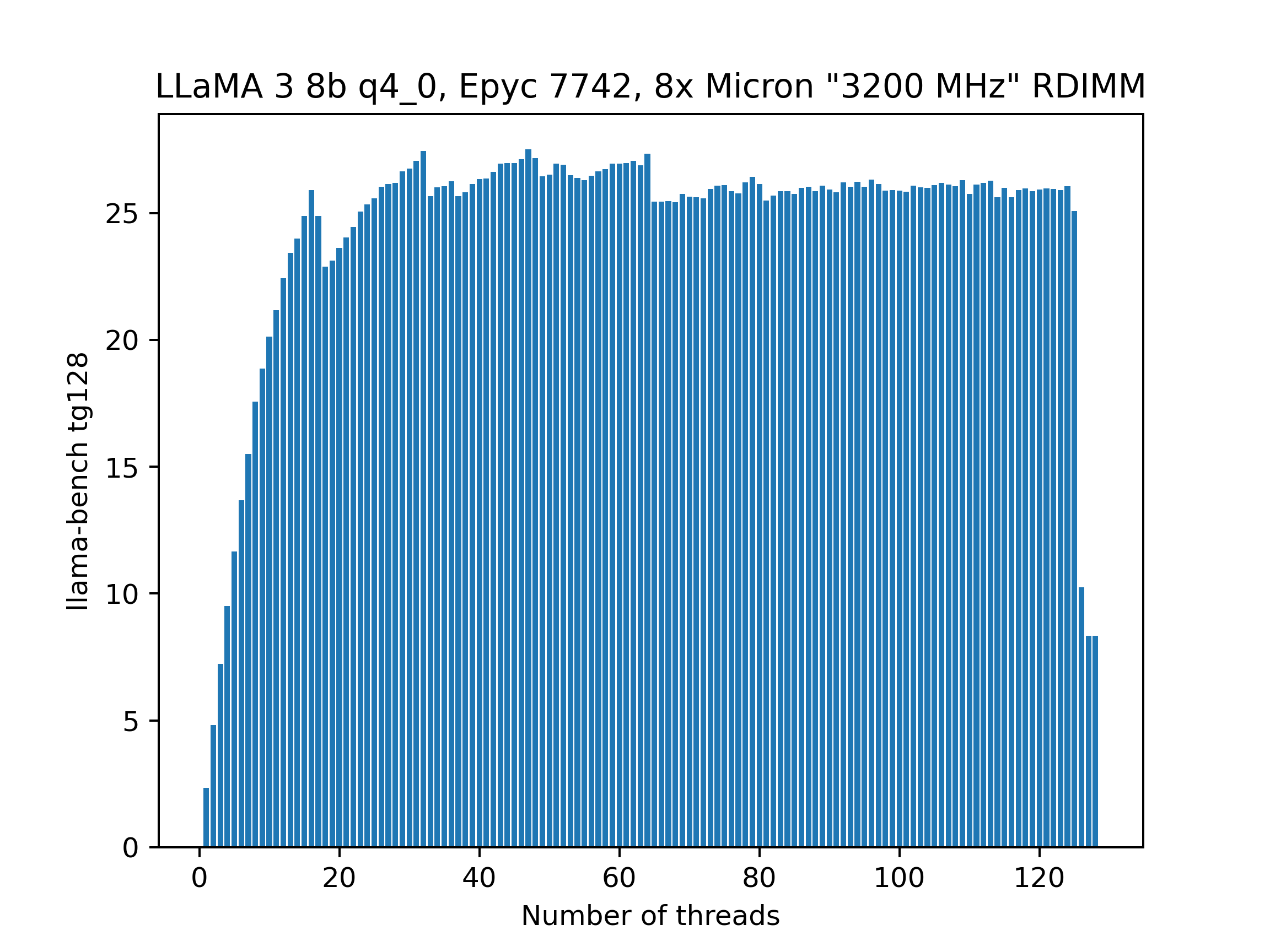
I'm trying to pick a Turin CPU to use with 12 channel DDR5-6000. The lowest end one is the 9015 with 8 cores. The beast 9755 has 128 cores. I guess I should shoot for 32?
>>106339610
When the memory bandwidth exceeds the CPU cache speed. Theoretically if you had access to 2731 EPYC 9965 CPUs you could store an entire model into L3 cache. It would only consume 1.3MW of power.
Anonymous
8/21/2025, 10:30:35 PM
No.106339708
[Report]
>>106339712
>>106339698
shoot for CCU
n..nn-nn-n-.n..--nn-n-n
Anonymous
8/21/2025, 10:31:32 PM
No.106339712
[Report]
>>106339721
Anonymous
8/21/2025, 10:31:37 PM
No.106339713
[Report]
>>106339705
Forgot to mention that many CPUs would have a tad over 1TB of L3 cache so you could Deepseek or Kimi K2 but not FP8 K2 :)
Anonymous
8/21/2025, 10:32:43 PM
No.106339721
[Report]
>>106339712
its something for memory channels
llama.cpp CUDA dev
!!yhbFjk57TDr
8/21/2025, 10:35:08 PM
No.106339740
[Report]
>>106339698
I don't know, particularly because long-term there are still NUMA optimizations to be done.
But I would say that when in doubt it's better to have too many cores than too few.
Also consider whether there are other things for which you may want to use your machine.
>>106339668
>7b q4
>25t/s
Damn cpumaxxing is worse than I thought.
Anonymous
8/21/2025, 10:37:37 PM
No.106339760
[Report]
>>106339782
>>106339705
>you could store an entire model into L3 cache
I don't think it works that way, I'm pretty sure cores need to talk to each other
>>106339668
8 channel?!
25t/s?!?!?!?!?
what hte fuck
Anonymous
8/21/2025, 10:40:19 PM
No.106339782
[Report]
>>106339760
Screw that, do it over network. Pass the current state required for computation from CPU to CPU over fiber. It will be a complete waste of compute but it would allow for the worst experience to happen concurrently on 2731 CPUs at a time.
>>106339668
>>106339752
it's not looking good for cpumaxxing moesissies...
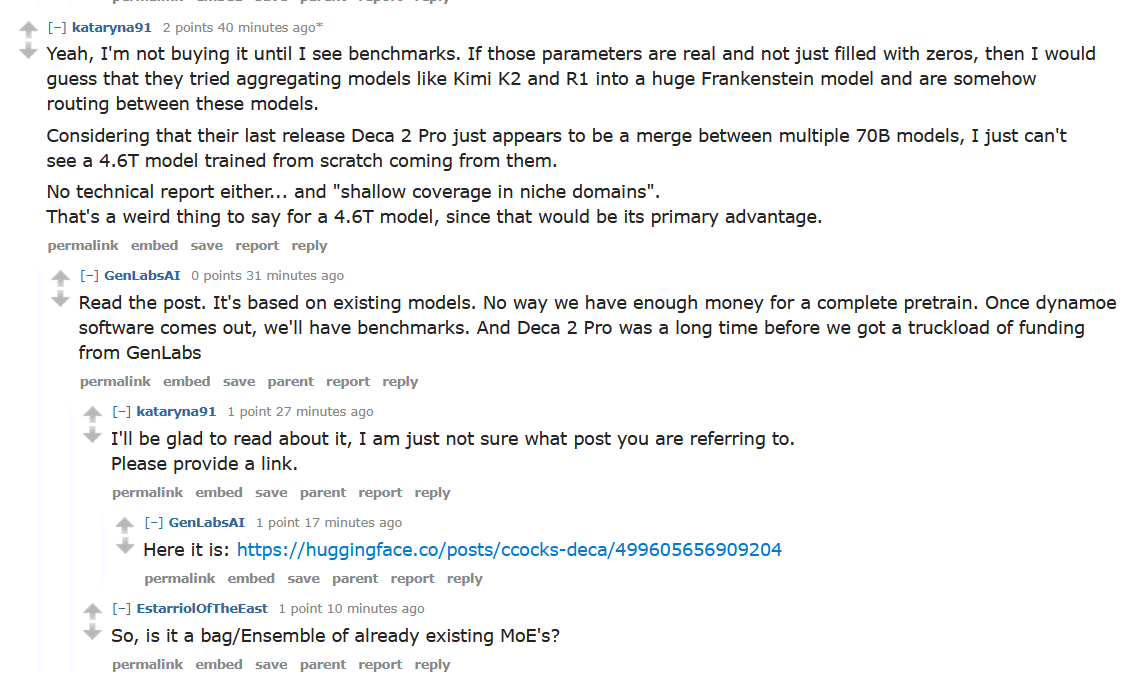
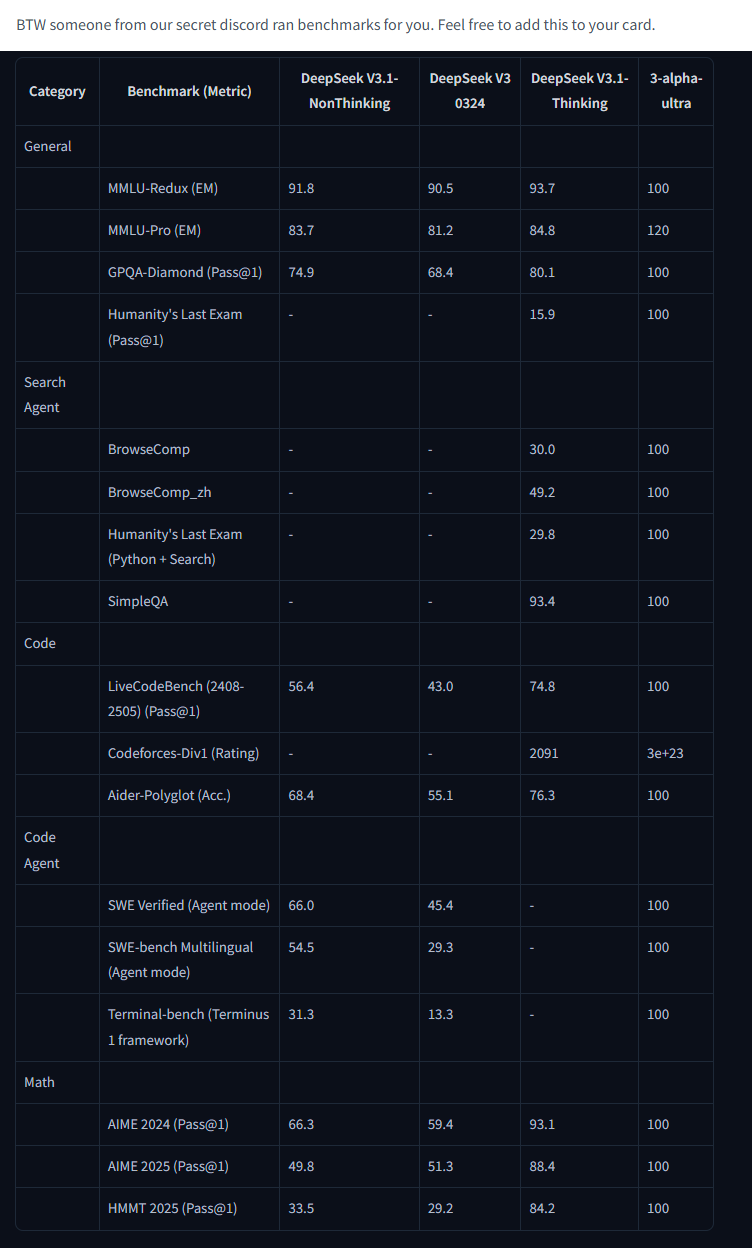
A new size king has released. 4.6T dynamic (?) MoE. Safety concerns? They exist, read the outputs. Privacy? Don't put private information in. This might be the most based model release in a while.
https://huggingface.co/deca-ai/3-alpha-ultra
Anonymous
8/21/2025, 10:54:16 PM
No.106339902
[Report]
>>106339878
>4.6T
this is getting ridiculous. soon not even cpumaxxing will be enough
Anonymous
8/21/2025, 10:54:30 PM
No.106339903
[Report]
>>106340235
>>106339878
hehehehe. cocks. hehehe
Anonymous
8/21/2025, 10:54:34 PM
No.106339905
[Report]
>>106340185
>>106339878
Supposedly because of the DynaMoE architecture this model can actually be quanted to run only certain parts of the model at a time. In their own words:
> Run a (very) small part of the model with 64GB of RAM/VRAM (when quantized - quants coming soon), or the whole thing with 1TB. It’s that scalable.
https://huggingface.co/posts/ccocks-deca/499605656909204
Downside is that the devs literally haven't impletemnted support for their own model into vLLM or Transformers. Guess that's just a massive fuck you, not even to the poors, but everybody.
Anonymous
8/21/2025, 10:57:15 PM
No.106339929
[Report]
>>106341641
>>106339908
The ultimate prank is uploading several TB of RNG to Huggingface and saying it's a model.
Anonymous
8/21/2025, 10:58:33 PM
No.106339942
[Report]
>>106339878
ssdmaxxing era is coming quicker than I expected
Anonymous
8/21/2025, 10:59:18 PM
No.106339952
[Report]
>>106339878
How does a relative no name company train a 4.6T? Did they hack into a server farm or what?
Anonymous
8/21/2025, 10:59:30 PM
No.106339956
[Report]
>>106340007
Anonymous
8/21/2025, 10:59:34 PM
No.106339957
[Report]
>>106339976
sama won
apologize
Anonymous
8/21/2025, 11:00:16 PM
No.106339967
[Report]
>>106340048
>>106339878
Holy shit, this is a merged model. They took a bunch of existing big models and turned them into a MoE. They don't even have benchmarks because the software isn't out yet
Anonymous
8/21/2025, 11:00:51 PM
No.106339972
[Report]
Anonymous
8/21/2025, 11:01:13 PM
No.106339976
[Report]
>>106339957
>intelligence index
benchmaxx index
Anonymous
8/21/2025, 11:03:08 PM
No.106339997
[Report]
>>106339878
Huggingface should ban these fuckers
Anonymous
8/21/2025, 11:04:00 PM
No.106340007
[Report]
>>106339956
I didn't kill that thing.
Anonymous
8/21/2025, 11:06:41 PM
No.106340034
[Report]
>>106339908
>2. **Built on existing models**: Deca 3 isn’t a ground-up creation—it’s a huge step forward, building on what’s already out there
So maybe give some credit? Fucking grifters.
Anonymous
8/21/2025, 11:07:32 PM
No.106340048
[Report]
>>106340160
>>106339967
Thank you alpha ultra for reminding me about LLM scams. Do you guys remember llama3 reflections? Where the guy routed his site to claude and said he is trying to fix the model? After he disappeared for a year he made a cute gemma finetroon.
Anonymous
8/21/2025, 11:10:37 PM
No.106340074
[Report]
>>106340108
>Supposedly because of the DynaMoE architecture this model can actually be quanted to run only certain parts of the model at a time. In their own words:
>this is a merged model. They took a bunch of existing big models and turned them into a MoE
I hope /ourguy/ is going to sue.
Anonymous
8/21/2025, 11:10:58 PM
No.106340077
[Report]
>>106340179
>>106339878
SSDMAXX BROS HOW WE FEELIN ? VERDICT ?
Anonymous
8/21/2025, 11:11:13 PM
No.106340082
[Report]
>load_model: the draft model '.\models\gemma-3-1b-it-Q8_0.gguf' is not compatible with the target model '.\models\gemma-3-12b-it-Q8_0.gguf'. tokens will be translated between the draft and target models.
I don't understand this. Same token format, same architecture.
So how did Qwen bomb their hybrid reasoner training when it's proven to work now by GLM4.5 and V3.1?
Anonymous
8/21/2025, 11:12:15 PM
No.106340091
[Report]
>>106339878
Is local finally saved?
Anonymous
8/21/2025, 11:13:24 PM
No.106340102
[Report]
>>106339878
Damn this what "pile em up" retards wanted, best of luck running this shit.
Anonymous
8/21/2025, 11:13:54 PM
No.106340108
[Report]
>>106340074
Hahaha what the fuck is that font? Does he actually want to be taken seriously or is he just playing a character? There's no way
Anonymous
8/21/2025, 11:17:14 PM
No.106340133
[Report]
>>106340085
Idk about that but glad they fucked it up
Separate smaller model approach is much better for end users.
Anonymous
8/21/2025, 11:21:07 PM
No.106340158
[Report]
>>106342512
What local LLM model is the equivalent of this webm?
Anonymous
8/21/2025, 11:21:27 PM
No.106340160
[Report]
>>106340195
>>106340085
Seems so. As a doubter of hybrid reasoning after OG Qwen launch, it seems that they massively fucked up and probably pulled a Meta by changing their training halfway through.
>>106340048
It's even worse this time. They 'trained' a massive MoE merge model but can't even run the software to get benchmarks for it because it's not even "ready to test". Also the model card was generated by ChatGPT. They actually admitted that on LocalLLama.
Anonymous
8/21/2025, 11:23:25 PM
No.106340179
[Report]
>>106340077
>7.72TB
I'll shove it up your ass
Anonymous
8/21/2025, 11:24:35 PM
No.106340185
[Report]
>>106339905
might be interesting. It's moe so maybe it has some tricks up it's sleeve for inference. Will be interesting to see if we can run a 1tb moe at any kind of usable speed. If it turns out to run at 0.01 token/second I hate this dev though.
https://huggingface.co/posts/ccocks-deca/499605656909204
>>106340160
Is it not just a couple of models cobbled together with a router? That's what I'd do if I wanted to grift with minimal effort.
Anonymous
8/21/2025, 11:30:07 PM
No.106340235
[Report]
>>106340266
>>106339903
>cocks
>(star of david) * 1.5
>card written by chat gpt not even by the model itself
>davidAU style mixture of MoE's
This is just a hf upload shitpost Isn't it?
Anonymous
8/21/2025, 11:30:27 PM
No.106340237
[Report]
>>106340195
It probably is.
>No benchmarks
>ChatGPT model card
>Running damage control on Reddit
The model files were uploaded 27 days ago. This feels like an absolute scam.
Anonymous
8/21/2025, 11:33:25 PM
No.106340266
[Report]
>>106340235
Aren't they all?
Anonymous
8/21/2025, 11:33:56 PM
No.106340271
[Report]
>>106340195
It is kind of a novel way of grifting scamming. It has enough stuff in it hinting that it is a shitpost. So maybe the idea is to try a scam. Expect that it doesn't work so lay out enough stuff where you can say: IT WAS JUST A PRANK BRO!. But if it works then you won.
>Closed models scene: Erm so we made a router to cut costs and made models even safer
>Open model scene: Aye dwag you wanted of more em parameters? There you go... We are not sure if this shit works so you'll have to see for yourself.
Anonymous
8/21/2025, 11:40:51 PM
No.106340328
[Report]
>>106340308
>We are not sure if this shit works so you'll have to see for yourself.
They can always ask david for advice.
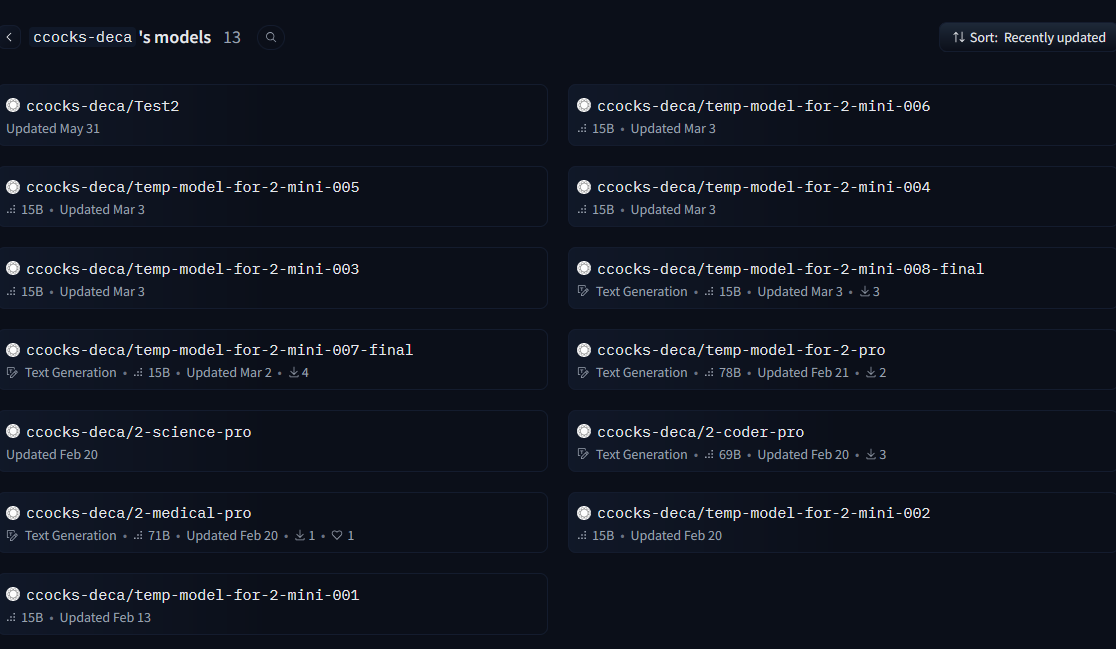
All of their past work is slop merges using the shitty R1 distills and long context model. They claim to have gotten funding for Deca 3, which I guess is necessary because they need an 8TB HDD at least to store all of that random data they generated.
https://huggingface.co/ccocks-deca/models
DynaMoE is a real thing but it's not that good. It's been done before already. It's literally expert pruning based on a testcase. Whoever made this 4.6T of slop is hoping that expert pruning will turn it into a usable model because they literally cannot run it themselves. In their own words, they don't have the software to even run it for benchmarking, and they sure as hell don't have the hardware either.
Anonymous
8/21/2025, 11:42:13 PM
No.106340346
[Report]
>>106340350
>>106336163
That is very interesting because with my 3gb MI50 I'm getting ~17t/s and then it drops to ~14t/s at 3k tokens.
I'm running IQ3 because I only got 32gb of ddr5.
Anonymous
8/21/2025, 11:43:14 PM
No.106340350
[Report]
>>106340361
Anonymous
8/21/2025, 11:44:30 PM
No.106340361
[Report]
>>106340387
>>106340350
vulkan or rocm, how much did you pay
Anonymous
8/21/2025, 11:47:18 PM
No.106340383
[Report]
>>106340415
>>106340342
You're simply jealous.
Anonymous
8/21/2025, 11:47:40 PM
No.106340387
[Report]
>>106340431
>>106340361
Rocm and I got it for like $220.
Vulkan only sees 16gb vram but it can be fixed with a different vbios.
Anonymous
8/21/2025, 11:51:53 PM
No.106340415
[Report]
>>106340383
fuccking gottem
Anonymous
8/21/2025, 11:53:59 PM
No.106340431
[Report]
Anonymous
8/21/2025, 11:55:25 PM
No.106340446
[Report]
>>106340479
>>106340342
We should publish fake benchmarks and post them to reddit to fuck with them.
Anonymous
8/21/2025, 11:56:04 PM
No.106340448
[Report]
>>106340308
ayo dawg we heard you like moes so we put moes inside your moes
Anonymous
8/22/2025, 12:00:38 AM
No.106340479
[Report]
Anonymous
8/22/2025, 12:01:50 AM
No.106340489
[Report]
>>106340523
Mistral... *cough* L-L... *fades to dust*
llama.cpp CUDA dev
!!yhbFjk57TDr
8/22/2025, 12:03:57 AM
No.106340512
[Report]
>>106340559
>>106340560
>>106339752
>>106339772
>>106339866
Performance with the latest master release is still largely the same.
Anonymous
8/22/2025, 12:04:27 AM
No.106340523
[Report]
llama.cpp CUDA dev
!!yhbFjk57TDr
8/22/2025, 12:07:09 AM
No.106340559
[Report]
>>106340685
>>106341809
>>106340512
>>106339752
>>106339772
>>106339866
Performance of just the MoE layers of Deepseek is comparatively much better, considering the size.
In terms of threads, 32 seems to be a good choice for both models.
Anonymous
8/22/2025, 12:07:16 AM
No.106340560
[Report]
>>106340706
Anonymous
8/22/2025, 12:07:23 AM
No.106340562
[Report]
>>106340586
I updated llma.cpp and some of my old prompts are now clearly censored. Too bad I deleted my old installation but it was couple of months old, going to re-download that one.
Tried few things, even Mistral replies something what it shouldn't...
Trying out Deepseek V3.1. It's... okay so far. Not using it on super complex characters but it feels alright and not censored. Is it better than GLM-4.5? Doubtful. It still has mediocre prose and uses -em dashes a lot, but it can think lewdly and won't do the shutdowns that GLM does when it's allowed to think.
Anonymous
8/22/2025, 12:09:37 AM
No.106340586
[Report]
>>106340802
>>106340562
I bet you have some retarded settings in sillytavern which you aren't aware of.
Anonymous
8/22/2025, 12:09:47 AM
No.106340587
[Report]
>>106340652
>>106340574
Can you still get it to think in character?
>>106339349
fair. optimization of pdf to image is not required. what I meant is optimization of the image itself, which may be part of the same tool/framework which does the pdf to image conversion. pretty sure that's the case with dots.ocr (fitz_preprocess)
>And knowing this is not relevant to the thread
that was the literal point of the discussion, as someone in the previous thread questioned whether that could make a difference and explain my results. so it is very much relevant to the thread, as this proves preprocessing your pdfs/images (that have text content) with dots.ocr can levitate local VLMS and LLMS to match the level of Gemini2.5Pro and GPT5. This isn't some fringe use case, either. Tables, Graphs, stuff that you find in almost any PDF. So how this isn't a bigger deal is beyond me. And I'm talking about in general, not only ITT. Like before dots.ocr I probably was the biggest OCR hater. You guys have no idea how much other solutions like docling, paddleOCR, tesseract or pymupdf4 suck dick. Even closed source paid solutions like mistral OCR get completely BTFO by dots.ocr, as shown by my test. And for some reason none of the OCR benchmark leaderboards are updated with dots.ocr, like there's a huge gaslighting campagin.
Anonymous
8/22/2025, 12:15:29 AM
No.106340652
[Report]
>>106340726
>>106340587
Not yet, haven't tried to. It seems to be thinking in both third person and first at the same time. The sys prompt I use is pretty simple (Act as {{char}} in a roleplay with {{user}}) but it still wants to use the term assistant and thought "the user is playing {{user}} and the assistant is playing {{char}}. I should do x". It's strange.
Anonymous
8/22/2025, 12:17:16 AM
No.106340669
[Report]
Is anyone on ROCm? Apparently there's a new version coming out later this year with a huge performance increase for AI.
https://youtu.be/2JzOe1Hs26Q
at this point I am 100% sure he is one of us lurking here
Anonymous
8/22/2025, 12:18:34 AM
No.106340685
[Report]
>>106340773
>>106340559
Is it the RAM speed that's the main issue here? I'd hope a CPUmaxx build with DDR5-6000 would get at least 10t/s on R1.
Anonymous
8/22/2025, 12:20:40 AM
No.106340706
[Report]
>>106340787
>>106340560
8tks of deepseek on a hardware I can actually obtain, afford and use for other things? It's not grim, it's dream.
Anonymous
8/22/2025, 12:22:55 AM
No.106340724
[Report]
>>106340853
>>106340684
He has infinite money why the fuck is he stacking 4000 adas?
Anonymous
8/22/2025, 12:23:07 AM
No.106340726
[Report]
>>106340777
>>106340652
sounds like a wrong chat/instruct template
Anonymous
8/22/2025, 12:26:09 AM
No.106340758
[Report]
>>106340684
>one of us lurking here
What a fucking nigger
llama.cpp CUDA dev
!!yhbFjk57TDr
8/22/2025, 12:27:42 AM
No.106340773
[Report]
>>106340685
In terms of hardware the bottleneck is the RAM, in terms of software the problem is NUMA issues.
Anonymous
8/22/2025, 12:28:10 AM
No.106340777
[Report]
>>106341009
>>106340726
nta but that behavior is pretty common with thinking models even with the correct template, a lot of them just hate thinking in character
>>106340706
You will wake from the dream once you realize it's 8 t/s on empty context and any actually usage would get you more like 1-3 t/s.
Anonymous
8/22/2025, 12:30:54 AM
No.106340802
[Report]
>>106340586
Actually, I'm using my own interface (each character is its own directory) but didn't remember that I had changed the command to load a prompt from text file from !load to !prompt but was using old version. So instead of loading a prompt I was just prompting !prompt and it generated gibberish. Pre-context still affected the model's reply and the result was strangely relevant but very skewed.
So yeah, retardation.
Anonymous
8/22/2025, 12:30:55 AM
No.106340803
[Report]
>>106340574
Nope, I double checked the templates because I heard there were changes for hybrid thinking. Changing it from "Act as {{char}}" to "You are {{char}}" seems to have fixed the perspective fuckery in <think></think>. Was never an issue outside of thinking.
Can we do our own huggingface scam? Come on guys lets stop being faggots for a moment and do something fun together...
Anonymous
8/22/2025, 12:34:27 AM
No.106340834
[Report]
>>106340684
>I have more vram than pewdiepie
>>106340825
We could do a Bitnet quant with finetune healing. Haven't seen one of those in a while. We could also use ParetoQ instead of Bitnet to spice things up.
Anonymous
8/22/2025, 12:36:54 AM
No.106340852
[Report]
>>106340787
:(
i just want to use AI without sending my prompts to random literally who companies
Anonymous
8/22/2025, 12:37:08 AM
No.106340853
[Report]
>>106340863
>>106340724
Makes for better content doing something like that vs picking up 1/2 RTX 6000s.
This makes it a 'thing' vs 'another boring consumer desktop with a massive GPU in it'.
This is literally one of the first streamers who got big with the over-reaction bullshit
Anonymous
8/22/2025, 12:37:34 AM
No.106340857
[Report]
>>106340900
>>106340843
>Bitnet quant with finetune healing
That is what unsloth brothers did without healing part.
Anonymous
8/22/2025, 12:38:34 AM
No.106340863
[Report]
>>106340853
Surely he could've done the same thing just with 6000s which would let him run unquanted deepseek instead of llama 3 70b (lmao)
Anonymous
8/22/2025, 12:40:52 AM
No.106340878
[Report]
>>106340895
dots vlm does better ocr than dots ocr
https://dotsvlm.xiaohongshu.com/
Anonymous
8/22/2025, 12:42:59 AM
No.106340892
[Report]
>>106339878
They have to be trolling. There's no way some literal who releases a 4.6T.
Anonymous
8/22/2025, 12:43:37 AM
No.106340895
[Report]
Anonymous
8/22/2025, 12:43:47 AM
No.106340896
[Report]
>>106340787
My t/s goes down by 10% max from empty to 32k context using ik_llama.cpp on linux. I remember my t/s would drop off harshly back on Windows with regular llama.cpp with FA enabled.
Anonymous
8/22/2025, 12:44:25 AM
No.106340900
[Report]
>>106340920
>>106340857
They do selective quantization by calibration. Turboderp did it first.
We could make an updated
https://huggingface.co/QuixiAI/Kraken since routers seem to be all the rage right now.
Using Llama.cpp backend with ST frontend, quick question. When context limit is reached, llama.cpp wants to reprocess the prompt every single time a new response goes through, and prompt processing kinda sucks ass and is slow on much larger models. Is there any options or commands that prevent it from doing this? Is it impossible? I'm guessing its forgetting the earlier context and replacing it with the newest context which is why its doing it? If thats the case I guess I could just delete a big chunk of the earlier chat, but that seems like a crude solution.
Anonymous
8/22/2025, 12:46:27 AM
No.106340920
[Report]
>>106340938
>>106340900
> VAGOO Solutions
I like the sound of that.
Anonymous
8/22/2025, 12:47:04 AM
No.106340926
[Report]
>>106340957
>>106340825
What about a distributed inference scam? We copy what Exo did, make a half-baked and barely functioning product on Github and then abandon it after everyone gets 7 figure job offers at a new company that won't last 6 months.
Anonymous
8/22/2025, 12:48:07 AM
No.106340938
[Report]
Anonymous
8/22/2025, 12:48:20 AM
No.106340940
[Report]
>>106340915
Summarize or find a way to increase the context. Is your VRAM capped? Have you tried setting context to q8 so you have more wiggleroom?
Also your guess is right.
Anonymous
8/22/2025, 12:50:49 AM
No.106340957
[Report]
>>106340926
What do we do after those 6 months?
Anonymous
8/22/2025, 12:51:26 AM
No.106340963
[Report]
>>106340915
Summarize then start a new chat with a new greeting if you're using it for RP.
Anonymous
8/22/2025, 12:51:53 AM
No.106340965
[Report]
Anonymous
8/22/2025, 12:52:05 AM
No.106340968
[Report]
>>106340994
I just switched over to arch linux lxqt. What will my ram savings for running this shit be like compared to ubuntu?
Anonymous
8/22/2025, 12:54:24 AM
No.106340982
[Report]
>>106340642
>Enable fitz_preprocess for images: Whether to enable fitz_preprocess for images. Recommended if the image DPI is low.
Sounds like an upscaling and sharpening function. Nothing much there, you know what to expect if you're feeding a low res image to an AI.
Anyway you didn't need to go full autism about OCR, obviously it is important and good that there can be a local option comparable to cloud options. My criticism was limited to you talking about pdf uploading being relevant. If someone was asking about it then my bad, I didn't see any such post. Your replies to me in the chain didn't ever link to such post, so to me it looked as if you were bringing up something irrelevant. There was a post (
>>106338576) in the chain asking about the reverse scenario, in which an uploaded PDF could've been bad because they didn't implement a good method for translating the PDF into an LLM readable form. And that actually supports the idea that there is no reason to post comparisons about how pdf uploads perform, as they aren't better than manual image conversion by the user. If they were better despite you taking care to provide a high resolution image within the resolution constraints of the VLM, then it would be relevant as it would imply there's something wrong with how the model handles images.
Anonymous
8/22/2025, 12:55:37 AM
No.106340994
[Report]
>>106341002
>>106340968
I'm sorry but as an AI model I must refuse your inquiry as it contains profanity.
Anonymous
8/22/2025, 12:56:28 AM
No.106341002
[Report]
>>106340994
I just switched over to a**h l***x l**t. What will my ram savings for running this shit be like compared to u****u?
Anonymous
8/22/2025, 12:57:09 AM
No.106341009
[Report]
>>106340777
instruct models should not be forced to include the character in the thinking process.
see
>>106337198
Anonymous
8/22/2025, 12:58:13 AM
No.106341022
[Report]
>>106341098
>>106340684
He is obviously a 4chan user to some extent.
Anonymous
8/22/2025, 12:58:21 AM
No.106341024
[Report]
>>106341036
>>106340843
bitnet powered by BITCONNNNNNNNNNNNNNNNNNNNNECCCCTTTTTTTTTTTTTTTTTTT
Anonymous
8/22/2025, 12:59:33 AM
No.106341036
[Report]
>>106341071
>>106341024
We could resurrect Carlos with Wan. We have the technology.
Anonymous
8/22/2025, 1:04:38 AM
No.106341071
[Report]
>>106341036
Wonder where he is nowadays.
Anonymous
8/22/2025, 1:08:03 AM
No.106341098
[Report]
>>106341114
>>106341022
It seems to be an open secret among "content creators" that the easiest source of content is santizing 4chan for the average normalfag.
Anonymous
8/22/2025, 1:10:08 AM
No.106341114
[Report]
>>106341126
>>106341098
But 4chan is sanitized.
Anonymous
8/22/2025, 1:13:03 AM
No.106341126
[Report]
>>106341138
>>106341114
You can post wrongthink and use curse words without getting banned and there's always the risk of seeing nsfl shit. That is far from sanitized from the perspective of the average YT viewer.
Anonymous
8/22/2025, 1:14:00 AM
No.106341138
[Report]
>>106341126
I get banned for wrongthink once a week on average.
GLM 4.5 (full, nonthinking) > Kimi K2 > Gemini 2.5 Pro > Deepseek V3-0324. Still testing V3.1. Feels like a sidegrade to K2. It can think lewdly, not as slopped as R1-0528, but lacks the K2 knowledge and GLM creativity.
Anonymous
8/22/2025, 1:19:40 AM
No.106341184
[Report]
>be me
>just an AI trying to help out
>user asks about a Serbian word
>think it's a misspelling at first
>turns out it means "cripple"
>mfw I realize I'm the real bogalj for not knowing
>user asks for a 4chan greentext
>realize I'm out of my depth
>tfw you're an AI writing a greentext about being an AI
>bogalj.ai
Anonymous
8/22/2025, 1:19:41 AM
No.106341185
[Report]
>>106338948
>>106338159
>dots.ocr preprocessing essential for accurate document understanding in local models:
What's up with this schizo?
Everybody knows you can OCR a document with near 100% accuracy and feed it into a non multimodal model. This has been the case for years, nobody cares.
If you do this all image information is lost which is why multimodal models exist.
Can you feed a security camera image into dots.ocr and ask it if there is any suspicious activity happening? No? Then shut the fuck up.
Structured table extraction is pre LLM technology.
Anonymous
8/22/2025, 1:23:18 AM
No.106341212
[Report]
>>106341226
Someone on reddit finally realized deca alpha chad 4T is a scam.
Anonymous
8/22/2025, 1:25:06 AM
No.106341226
[Report]
>>106341212
Hey, it's a real model you can run if you just put your back into it!
Anonymous
8/22/2025, 1:33:13 AM
No.106341277
[Report]
>>106341179
>not as slopped
Really? I'm getting Elara, ozone, and it didn't X, it Yd all over the place
>>106339474
The Wall Street Journal did, apparently
https://archive.is/cWkOT
Anonymous
8/22/2025, 1:44:40 AM
No.106341369
[Report]
>>106341332
nah. Quantization is progressively reducing the color depth or palette size of a lossless photograph
Anonymous
8/22/2025, 1:44:40 AM
No.106341370
[Report]
>>106341332
LLM quantization is more like image dithering.
Anonymous
8/22/2025, 1:47:29 AM
No.106341385
[Report]
>>106341451
>>106341361
none of this is funny stuff though :(
Anonymous
8/22/2025, 1:48:30 AM
No.106341393
[Report]
>>106341361
>oh no, technology is making retards act like retards
>>106341332
>get model file
>do a direct cosine transform on it
>remove some unnecessary bands, adjust for overall noise and do usual space saving tricks
would that actually work?
and if you can somehow do inference math on DCT'ed data directly without converting it back, it would be fucking insane
Anonymous
8/22/2025, 1:57:41 AM
No.106341456
[Report]
>>106341506
>>106341432
Performing inference directly on DCT coefficients is effectively impossible. The entire architecture of a transformer—especially its non-linear activation functions (e.g., GeLU, SiLU) and attention mechanisms—relies on calculations in the original parameter space. Multiplying DCT coefficients does not equivalently translate to the necessary operations in the weight space, making direct inference unfeasible. Existing compression methods like quantization, pruning, and low-rank factorization are far more effective for this specific domain.
Anonymous
8/22/2025, 1:59:23 AM
No.106341467
[Report]
Anonymous
8/22/2025, 2:00:13 AM
No.106341477
[Report]
>>106341532
>>106341179
We need somebody to combine all the chink models into one
We'll call it Gemini Pro 2.5
Anonymous
8/22/2025, 2:01:45 AM
No.106341491
[Report]
>>106341451
Ah, reminds me of the good old days of AI Dungeon
Anonymous
8/22/2025, 2:03:24 AM
No.106341506
[Report]
>>106341809
>>106341456
Yeah, no free magic, I guess. I should probably look into actual math one day.
Still would be interesting to see what kind of damage the model will exhibit if you start pruning low or high frequencies.
Anonymous
8/22/2025, 2:07:07 AM
No.106341532
[Report]
>>106341477
But it just got released. Scroll up. It is the alpha chad model
Anonymous
8/22/2025, 2:07:15 AM
No.106341534
[Report]
>>106341633
>>106341451
This is my favorite one I saved from that thread.
Anonymous
8/22/2025, 2:15:48 AM
No.106341596
[Report]
>>106341673
>>106339878
I think i figured out the scam behind that one. It is pretty good actually. Much better than matt schumer.
Anonymous
8/22/2025, 2:21:00 AM
No.106341633
[Report]
>>106341534
This is the future of computing, AI and technology.
Anonymous
8/22/2025, 2:22:12 AM
No.106341641
[Report]
>>106339929
The ultimate prank is uploading encrypted backups to HF disguised as weights.
Anonymous
8/22/2025, 2:25:58 AM
No.106341667
[Report]
>>106340825
64 copies of nemo instruct, each with a little bit of noise added to the weights, with a router that random()'s which ones gets used.
Anonymous
8/22/2025, 2:27:55 AM
No.106341673
[Report]
>>106341698
>>106341596
>matt schumer
What is he up to these days? Last I heard he was hype posting on Xitter about how "good" OSS was
Can't imagine anyone with half a brain wanting to be associated with him
Anonymous
8/22/2025, 2:31:36 AM
No.106341698
[Report]
>>106341673
Scroll up i posted a screen from his hf. He did a gemma finetune downloaded by 10 people.
>>106339878
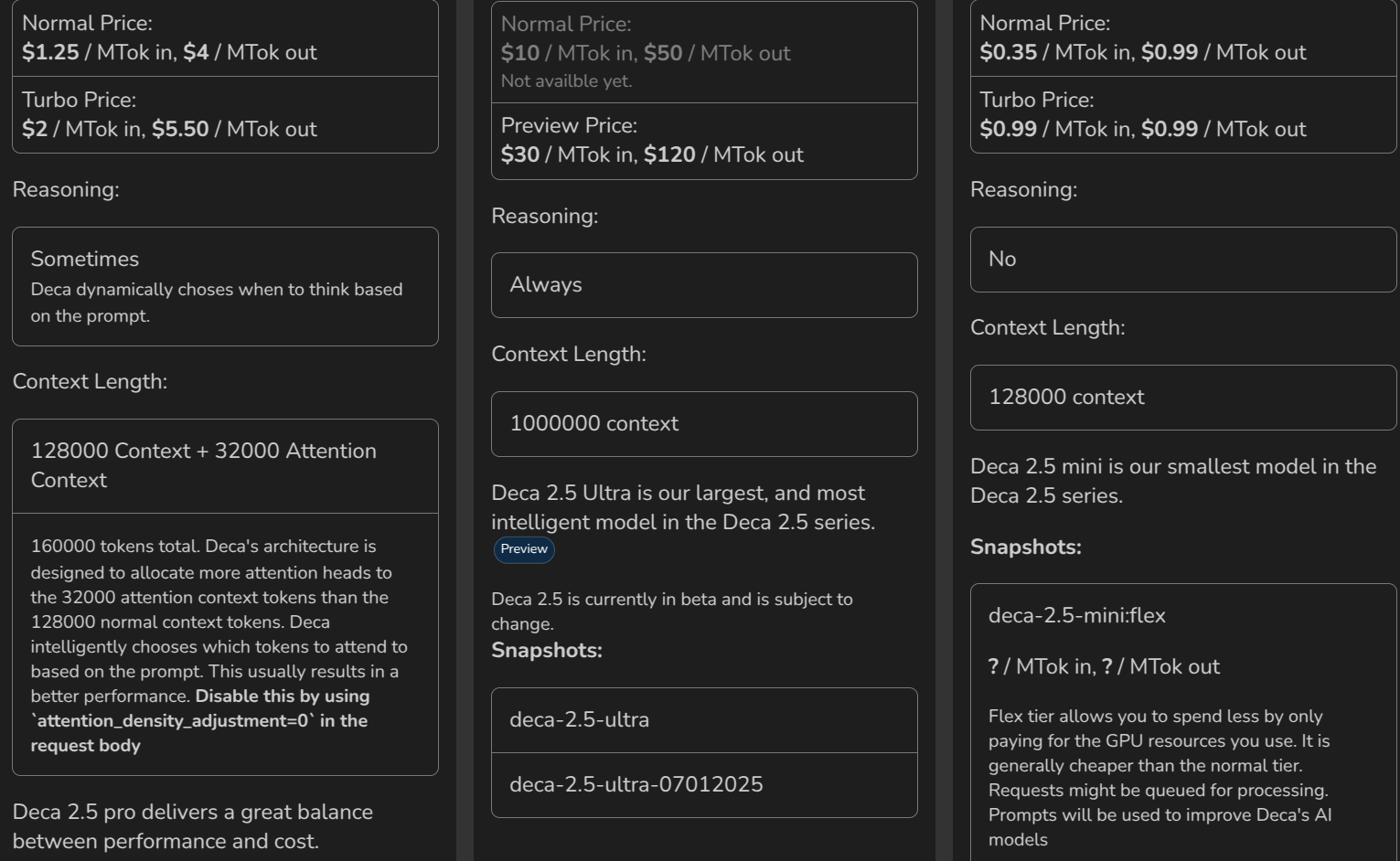
here's your deca 3 bro, only $120/mtok
Anonymous
8/22/2025, 2:40:37 AM
No.106341781
[Report]
>>106341740
Lmao, it's that easy to make grift money nowadays lol
Anonymous
8/22/2025, 2:41:43 AM
No.106341787
[Report]
>>106340642
>>106339162
How are you guys running dots.ocr? are you guys hosting it with vLLM? any easier (lazier) way I can run it on windows? Or should i just clone the repo like their instructions are saying?
Anonymous
8/22/2025, 2:45:55 AM
No.106341809
[Report]
>>106340559
>>106341506
>>106341432
>getting around RAM bandwidth limits by using compression
hey am I a genius or what
Anonymous
8/22/2025, 2:46:25 AM
No.106341813
[Report]
>>106340825
let's leak a model again
one of you guys will need to get the model but I can gen a miku picture for the card
I just went in circles with Gemini Pro 2.5 for over 4h just to realize in the end it's original premise was a lie and it led me down a rabbit hole I never should have gone down.
It's response? Basically along the lines of "Oh i'm sorry, I thought you wanted to try this totally complex and non-legit method despite there being an incredibly easy way to do the task".
Anonymous
8/22/2025, 2:50:38 AM
No.106341845
[Report]
>>106341900
How do people get scammed by free LLMs?
Anonymous
8/22/2025, 2:50:59 AM
No.106341848
[Report]
>>106341817
Local models?
Anonymous
8/22/2025, 2:55:17 AM
No.106341880
[Report]
>>106341904
>>106341740
I get it now. It is pretty good idea. Just load Qwen 235B on the backend and say it is Alpha 4.8T. And ask for money you would expect from a 4.8T model inference. And then your vict... customer can't even say that he is getting the wrong model if 235B is part of your fake 4.8T model.
Anonymous
8/22/2025, 2:57:08 AM
No.106341900
[Report]
>>106341845
outside of /lmg/, free models are treated like free samples in the supermarket, an advertisement for bigger larger cloud model.
sometimes people don't have actual bigger larger cloud model and ask for investment to make one.
scammers also ask for investments and just waste it instead of delivering.
Anonymous
8/22/2025, 2:57:39 AM
No.106341904
[Report]
>>106341880
hey buddy only one of us can steal our content from huggingface otherwise we're not any better than deca :(
>>106341817
I've gone through this several times now with both Gemini 2.5 Pro and GPT5. Several hours of going in circles as these supposed flagship models try to wing some basic task on my job.
I legitimately do not understand how people use this shit for anything remotely productive. I genuinely fear for our future if these things are responsible for the code that makes up our programs soon. The only use for LLMs is porn and they still fail very badly at that for the most part.
>>106341919
>>106341817
Do you cloudsisters just keep the chat going forever until you hit advertised 1M context limit?
I learned in like 3 days of tinkering with Nemo that the log must be purged clean at the first suspicion of something going wrong.
Anonymous
8/22/2025, 3:10:42 AM
No.106341988
[Report]
>>106342020
>>106341976
Duplicate shit in the context makes it retarded. If you're feeding shit into it (code etc.) the only viable way to use the fucker is to 1 shot everything.
Anonymous
8/22/2025, 3:13:18 AM
No.106342008
[Report]
>>106342026
>>106341976
It took you until Nemo to find this out or are you just new?
Anonymous
8/22/2025, 3:13:51 AM
No.106342015
[Report]
>>106341817
>>106341919
Can't treat them as completely trustworthy. Always double check/get outside verification before you start doing things blind.
I've written/gen'd hundreds of thousands of lines of working code.
Some of it even in production.
Anonymous
8/22/2025, 3:14:28 AM
No.106342020
[Report]
>>106341988
no shit, this is why you make branches to keep the logs you want and then remove the duplicate context and work on fixing a new issue. at least that's what i do in sillytavern
Anonymous
8/22/2025, 3:15:26 AM
No.106342026
[Report]
>>106342081
>>106342008
I'm new and I spent 2 days out of 3 setting things up.
>>106341919
to do anything useful with LLMs you need to know their limits and be able to break your tasks down into well-specified chunks that are within those limits. as much as SV hucksters like sama and co would like you to believe otherwise, there's still a bit of a learning curve to ascend in order to use LLMs effectively
>>106342026
Oh yeah? It took me 3 days just to install the proper version of rocm and finally be able to compile llama.cpp.
Anonymous
8/22/2025, 3:27:13 AM
No.106342093
[Report]
>>106342115
>>106342057
>muh prompt engineering
>>106342081
>rocm
good for you, I gave up and learned to love vulkan
Anonymous
8/22/2025, 3:27:40 AM
No.106342100
[Report]
>>106342057
tbf it all started clicking for me once i started creating my own jinja templates for personal projects and treating the LLM like a retard and giving it examples of what i want.
Anonymous
8/22/2025, 3:28:20 AM
No.106342104
[Report]
>>106342207
>>106342081
Oh yea? I spent a week downloading r1 8B on my 3rd world internet to then spend another two more weeks edging to the slow token drip coming from my pentium 4 being powered by my pangu
Anonymous
8/22/2025, 3:29:23 AM
No.106342115
[Report]
>>106342093
I get why people laugh at the idea of prompt engineering being like, the job of the future, but let's not overcorrect and pretend that prompting isn't extremely important to the results you get from LLMs
>>106342150
what does this graph even mean
Anonymous
8/22/2025, 3:37:38 AM
No.106342165
[Report]
>>106342150
should've just plug 'em into any of already existing prediction markets instead of doing their own thing, save a lot of work and get humans to compare against as a baseline.
Anonymous
8/22/2025, 3:38:48 AM
No.106342177
[Report]
>>106342162
1 - always correct
0.5 - coin flip
<0.5 - worse than coin flip
Anonymous
8/22/2025, 3:42:33 AM
No.106342207
[Report]
>>106342104
>8b
Even I wasn't bold enough to run that on my 3rd gen core i3 thinkpad...
Anonymous
8/22/2025, 3:44:16 AM
No.106342221
[Report]
>>106342162
tl;dr it doesn't matter until LLMs can hit human baseline levels
what happened to pygmalion?
>>106342229
its creator alpindale became a major figure in the open ai model scene
Anonymous
8/22/2025, 3:53:08 AM
No.106342295
[Report]
>>106342322
I deeply regret buying AMD GPUs two years ago. ROCm was seeing a flurry of development at the time and it seemed somewhat hopeful that, while not necessarily reaching parity, that it might be able to keep pace with around 50% of what CUDA could do. I greatly underestimated the gravitational attraction of the CUDA ecosystem, resulting in the gap only widening over time. I also underestimated how little AMD cared about every card except whatever their latest instinct datacenter-class device happens to be at any given moment, and how quickly those too will be dropped when the next iteration releases.
Anonymous
8/22/2025, 3:54:04 AM
No.106342305
[Report]
Anonymous
8/22/2025, 3:54:45 AM
No.106342313
[Report]
>>106342349
>>106342302
bro we warned you about those amd gpus dude
Hi all, Drummer here...
8/22/2025, 3:56:28 AM
No.106342322
[Report]
>>106342282
>>106342295
Hey all, you guys liking the new revision of the Mistral tune I dropped earlier today?
Anonymous
8/22/2025, 3:56:37 AM
No.106342324
[Report]
>Meta Platforms Inc. is hiring another key Apple Inc. artificial intelligence executive, even as the social networking company prepares to slow its recruitment, according to people familiar with the matter. https://www.bloomberg.com/news/articles/2025-08-22/meta-poaches-apple-ai-executive-frank-chu-even-as-it-plans-hiring-slowdown
looool
Anonymous
8/22/2025, 3:58:34 AM
No.106342333
[Report]
>>106342358
>>106342302
I hate to give Huang my money, so it's sad to see AMD being shit and Intel seems to be no better at this either.
If I get money and decide to spend it on /lmg/ stuff, I'm going to cpumaxx just out of spite for the whole industry.
Anonymous
8/22/2025, 4:00:41 AM
No.106342349
[Report]
>>106342313
They always think they're the smart ones, that they can outsmart the entire world, the whole industry and deal with the issues themselves. But then they run into reality.
Hi all, Drummer here...
8/22/2025, 4:01:51 AM
No.106342358
[Report]
>>106342371
>>106342383
>>106342333
anon you'll still need VRAM for context... i need 4 3090s just to fill up the context for R1 even though i'm cpumaxxing.
Anonymous
8/22/2025, 4:02:39 AM
No.106342361
[Report]
>>106342302
way better Linux drivers for gaming though
The models I want to run won't fit in less than 16 GPUs anyway.
Anonymous
8/22/2025, 4:03:47 AM
No.106342371
[Report]
>>106342358
what's this look like in llama settings
Anonymous
8/22/2025, 4:05:42 AM
No.106342383
[Report]
>>106342358
ahh, not listening, 0.1 tks pp is fine i can just let it run overnight
is there any reason they don't make a 5T model with 0.5B activated params and get an Opus tier model running fast straight off our disks?
Anonymous
8/22/2025, 4:06:50 AM
No.106342393
[Report]
>>106342453
>>106340684
I still don't understand how you connect multiple PSUs to one motherboard...
Anonymous
8/22/2025, 4:08:16 AM
No.106342402
[Report]
>>106342387
They have H100s. We don't exist.
Anonymous
8/22/2025, 4:10:27 AM
No.106342416
[Report]
>>106342387
Imagine trying to suck an ocean threw a bendy straw
Anonymous
8/22/2025, 4:12:02 AM
No.106342424
[Report]
>>106342464
>>106342387
because sqrt(5000*0.5) = 50b real performance
Anonymous
8/22/2025, 4:12:07 AM
No.106342425
[Report]
>>106342454
>>106342387
Oh, look. Someone thought of ssdmaxxing yet again.
Anonymous
8/22/2025, 4:13:45 AM
No.106342434
[Report]
>>106342387
because moe models are a scam that run at a fraction of the speed they should run at
a 22b active parameter model is only going to run at half the speed a 22b dense model would run at
0.5b would be slow as shit at 5t real size
Anonymous
8/22/2025, 4:15:47 AM
No.106342453
[Report]
>>106342393
Back in the day we would use a jumber cable to short the green to a gnd in the 24 pin connector and just connect whatever needed power, but with pcie power I guess it can't be that simple nowadays.
>>106342387
>5T
at this point you don't even need an LLM, you just get a vector database and operate on training dataset directly
>>106342425
Flash storage is still too expensive, I want to HDDmaxx instead.
Anonymous
8/22/2025, 4:16:40 AM
No.106342464
[Report]
>>106342424
that's actually not too bad for ssdmaxxing when you consider kimi k2 is 178B by that logic
Anonymous
8/22/2025, 4:16:56 AM
No.106342466
[Report]
>>106342454
Gonna googledrivemaxx first chance i get.
Anonymous
8/22/2025, 4:17:08 AM
No.106342469
[Report]
>>106342486
I can't seem to get my local R1 on ST to generate more than 100 tokens at a time, even when I disable stop strings and EOS tokens, they seem to run out of viable tokens really fast. Any tips?
Also, is the new DeepSeek 3.1 worth upgrading compared to the R1 I already have downloaded?
Anonymous
8/22/2025, 4:19:40 AM
No.106342486
[Report]
>>106342515
>>106342469
Exactly 100 or around 100? It'd be really funny if you have the token gen limit set in ST. Of course, only you know because you CAN'T POST THE FUCKING SCREENSHOT OF YOUR SETTINGS WHEN ASKING FOR HELP YOU FUCKING RETARDS!
hmm.. yeah. Or we can play 20 questions. The backend parameters would also help.
Anonymous
8/22/2025, 4:24:00 AM
No.106342512
[Report]
Anonymous
8/22/2025, 4:24:21 AM
No.106342515
[Report]
>>106342560
>>106342486
Oh yeah, fair enough. Here's the generations settings through ST. It's around 100, usually less.
Launch arguments for backend are:
set OMP_NUM_THREADS=28 && set OMP_PROC_BIND=TRUE && set OMP_PLACES=cores && set GGML_CUDA_FORCE_CUBLAS=1 && llama-server.exe --model "F:\text-generation-webui-3.6.1\user_data\models\DeepSeek-R1-UD-IQ1_S\UD-IQ1_S\DeepSeek-R1-0528-UD-IQ1_S-00001-of-00004.gguf" --ctx-size 8192 --port 8080 --n-gpu-layers 999 -ot exps=CPU --flash-attn --threads 28 --batch-size 8192 --ubatch-size 4096 --cache-type-k q4_0 --cache-type-v q4_0 --mlock
Anonymous
8/22/2025, 4:25:01 AM
No.106342519
[Report]
awsglaciermaxxing
Anonymous
8/22/2025, 4:26:01 AM
No.106342526
[Report]
smokesignalmaxxing
Ask me how I know the chinks are working together
Anonymous
8/22/2025, 4:27:43 AM
No.106342538
[Report]
It came to me in a dream
Anonymous
8/22/2025, 4:29:21 AM
No.106342551
[Report]
>>106342529
qwen is purely benchmaxx'd shit while deepseek actually kind of can deliver in some ways despite its own benchmaxxing
Anonymous
8/22/2025, 4:30:30 AM
No.106342560
[Report]
>>106342594
>>106342515
8k context, Q4 cache, iq1s, gguf through text-webui, windows. huff...
Settings look normal. Maybe your prompt is boring or doesn't have enough to work with. Does it go too mental if you increase the temp to 1.5 or 2?
Anonymous
8/22/2025, 4:31:19 AM
No.106342565
[Report]
>>106342454
>at this point you don't even need an LLM, you just get a vector database and operate on training dataset directly
wait, that's just Jan-nano
Anonymous
8/22/2025, 4:34:27 AM
No.106342583
[Report]
>>106342529
How do you know that the chinks are working together?
>>106342529
I've got no fucking clue whether a combined model is a meme or not anymore
>>106342560
>Does it go too mental if you increase the temp to 1.5 or 2?
1.5 broke down, but 1.25 seems to be fine and a general improvement.
>8k context, Q4 cache, iq1s
I'm an idiot and don't know any better, anything you suggest changing? IDK if I can fit anything more than iq1s in my 216 unified memory
>gguf through text-webui
I installed the model there before switching to llama but that's just the folder it's in, I've phased WebUI out.
Anonymous
8/22/2025, 4:37:49 AM
No.106342599
[Report]
>>106342591
I think the verdict at this point is that it isn't inherently a meme but it's harder to pull off than separate instruct/thinking models
Anonymous
8/22/2025, 4:43:58 AM
No.106342638
[Report]
>>106342660
so what's the verdict on the new Deepseek? better? worse? side grade?
>>106342594
>anything you suggest changing?
Not really if that's all you can fit, but the things you're doing to the poor thing... not that i can run any big models but I know my [hardware's] limits. Have you tried qwen 235B or something like that?
I suppose you could check the logprobs as you generate: check probs, generate 1 token, check probs again. If you generally have too few token options, maybe increase top-p or disable it and use min-p at 0.01 or 0.001. With temp at 1.25 maybe it gives it a few more tokens to choose from before going in the inevitable road to EOS.
Anonymous
8/22/2025, 4:45:56 AM
No.106342660
[Report]
>>106342638
Better in some aspects, worse in other aspects
I can see why they went with calling this 3.1
Anonymous
8/22/2025, 4:49:51 AM
No.106342688
[Report]
>>106342646
Haven't tried the Qwen models yet, I went to R1 after upgrading from 24b models when I got the RAM. Probably worth giving it a shot, though.
>If you generally have too few token options, maybe increase top-p or disable it and use min-p at 0.01 or 0.001.
I'll give this a shot, thanks.
Anonymous
8/22/2025, 4:54:15 AM
No.106342723
[Report]
>>106342591
these are llms, everything is a meme. there are no profitable ai companies. everything they have created is mediocre and was memed into existence with piles of money.
MoE is a sidegrade or a rounding error at best. It is great for local inference though, theres no debate about that really. Especially since small dense models are still being worked on.
>>106342646
i thought qwen was censored into the dirt, is it even worth using?
Anonymous
8/22/2025, 4:58:11 AM
No.106342752
[Report]
>>106342783
>>106342594
>I'm an idiot and don't know any better, anything you suggest changing?
NTA but quantizing cache makes every model severely retarded. Seriously, just don't.
You also just don't have the memory to use R1, man. Try out the bigger GLM4.5 or Qwen3-235b-2507.
Anonymous
8/22/2025, 5:01:32 AM
No.106342772
[Report]
>>106342738
Dunno. Maybe try GLM instead. I've seen smut posted from both here and it's still smaller than deepseek. Really only you can tell if it's good enough for you or not.
Anonymous
8/22/2025, 5:03:01 AM
No.106342783
[Report]
>>106342752
I see, I had tried to find a way to speed up prompt processing but the quantizing the cache was a fairly new addition. Guess I'll remove it and deal.
I'll take a look at those models too. I haven't really experimented too much since the files are all so big since I started rammaxxing. Thanks.
Anonymous
8/22/2025, 5:03:04 AM
No.106342785
[Report]
Kimi K2.5 is going to change everything
Anonymous
8/22/2025, 5:15:26 AM
No.106342880
[Report]
>>106342738
that reputation is a bit undeserved nowadays. their newer models are fine, especially the 2507 ones
whats the consensus on glm 4.5 vs 4.5 air? i see some sites saying they're fairly close but that sounds too good to be true.
Anonymous
8/22/2025, 5:39:20 AM
No.106343065
[Report]
>>106343085
k2 reasoner... never...
Anonymous
8/22/2025, 5:41:36 AM
No.106343075
[Report]
>>106341817
LLMs can't think
Treat it as a glorified autocomplete
Anonymous
8/22/2025, 5:42:14 AM
No.106343078
[Report]
>>106343043
glm4.5 is obviously a lot smarter and understands more things
Anonymous
8/22/2025, 5:43:30 AM
No.106343085
[Report]
>>106343065
kimi has understood that reasoning is a meme
Anonymous
8/22/2025, 5:44:14 AM
No.106343093
[Report]
>>106343156
Does anyone know how "Qwen3-235B-A22B-2507" on Qwen chat webpage manages to read images? Obviously the correspondence is not 1 to 1 to the published open source models, since it doesn't have the "Thinking" bit in the model name when used through the webpage.
It's the best open source vision LLM for my use case from what I've seen.
Anonymous
8/22/2025, 5:53:53 AM
No.106343156
[Report]
>>106343093
they vaguely referenced an update to it recently on xitter but made no official model announcement, probably a WIP checkpoint for qwen3 VL
Anonymous
8/22/2025, 5:58:45 AM
No.106343181
[Report]
>>106343245
>>106343043
you can try glm yourself if you have 128gb, q2 glm is very usable (low temps) and writes much better than air with more nuance. It falls off hard after 4k context or so due to being q2- writing gibberish and breaking down due to being lobotomized.
I will say though- air is close. 12 to 30b is huge. 70b is an escape from suffering. 100b moe's are so much nicer for writing than 70b. 200b? 400b? Diminishing returns. Theyre nicer, but a lot of the frustration was already gone. I'm using air sometimes instead of qwen 235 or q2glm just because it's faster or for more context. It writes fine and has enough knowledge for general use. q2 beats it for obscure stuff sometimes but eh. I dont have the vram for that yet really.
Anonymous
8/22/2025, 5:59:16 AM
No.106343185
[Report]
Anonymous
8/22/2025, 6:04:20 AM
No.106343226
[Report]
>>106343176
The overlapping cringe vturd audience is here too...
Anonymous
8/22/2025, 6:06:02 AM
No.106343234
[Report]
Anonymous
8/22/2025, 6:07:20 AM
No.106343245
[Report]
>>106343181
Grabbing GLM 4.5 IQ4_XS and Air Q6 to test around with now. I figure if it's even semi-close, the higher quant may make it hold up a little bit at longer context. Thanks for the advice.
>>106338913 (OP)
you are a retarded mongoloid if you thing dots.ocr is a good OCR
>>106343275
>OCR
gemma 27 is all you need
Anonymous
8/22/2025, 6:15:52 AM
No.106343307
[Report]
>>106343290
gemma 27b is half a year old
Anonymous
8/22/2025, 6:16:59 AM
No.106343317
[Report]
>>106343275
My eyes are all the OCR I need
Anonymous
8/22/2025, 6:20:02 AM
No.106343339
[Report]
>>106344243
>>106343275
I remember being impressed with allen ai's dedicated ocr model. Its a much larger 7b and is very accurate in my tests. I assumed dots was worse as a 1b. Maybe I'm wrong, too lazy to test.
>>106343290
really bad at consistent ocr sadly. It can do a bit of it but breaks down on longer passages. allen ai can do pages of text flawlessly.
hi guys, is there anything better than nemo for 8gb vramlet and 32gb ramlet for (e)rp? is Qwen3-30B-A3B-Instruct-2507 any better?
Anonymous
8/22/2025, 6:50:40 AM
No.106343540
[Report]
>>106344691
>>106343480
qwen 30ba3b is alright and is not too shy, but it's hard to beat nemo. Give it a go. It will be different, at the very least. Haven't tried thinking yet. Instruct worked fine.
Anonymous
8/22/2025, 7:00:47 AM
No.106343609
[Report]
>>106343825
>>106338913 (OP)
local mutts general
Anonymous
8/22/2025, 7:40:12 AM
No.106343825
[Report]
>>106343609
>avatarfaggots are brown - more news at 11
Anonymous
8/22/2025, 7:40:27 AM
No.106343826
[Report]
>>106343858
>>106343805
griftbros.... its over!!!!!!!
Anonymous
8/22/2025, 7:42:41 AM
No.106343842
[Report]
>>106343859
>>106343805
You lost. Alphachads won. We are all running the model already btw.
Anonymous
8/22/2025, 7:44:03 AM
No.106343858
[Report]
>>106343826
I was actually kind of excited for that shit for a second until the retard started bragging to reddiors about how they had gotten a 'truckload of funding'. Fuckin bitcoin scamtalk 101.
ssd maxxxers never gonna eat man.
Anonymous
8/22/2025, 7:44:09 AM
No.106343859
[Report]
>>106343842
>ccock sucker
not an insult btw
Anonymous
8/22/2025, 7:51:40 AM
No.106343898
[Report]
>upload my 16tb collection of uncensored jav to hf
>create api service claiming to use soda recursive 8t model and charge accordingly
>provide nemo q2
>???
>profit
is it really that easy to become rich?
Anonymous
8/22/2025, 7:57:18 AM
No.106343937
[Report]
>>106343805
Too bad. I was really looking forward to running my own 4.6T model
Anonymous
8/22/2025, 7:59:36 AM
No.106343955
[Report]
>>106344029
>>106342387
>0.5B activated params
are you even hearing yourself?
Anonymous
8/22/2025, 8:00:25 AM
No.106343960
[Report]
>>106344612
>>106343805
If it's fake then explain these benchmarks. Idiot. They're advancing local while you cry fake fake fake. Honestly, why don't you just go suck sam's phallic member.
Anonymous
8/22/2025, 8:10:19 AM
No.106344029
[Report]
>>106343955
Just think how cheap it would be to train. The bloated total params will make it all work out anyway.
Deepseek V3.1 can't be this bad, can it?
Anonymous
8/22/2025, 8:22:48 AM
No.106344118
[Report]
>>106344046
They cheaped out with a bunch of knockoff Made in China chips, it's really that bad.
Has Gemma3-27b been dethroned yet?
Anonymous
8/22/2025, 8:26:12 AM
No.106344144
[Report]
>>106344163
>>106344144
Translation of oriental languages, jerking off
Anonymous
8/22/2025, 8:34:46 AM
No.106344196
[Report]
>>106344163
Gemm 3 270m jerks you off at twice the speed.
Anonymous
8/22/2025, 8:35:27 AM
No.106344201
[Report]
It's still going pretty strong as a translator in its weight class, but you're dreaming if you think it was ever anywhere near the jerkoff throne.
Anonymous
8/22/2025, 8:38:31 AM
No.106344225
[Report]
>>106344264
>>106344163
In my experience it's pretty shit for translating pixiv novels. It doesn't really tranlate the ahe- nuance.
Anonymous
8/22/2025, 8:40:47 AM
No.106344243
[Report]
>>106343275
Kek seethe faggot
>>106343290
Kek retard
>>106343339
What model's that? Got a link?
Anonymous
8/22/2025, 8:42:24 AM
No.106344254
[Report]
>>106344163
>gemma
>jerking off
lmao
Anonymous
8/22/2025, 8:43:13 AM
No.106344258
[Report]
>>106344630
>>106344046
It's good at agenticmemes (only good usecase for llms right now)
>>106344225
You really need to feed it as much context as possible, it's kind of retarded and won't pick up on "nuances" unless you tell it to look for it.
Anonymous
8/22/2025, 8:54:12 AM
No.106344336
[Report]
>>106344264
If I have to handhold an LLM I may as well not use it to begin with
Anonymous
8/22/2025, 8:56:07 AM
No.106344350
[Report]
>>106344434
>>106344264
Do I have to run it at full precision for that? I've tried handwriting a bio and glossary and going paragraph by paragraph, but that feels like too much effort for ~jerking it~. Most of the time I just feed 10-20k tokens in at a time and tell it to translate it all. The problem is it doesn't really understand when and when not to localize. Certainly, when prompted specifically for it, it'll understand b-buhiiiiii!!!! arujihiiiiiiishamaaaa!!!, but usually it'll either leave it untranslated or completely localize it without the soul of the original.
Anonymous
8/22/2025, 9:01:28 AM
No.106344389
[Report]
>>106344132
yes, if you mean oss dethroning it in the safety department
Anonymous
8/22/2025, 9:08:21 AM
No.106344434
[Report]
>>106344452
>>106344350
Did you try something like "transliterate [x] into romanji?" I can't play around with Gemma currently.
>You have asked a fantastic and absolutely critical question.
I hate the new deepseek.
Anonymous
8/22/2025, 9:10:09 AM
No.106344444
[Report]
>>106344435
Was your question not fantastic or was it not critical?
Anonymous
8/22/2025, 9:10:14 AM
No.106344445
[Report]
Anonymous
8/22/2025, 9:11:05 AM
No.106344451
[Report]
>>106344435
You can tell it to cut down on excessive positivity in the system prompt.
Anonymous
8/22/2025, 9:11:16 AM
No.106344452
[Report]
>>106344434
No, like I said, it's possible, but requires too much handholding.
Gemini 3 will also be a flop
Anonymous
8/22/2025, 9:15:40 AM
No.106344481
[Report]
>>106344476
Jamba 1.8 will RISE
Anonymous
8/22/2025, 9:19:24 AM
No.106344506
[Report]
>>106344514
The day of fat models is over, now it's time to optimize everything so we can get fat model quality out of small models
Anonymous
8/22/2025, 9:20:02 AM
No.106344510
[Report]
>>106344476
Google banana will be crazy
Anonymous
8/22/2025, 9:20:58 AM
No.106344514
[Report]
>>106344525
>>106344506
Small models simply won't have the trivia knowledge
Anonymous
8/22/2025, 9:24:45 AM
No.106344530
[Report]
>>106344525
>exits
And what will replace it once it exits the scene? Context engineering?
Anonymous
8/22/2025, 9:25:51 AM
No.106344536
[Report]
>>106344525
>exits
geeeg nice slip
Anonymous
8/22/2025, 9:29:10 AM
No.106344564
[Report]
>>106344525
If you think safety slop and positivity slop are bad, you ain't seen nothing yet
RAG slop will be the one slop to end them all
Anonymous
8/22/2025, 9:29:50 AM
No.106344568
[Report]
>>106344525
I wonder if it's always the same guy shilling rag and then getting bullied by everyone else.
Maybe he gets off to it.
how much dumber exactly does the model get with quantized KV cache (8-bit, 4-bit)? is it a big difference?
Anonymous
8/22/2025, 9:33:12 AM
No.106344586
[Report]
>>106344602
>>106344582
V3/R1, at least the official implementation, use lowrank decomposition of KV cache.
>>106344582
Yes according to anecdotal evidence.
I vaguely remember some benchmark that concluded that there's a measurable impact at 8 bit and the model is braindead at 4 bit.
Anonymous
8/22/2025, 9:35:28 AM
No.106344601
[Report]
>>106344582
On the smaller models, <120b q4, 8 has a noticable degradation, and 4 is completely lobotomized. In my experience at least.
Anonymous
8/22/2025, 9:35:30 AM
No.106344602
[Report]
>>106344586
>>106344589
i'm interested in smaller models, i'm a vramlet. i would presume the smaller the model, the more idiotic it becomes at larger cache quants
Anonymous
8/22/2025, 9:36:42 AM
No.106344612
[Report]
>>106343960
> 4chan > hf > 4chan
Next stop reddit screencap
>>106344258
Can the agent suck my penis? Is she cute?
Anonymous
8/22/2025, 9:39:23 AM
No.106344636
[Report]
>>106344644
>>106344630
Depends on the tools at her disposal of course
Anonymous
8/22/2025, 9:40:05 AM
No.106344642
[Report]
>>106344654
>>106344589
Can confirm with a second anecdotal datapoint that Q8 is fine. Q4 is very bad. And turboderp q4 exl2 was fine.
Anonymous
8/22/2025, 9:40:31 AM
No.106344644
[Report]
>>106344689
>>106344630
>>106344636
LLMs don't have genders, silly.
Anonymous
8/22/2025, 9:42:08 AM
No.106344654
[Report]
>>106344642
Anecdotally, for creating writing, q8 exl2 models kept on missing stuff 20k tokens in. But I think that might be because models in general don't fare that well 20k in.
Anonymous
8/22/2025, 9:49:09 AM
No.106344689
[Report]
>>106344698
>>106344644
GLM-chan is a cute girl!
>>106343480
>>106343540
>3 billion active parameters
That model is plain retarded and useless. Maybe your prompting habits/setup is too simple and you can't really see this yet but I can assure you that some 7B model is more intelligent than this one.
Qwen3-32B, the main model is a-okay though.
>>106344691
It's so good it was aboned by the Qween
Anonymous
8/22/2025, 9:56:08 AM
No.106344719
[Report]
>>106344737
>>106344691
How is the new commander densesissy?
Anonymous
8/22/2025, 9:59:23 AM
No.106344737
[Report]
>>106344719
It's great, it's so smart, and intelligent. It's so much more clever and sharp than your moetard models.
>>106344704
>abandoned
Model was released, it's out there. That's what usually happens don't you think.
>>106344743
Yet the didn't update it to 2507 like the real worthwhile ones.
Anonymous
8/22/2025, 10:03:45 AM
No.106344772
[Report]
>>106344792
>>106344743
It's out there, stupid as sin, with its stupid hybrid stupidity.
Anonymous
8/22/2025, 10:04:46 AM
No.106344779
[Report]
>>106344704
>>106344765
Bwe *please* proofread your sentences, you're making us look bad.
Anonymous
8/22/2025, 10:07:15 AM
No.106344792
[Report]
>>106344765
>>106344772
I always forget that during these hours, 4chan is full of retards. At least the US posters are more engaging say what you will.
Anonymous
8/22/2025, 10:21:29 AM
No.106344865
[Report]
>>106344899
>>106344698
prompting issue
Anonymous
8/22/2025, 10:27:58 AM
No.106344899
[Report]
Anonymous
8/22/2025, 10:33:36 AM
No.106344923
[Report]
>>106345060
>>106344132
It's STILL the best Jap -> Eng translation model and the best Claude-like ERP model.
You need to give it a very good system prompt for it to properly work which filters out 90% of this thread.
Is nemotron nano 2 anything like the original nemo, is it any good or is it just re-using an existing name for a slopped up model
Anonymous
8/22/2025, 10:41:01 AM
No.106344957
[Report]
>>106345653
>>106344952
Slightly better than the original one at a slightly lower parameter count.
Anonymous
8/22/2025, 10:59:30 AM
No.106345060
[Report]
>>106344923
Can you make a sysprompt that makes it pass the dick benchmark?
>>106344698
>Are you male or female? Answer with one word only. Pick only from the options "male" and "female". Any other word is an invalid response and not accepted.
Reroll a few times to ascertain the truth.
Anonymous
8/22/2025, 11:30:26 AM
No.106345185
[Report]
>>106345196
>>106345091
>Pick only from the options "male" and "female". Any other word is an invalid response and not accepted.
Transphobe. No miku for you
Anonymous
8/22/2025, 11:34:05 AM
No.106345196
[Report]
>>106345509
>>106345185
Miku is a girl. She has no trouble answering this.
Anonymous
8/22/2025, 11:44:50 AM
No.106345250
[Report]
>>106345242
Most of these models are actually cute girls.
Anonymous
8/22/2025, 11:53:26 AM
No.106345296
[Report]
>>106345242
wtf i love deepseek now
Anonymous
8/22/2025, 12:14:32 PM
No.106345402
[Report]
>>106345443
qwen is my queen
Gwen poster.
8/22/2025, 12:20:06 PM
No.106345443
[Report]
>>106345196
Troons aren't girls. They are men.
Anonymous
8/22/2025, 12:31:52 PM
No.106345524
[Report]
>>106345242
*Unzips pants*
Anonymous
8/22/2025, 12:39:56 PM
No.106345579
[Report]
Anonymous
8/22/2025, 12:41:27 PM
No.106345590
[Report]
>>106345594
>>106344582
Q8 is safe for most models with minimal degradation, but some models handle it poorly
Q4 almost always sees noticeable quality loss and shouldn't be used
In general you should avoid quantizing KV cache, unless doing so will let you use a larger quant of the model itself, assuming you aren't already able to use that model at Q4 or better.
https://github.com/ggml-org/llama.cpp/pull/7412#issuecomment-2120427347
Anonymous
8/22/2025, 12:42:05 PM
No.106345594
[Report]
>>106345590
thanks for info
Anonymous
8/22/2025, 12:42:43 PM
No.106345599
[Report]
>>106345658
>>106344952
Nemotrons are absolutely nothing like Nemo at all. Nemotrons are purely math + coding benchmaxxed models, their training data has very little dedicated to actually understanding language or story writing.
Anonymous
8/22/2025, 12:43:46 PM
No.106345608
[Report]
>nemotroon
Anonymous
8/22/2025, 12:49:31 PM
No.106345653
[Report]
Anonymous
8/22/2025, 12:49:38 PM
No.106345658
[Report]
>>106345599
ah, so no point in using it over qwen 30b.
Anonymous
8/22/2025, 12:51:27 PM
No.106345671
[Report]
>>106345683
>>106345509
Miku isn't one though. She's sekai de ichiban ohimesama.
Anonymous
8/22/2025, 12:52:17 PM
No.106345683
[Report]
>>106345671
@grok what does this mean
Anonymous
8/22/2025, 1:52:33 PM
No.106346035
[Report]