>>106355930 (OP)
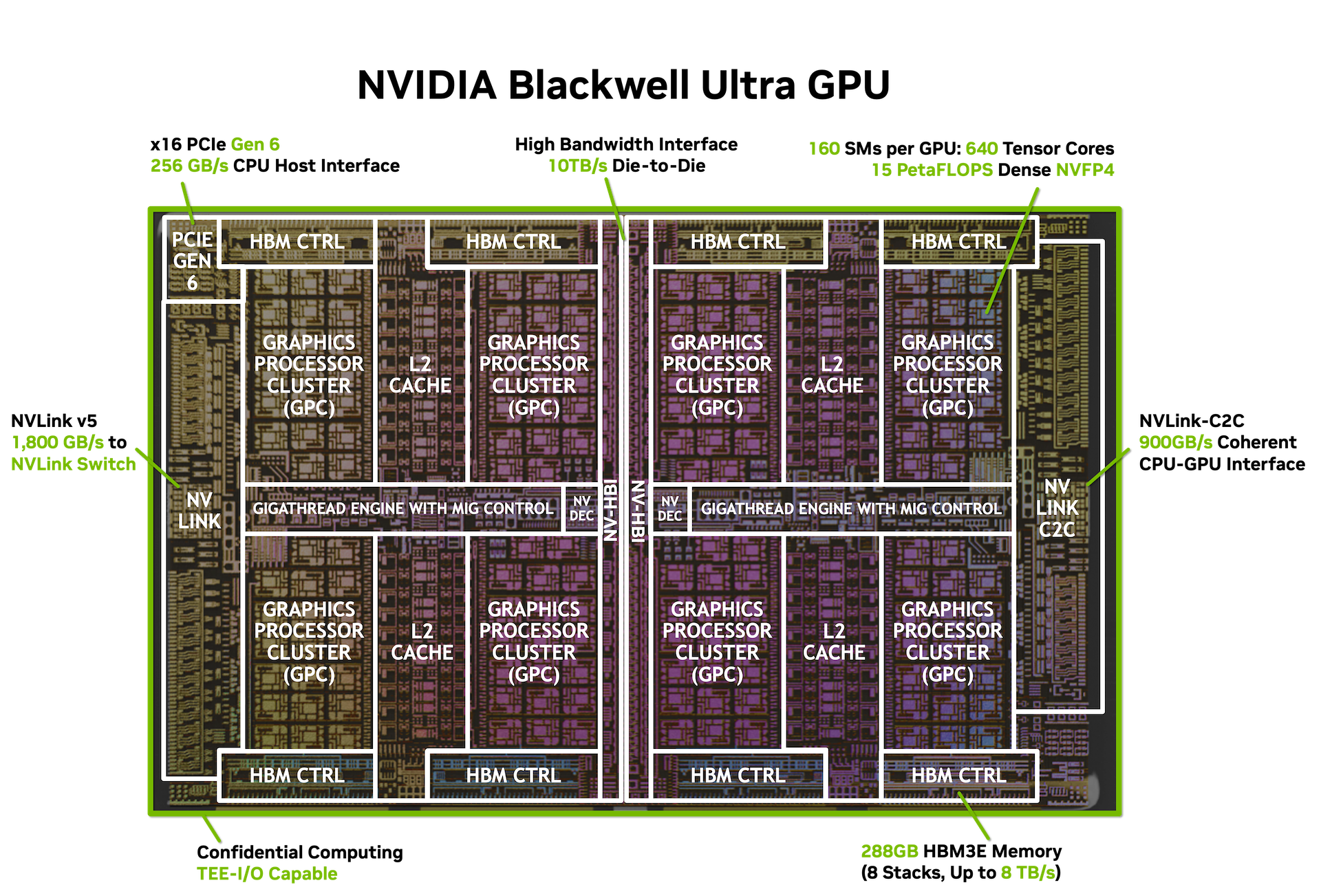
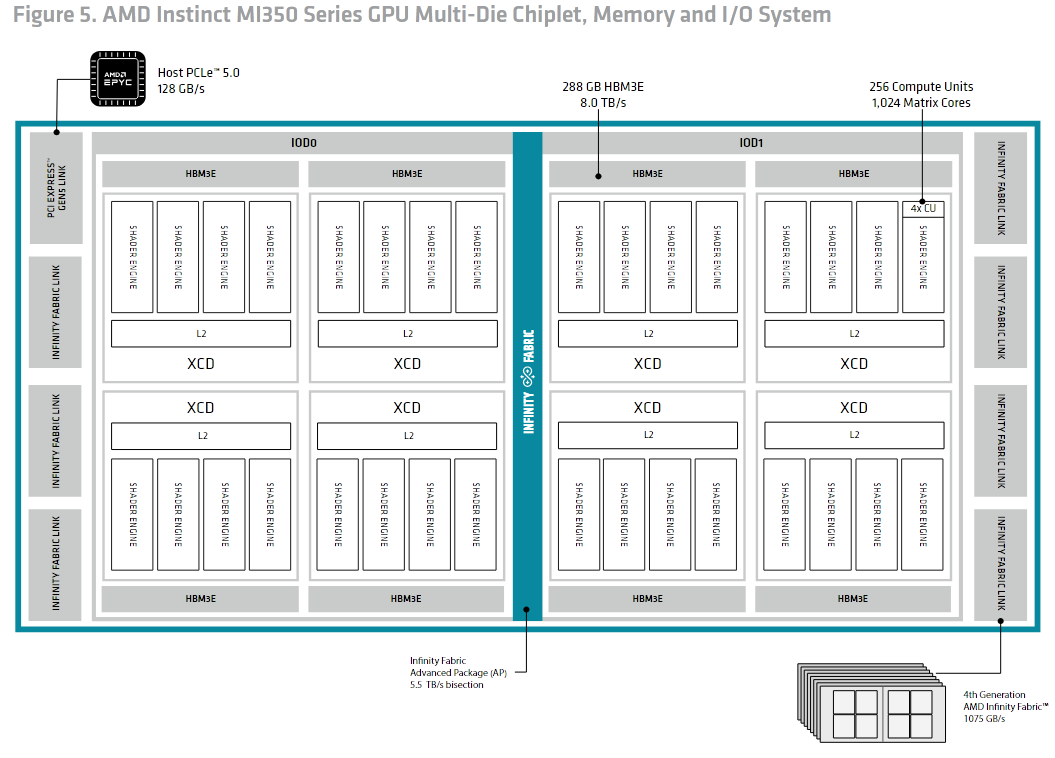
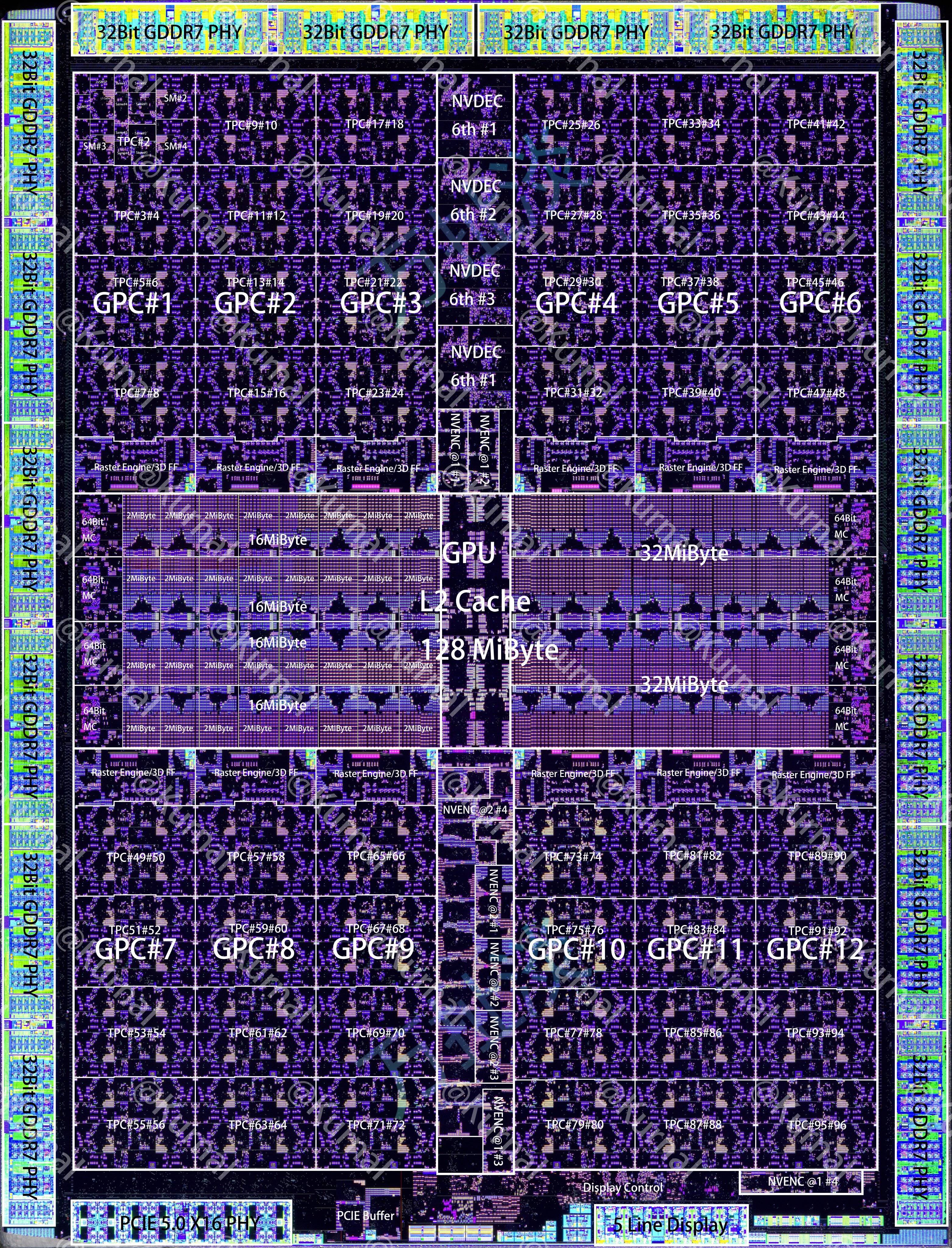
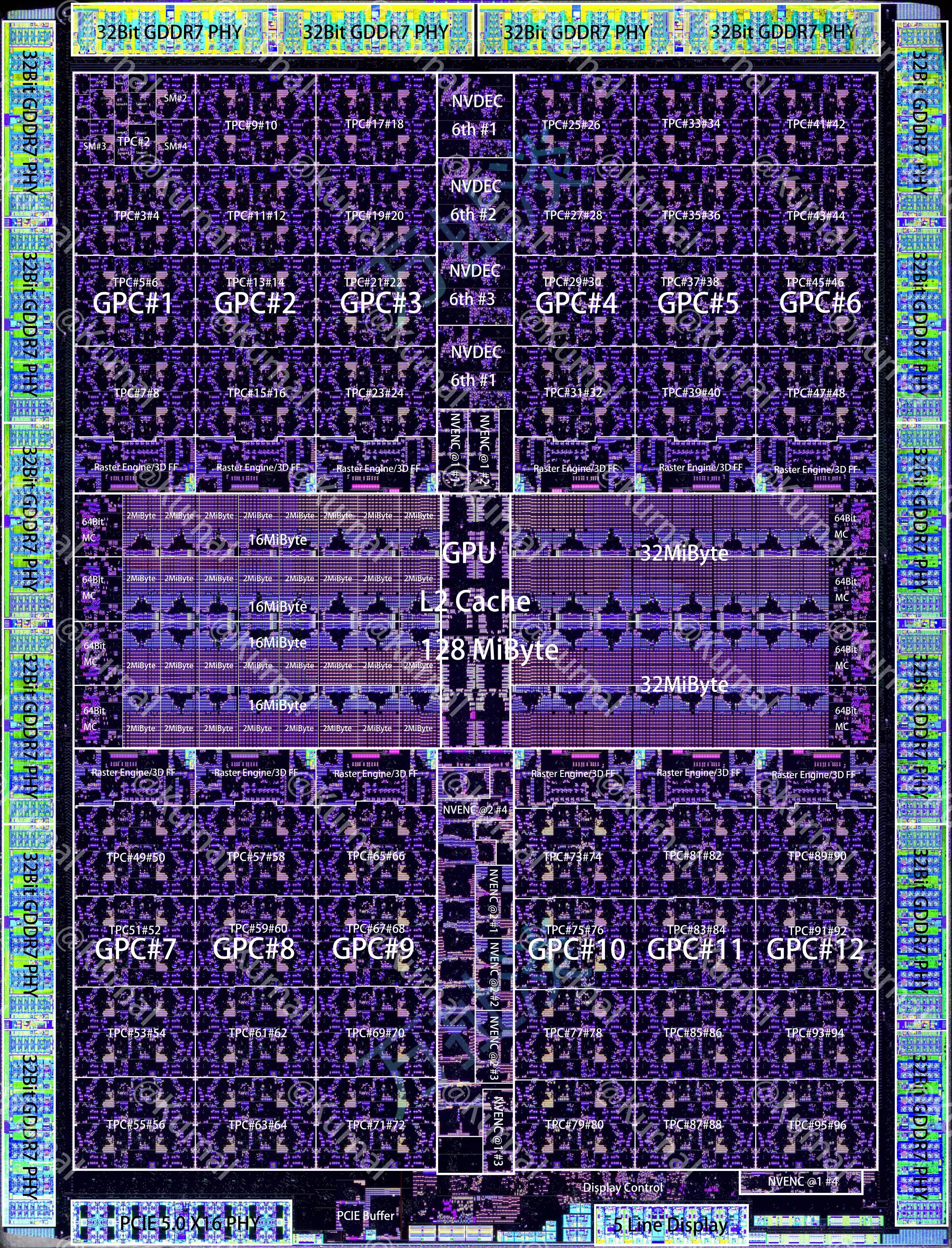
I was surprised to see 5090's theoretical BF16 TFLOPs at just 209.5. That's not even 10% of the server Blackwell (B200 is 2250, and GB200 is 2500). B200 costs around $30-40k per GPU, so they are pretty close in performance per dollar.
Starting with 4090, NVIDIA limits the performance of tensor cores on gaming cards, specifically for ops that might be used in ML training. FP8 and FP16 matmuls run at full speed if accumulating in FP16 (I've never seen anyone use this), but only half speed when accumulating in FP32. This restriction is not present for lower precision matmuls like FP4, and is removed entirely on the workstation-class cards like RTX Pro 6000.
It doesn't seem worth it to use NVIDIA gaming cards as a "cheaper FLOPs" alternative anymore (e.g. diffusion models could have been cheaper to run on 3090 than A100). They are generous with memory bandwidth though, nearly 2TB/s on 5090 is amazing!