/lmg/ - Local Models General
Anonymous
8/25/2025, 10:44:44 AM
No.106376310
[Report]
>>106379859
►Recent Highlights from the Previous Thread:
>>106369841
--Paper: Mini-Omni-Reasoner: Token-Level Thinking-in-Speaking in Large Speech Models:
>106374844 >106374908
--Papers:
>106374970 >106375016
--Simplified sampling approach for creative roleplay with focus on temp and top_p:
>106370179 >106370705 >106373210 >106373293 >106373331 >106373366 >106373413 >106373426 >106373438 >106373482 >106373502
--High-end GPU adoption challenges in local AI rigs due to cost and diminishing VRAM returns:
>106371735 >106371745 >106371826 >106371838 >106371851 >106371927 >106372000 >106372028 >106372031 >106372038 >106372044 >106372053 >106372062 >106372068 >106372082 >106372169 >106372240 >106373162 >106372102 >106372287 >106372300 >106372328
--AI-driven resurrection of deceased loved ones and its psychological fallout:
>106370503 >106370524 >106370541 >106370647 >106370726 >106370748 >106370761 >106373760 >106370771 >106370792 >106370823 >106373701 >106373711
--Mistral Medium not available locally; alternatives for language understanding tasks:
>106374576 >106374590 >106374593 >106374595 >106374607 >106374617 >106374653 >106374695
--Vibe coding pitfalls and the need for human-led AI-assisted development:
>106373434 >106373517 >106373623 >106373642 >106373883 >106373906 >106373671
--Running GLM Air with limited VRAM using MoE offloading and quantization:
>106370104 >106370190 >106370221 >106370225 >106370549 >106370632 >106370728 >106374896
--Base models reproduce text verbatim; instruct tuning enables long-form generation without safety filters:
>106375534 >106375543 >106375581 >106375589 >106375642 >106375649 >106375717
--Intel B60 Dual GPU pricing and practicality skepticism amid market skepticism:
>106374061 >106374079 >106374112 >106374146 >106374208 >106374162
--Miku (free space):
>106370550 >106373204 >106374299 >106374529 >106374947
►Recent Highlight Posts from the Previous Thread:
>>106369846
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
8/25/2025, 10:51:26 AM
No.106376343
[Report]
>>106376759
>still no dots VLM GGUF
damn nigga that's crazy
Anonymous
8/25/2025, 11:00:46 AM
No.106376381
[Report]
k2 reasoner...
Anonymous
8/25/2025, 11:12:48 AM
No.106376449
[Report]
mijeets go back >>>/v/718973309
Anonymous
8/25/2025, 11:25:42 AM
No.106376539
[Report]
been running nemo 12b on 16gb vram/32gb ram machine for a while, I liked it but sometimes hoped it's a bit smarter, what models should I try next? Or should I upgrade my machine?
Anonymous
8/25/2025, 11:59:01 AM
No.106376743
[Report]
>>106376607
For me, there is nemo and r1. Everything else is somehow unintelligent. If your mobo supports ddr5 I suggest that you max out ram and run this quant
https://huggingface.co/unsloth/DeepSeek-R1-GGUF with ik_llama
Anonymous
8/25/2025, 12:01:43 PM
No.106376759
[Report]
>>106376343
Dots is no good. I haven't found any open source model that works for my use case (cropping parts of documents and finding the coordinates of GUI elements). The only open source adjacent model that is at the level of proprietary models is Qwen3's multimodal input which has not been publicly released.
Anonymous
8/25/2025, 12:03:05 PM
No.106376777
[Report]
>>106376607
Smaller quants of Mistral Small and maybe Gemma 27b
>He/She x, not to y, but to z
>He/she x- no she/he y
When did this start become so prominent? Just say the thing without wasting more tokens on fluff wtf
Anonymous
8/25/2025, 12:04:45 PM
No.106376790
[Report]
>>106376956
Anonymous
8/25/2025, 12:07:19 PM
No.106376804
[Report]
>>106376910
>>106376781
Anon, most modern models, especially the small ones have barely seen any fiction. It doesn't make benchmark bars go up, you see. As a result this is their understanding of fiction, which probably comes from synthetic instruction data where the "user" asks it to analyze or compose a story.
Anonymous
8/25/2025, 12:22:30 PM
No.106376910
[Report]
>>106377734
>>106376804
Nah it's ao3 trash purple prose
is qwen3-30b-a3b really worse than nemo for (e)rp?
Anonymous
8/25/2025, 12:29:50 PM
No.106376956
[Report]
>>106376991
>>106376790
tfw using qwen3-4b as main model
Anonymous
8/25/2025, 12:34:08 PM
No.106376991
[Report]
>>106376956
How friggin bad is your hardware, man?
Anonymous
8/25/2025, 12:34:48 PM
No.106376995
[Report]
>>106376941
it does spit out more refusals
KHBB7UNOFCLNNVJQONDZMDNALERW426Z
Anonymous
8/25/2025, 12:39:14 PM
No.106377033
[Report]
>>106377082
>>106376941
Yes, it's smarter than nemo but it's still chinese, and all chinese models are benchmaxxed.
>>106377025
I downloaded it back then but I have no idea what I'm going to do with it.
Anonymous
8/25/2025, 12:46:46 PM
No.106377082
[Report]
>>106377033
it's ok, Drummer will fix it
Anonymous
8/25/2025, 12:47:37 PM
No.106377087
[Report]
>>106377078
Use a small model to score each story
Use a larger model to score top stories
Post the best stories here
Anonymous
8/25/2025, 12:50:11 PM
No.106377103
[Report]
>>106377078
Same. Hoarding datasets can't never be a waste though
Anonymous
8/25/2025, 12:51:28 PM
No.106377112
[Report]
>>106377156
Got kittentts working on my stuff. Nobody cares, but I like making them do funny noises.
>https://voca.ro/1aKZIAWJasjj
Anonymous
8/25/2025, 12:57:16 PM
No.106377156
[Report]
>>106377178
>>106377078
>>106377025
magnet:?xt=urn:btih:KHBB7UNOFCLNNVJQONDZMDNALERW426Z&dn=&tr=udp%3A%2F%2Ftracker.openbittorrent.com%3A80&tr=udp%3A%2F%2Fopentor.org%3A2710&tr=udp%3A%2F%2Ftracker.ccc.de%3A80&tr=udp%3A%2F%2Ftracker.blackunicorn.xyz%3A6969&tr=udp%3A%2F%2Ftracker.coppersurfer.tk%3A6969&tr=udp%3A%2F%2Ftracker.leechers-paradise.org%3A6969
>152GB
What am I downloading?
>>106377078
https://archive.org/details/ao3_mirror_super_final
Download this one, it has >20m stories while the one you have is 12.6m. Interestingly, ao3 itself only claims to have 17m.
Anonymous
8/25/2025, 1:00:15 PM
No.106377178
[Report]
>>106377247
>>106377156
sounds fine when it's a little slower, keep it up.
Also is there any models with Teen titan's raven's voice and Gwen's voice?
>>106377173
An incomplete ao3 dump, see
>>106377175
Anonymous
8/25/2025, 1:00:42 PM
No.106377183
[Report]
>>106377223
>>106377175
>not downloading ao3_mirror_ultimate_mega_ultra_super_final
>>106377181
I guess this?
https://archiveofourown.org/
152GB (or 785.5G for your link) of fanfiction
toppest of keks
Anonymous
8/25/2025, 1:05:50 PM
No.106377220
[Report]
>>106377443
>>106377195
Yeah it's insane, entire english wiki text is less than 40gb iirc. and these are compressed.
Anonymous
8/25/2025, 1:06:53 PM
No.106377223
[Report]
Anonymous
8/25/2025, 1:10:42 PM
No.106377247
[Report]
>>106377283
>>106377178
There's some weird noises near the end of the sentences, but I think that's my fault. I need to do more pre-processing of the strings before sending them to espeak for phonemization.
No idea about voices other than the 8 included in voices.npz. I suppose that the "training" method for kokorotts would work for this one as well. Each voice is just 256 floats, unlike kokoro's 256*511. Fewer params to tune, faster convergence.
Anonymous
8/25/2025, 1:11:38 PM
No.106377253
[Report]
>>106377268
GUYS
UNSLOTH JUST UPDATED GPTOSS GGUFS
Anonymous
8/25/2025, 1:14:07 PM
No.106377268
[Report]
>>106377253
I hope he added bbc
Anonymous
8/25/2025, 1:15:09 PM
No.106377283
[Report]
>>106377339
>>106377247
Does this have arpabet support?
Anonymous
8/25/2025, 1:21:56 PM
No.106377338
[Report]
>>106377359
Anonymous
8/25/2025, 1:21:57 PM
No.106377339
[Report]
>>106377283
Nope. I didn't know about that enconding. Now it just uses whatever espeak gives me back (or what i inject) and translate those to the token ids used by the model (which are almost identical to kokorotts). If there's a 1:1 equivalency, I suppose i could add a little translator.
What's the best model for coding i can fit on 12gb vram + 64gb ram nowadays ?
Slop no nope?
> Cook liked touching people. Really liked it. He would hug any fan who asked, and kiss them on the cheek, and let them cry on him. He'd hug reporters, too, and he'd pick up small children, like he wasn't scared he was going to drop them, and he'd get into contortions to hug people in wheelchairs. He'd press himself up against fences and let people touch his beard and once Archie saw him letting this girl nuzzle his cheek, and okay, so she was a pretty cute girl, but she was a total stranger!And sometimes people put their hands on his ass, and it was so not an accident, even if some of them pretended it was, like, oh, wow! I didn't realize I had my hand on your butt. When it happened to him, Archie always wanted to jump a foot away and also be like, hello, what did you think it was! But Cook just grinned and didn't say a thing, and when they had walked away from the fans and were inside the stadium or whatever, he would still be grinning, and sometimes he would actually sort of jump up and down in the hallway and yell, "Whoo!" and say, totally serious, "This is amazing." And if people had been really grabby, he'd just roll his head back and forth and grin at Archie and grip him by the shoulder and shake him a little and say, "Man, is this ridiculous or what?" What, totally what, Archie always wanted to say. He liked the bodyguards, because they pushed people away before they could do that kind of stuff to him, as much. Cook usually made his bodyguards stay back—probably, Archie thought a little meanly, because they cramped his style of letting everyone grope him.And if you were around him enough, like, for instance, if you were his co-star, and you did a whole bunch of press with him, then he would get really used to you and this kind of switch would flip where you weren't so much allowed in his personal space—anyone and everyone was allowed in his personal space—as you became part of his personal space.
Anonymous
8/25/2025, 1:25:07 PM
No.106377359
[Report]
>>106377338
May be useful to study ai slop
Anonymous
8/25/2025, 1:26:29 PM
No.106377370
[Report]
>>106377546
>>106377358
PURE SOUL—i wish all models were like this
Anonymous
8/25/2025, 1:28:02 PM
No.106377381
[Report]
>>106377546
>>106377358
Model used and prompt?
Anonymous
8/25/2025, 1:28:11 PM
No.106377382
[Report]
>>106377078
the fact that a fanfic site is the most famous nsfw dataset makes me sad, no wonder all the models are completely sloppified
Anonymous
8/25/2025, 1:30:49 PM
No.106377402
[Report]
>>106377546
>>106377358
You can see the repetition penalty fall apart in real time. Impressive
>>106377025
What exactly are they bitching about?
Anonymous
8/25/2025, 1:31:27 PM
No.106377407
[Report]
>>106377354
Glm 4.5 air maybe
Anonymous
8/25/2025, 1:32:31 PM
No.106377411
[Report]
>>106377504
>>106377406
Huggingface not erasing the dataset fast enough
>>106377406
There was a comment by someone who said they don't want AI trained on stories they wrote to cope with rape.
I glad to know that the smut my models write is based on real experience.
Anonymous
8/25/2025, 1:36:45 PM
No.106377435
[Report]
Anonymous
8/25/2025, 1:37:44 PM
No.106377443
[Report]
>>106377472
>>106377220
>>106377195
>>106377181
>>106377175
>>106377078
Have y'all taken a look at this?
https://huggingface.co/datasets/mrcuddle/NSFW-Stories-JsonL
This one is apparently composed of rp sessions ripped from a site dedicated to RP with other users.
Anonymous
8/25/2025, 1:39:01 PM
No.106377449
[Report]
>>106377421
>Me knowing people out there are trying their hardest to make my rape experience as immersive as possible
>>106377443
I'd unironically prefer discord logs over these
>>106377175
>ao3
will this really make my AI models write better porn?
Anonymous
8/25/2025, 1:46:00 PM
No.106377500
[Report]
>>106377472
Private 1 on 1 DM logs are what machine learning data is sorely missing enough of. But it really needs to see trillions of tokens of that shit during pretraining.
Anonymous
8/25/2025, 1:46:21 PM
No.106377504
[Report]
>>106377520
>>106377411
>erased
For what reason?
>>106377472
What are some better sources your propose?
Anonymous
8/25/2025, 1:47:05 PM
No.106377509
[Report]
>>106377518
I've accepted that LLMs cannot write good prose for shit. I now just use them to help flesh out ENF scenarios and wank to those directly with my imagination.
I have ascended up an abstraction layer.
Anonymous
8/25/2025, 1:47:47 PM
No.106377517
[Report]
>>106377491
You're not the right audience
Anonymous
8/25/2025, 1:47:50 PM
No.106377518
[Report]
>>106377543
>>106377509
>unironic wiki double space and usage of word wank
we got a live one boys.
>>106377504
It gets massreported for copyright whenever it appears and the comment section is flooded with fanfiction "authors" getting really mad
Anonymous
8/25/2025, 1:50:27 PM
No.106377545
[Report]
>>106377520
But the New York district court or whatever ruled training is fair use. And HF is also headquartered in New York.
Anonymous
8/25/2025, 1:50:37 PM
No.106377546
[Report]
>>106377402
>>106377381
>>106377370
This is the first entry from the torrent in
>>106377173
>>106372503
>guy works on llms what do we send him?
>rig with 4x rtx pro 6000?
>wtf man ur outta ur mind, a 5090 is plenty
Anonymous
8/25/2025, 1:51:23 PM
No.106377551
[Report]
>>106377583
>>106377520
Their shit was copyrighted in the first place?
Anonymous
8/25/2025, 1:52:19 PM
No.106377556
[Report]
>>106377666
>>106377550
>a 5090 is plenty
And they still can't muster even that much.
Anonymous
8/25/2025, 1:53:07 PM
No.106377562
[Report]
>>106379672
>>106377543\
>I'm British
oh no
oh no no no no no
Anonymous
8/25/2025, 1:53:48 PM
No.106377569
[Report]
>>106377666
>>106377550
They're probably doing it because forever ago he called out the fact that the desktop blackwell was stripped down from the enterprise version (as far as instruction pipelines goes).
Anonymous
8/25/2025, 1:54:27 PM
No.106377574
[Report]
>>106377543
do you have wanking loicense sir?
Anonymous
8/25/2025, 1:54:34 PM
No.106377579
[Report]
>>106377600
Ray whispers it to Stella's collarbone, to her left breast, to her right hip. He's been saying it for weeks now, ever since the first time they ... and Stella has always been shocked, every time, and mumbled an acknowledgement or repeated the words back like an echo. Tonight, though -- and maybe it's the soft, secret smile that plays on his lips while he speaks the words, but suddenly she's possessed by an urgent, desperate need to know.
"Why?" she asks. The note of desperation in her voice is jolting, unnerving. Embarrassing. "Why do you love me?"
The question seems to catch him off guard, somewhere around her shoulder. He pauses, kisses her there. Licks his lips and appears to consider an answer.
"Because you're beautiful," he says quietly. "Because you're amazing." His lips moving against her arm send a shiver through her, deep into her belly, where his hand strokes invisible patterns across her skin.
"I guess ... I guess because you let me."
She cards her fingers through his hair, and wonders what would happen if she stopped letting him.
>>106377551
All text has natural copyright retard san.
By virtue of having being authored this post is copyrighted.
Anonymous
8/25/2025, 1:56:29 PM
No.106377593
[Report]
>>106377599
internvl3.5-241b-a28b.gguf?
Anonymous
8/25/2025, 1:57:20 PM
No.106377599
[Report]
>>106377593
local claude just dropped
Anonymous
8/25/2025, 1:57:21 PM
No.106377600
[Report]
>>106377608
>>106377579
Evaluation
This is a remarkably strong and psychologically dense piece of writing. It uses a moment of physical intimacy to explore a deep, unsettling emotional landscape. Its primary strength lies in its subtext and its ability to create a complex character portrait of Stella in very few words.
Strengths:
Economical Prose: The language is clean, direct, and purposeful. There are no wasted words. Phrases like "whispers it to Stella's collarbone, to her left breast, to her right hip" are both intimate and rhythmic, establishing the scene's physical reality without being overly descriptive.
Psychological Depth: The piece excels at showing, not telling. We understand Stella’s insecurity not because the author states it, but because she has always been "shocked" by his declaration of love and can only repeat it "like an echo." Her sudden, "urgent, desperate need to know" is a powerful turning point, revealing a dam of insecurity breaking.
Powerful Dialogue: The dialogue is sparse but carries immense weight. Ray's initial answers ("Because you're beautiful," "Because you're amazing") are deliberately generic. They are the expected, safe answers, which makes his final, more honest answer so much more impactful.
Thematic Ambiguity: The line, "I guess ... because you let me," is the core of the piece's artistic merit. It's brilliant in its ambiguity. It could be interpreted in several ways:
Tenderly: "You opened yourself up to me; you allowed me into your life and heart."
Sinisterly: "Because you are permissive; you don't challenge me; you are easy to love."
A Confession: "I need to be with someone who will let me love them, because of my own baggage."
Anonymous
8/25/2025, 1:57:36 PM
No.106377602
[Report]
>>106377606
>>106377583
I have read your post and updated my neurons based on its content.
Whatcha gonna do about it, faggot?
Anonymous
8/25/2025, 1:57:43 PM
No.106377603
[Report]
>>106377491
If you are a fujo.
Anonymous
8/25/2025, 1:58:16 PM
No.106377606
[Report]
>>106377602
Nothing because I'm not a delusional copyright fag and agree that machine learning data is fair use.
Anonymous
8/25/2025, 1:58:22 PM
No.106377608
[Report]
>>106377600
The writing doesn't give us the answer, forcing the reader to engage with the possibilities.
The Final Line: "She cards her fingers through his hair, and wonders what would happen if she stopped letting him." This is a fantastic, chilling conclusion. It shows that Ray's answer, regardless of his intent, has fundamentally shifted Stella's perception of their relationship. She moves from a passive recipient of love ("letting him") to considering her own agency and power. It introduces a note of profound tension and dread into an otherwise tender scene.
Weaknesses:
Within this short snippet, there are virtually no technical weaknesses. The only potential critique is that its effectiveness relies heavily on the reader's ability to pick up on subtext. A reader looking for a straightforward, sweet romance scene might misinterpret it or find it unsatisfying. However, this is more a feature of its style than a flaw.
Conclusion
This is not just competent writing; it's artistically sophisticated. It uses a simple question to pry open the complex and often fragile dynamics of a relationship, touching on themes of self-worth, agency, and the very nature of love. The final line elevates the entire passage from a good romantic scene to a truly thought-provoking piece of character drama.
Based on its psychological depth, tight prose, and powerful use of subtext, this is high-quality writing.
Rating: 9/10
>>106377506
There are some on huggingface. I think starting with pygmalion dataset would be a good start
Anonymous
8/25/2025, 2:06:47 PM
No.106377663
[Report]
>>106377648
Oh yes. Random ESLs interacting with the 5 dollar footlong is everything we have been missing all along.
llama.cpp CUDA dev
!!yhbFjk57TDr
8/25/2025, 2:06:58 PM
No.106377666
[Report]
>>106377702
>>106377556
They asked me for an address to send the GPU to so I think it's reasonable to assume that I will actually receive something.
I added the "supposedly" because I was first contacted in March and the whole process seems poorly organized.
In any case, I'm primarily interested in "cheap" hardware anyways so I have enough of a budget to just buy what I need myself (especially since those expenses are tax deductible for me).
>>106377569
I don't think what I write on /lmg/ was or is relevant in that regard.
>>106377648
Why aren't people just using good models to rephrase fitting fanfics in rp format?
Anonymous
8/25/2025, 2:11:49 PM
No.106377702
[Report]
>>106377722
>>106377666
>I don't think what I write on /lmg/ was or is relevant in that regard.
Breh. This entire website is glowed to shit. Aicg unwittingly feeds them with an endless supply of adversarial prompts to train on under the guise of "stolen key" proxy and millions of dollars worth of misappropriated API usage every day that somehow hasn't lead to a whisper from law enforcement.
And as much as I shit on you sometimes you're one of the single most important devs when it comes to open source ai.
Jensen probably has a camera in your bathroom so he can watch every time you take a piss.
Anonymous
8/25/2025, 2:12:40 PM
No.106377708
[Report]
>>106377767
>>106377700
Are you gonna pay for it? No? Why aren't you training it yourself?
Anonymous
8/25/2025, 2:14:27 PM
No.106377722
[Report]
>>106377702
>hasn't lead to a whisper from law enforcement
wasn't there a microsoft lawsuit or something for a bit
>>106377700
The "good models" and question still suffer from slopified outputs, so any "enhancements" they implement will either do negligible benefits, or make the slop even worse. The best solution it's to simply create SFT and DPO data sets on REAL, human written stories that are curated and formatted correctly. The only synthetic content that should ever touch these kinds of data sets are hypothetical "rejected" responses in DPO data sets, and also maybe even the system prompts in the SFT data set if your pipeline is written well enough to create context-aware system prompts
>>106376910
desu, I'm only a few billion tokens in to training a base model on ao3 and it's already full of shivers. I kinda hope it mellows out after a few billion more but it seems pretty hopeless.
Anonymous
8/25/2025, 2:17:02 PM
No.106377741
[Report]
>>106377841
>>106377734
Post training graphs. If it's not converging then there's something wrong with your data set or training config
Anonymous
8/25/2025, 2:17:39 PM
No.106377746
[Report]
>>106377789
>>106377734
ao3 is full of shivers. it will only get worse
Anonymous
8/25/2025, 2:19:27 PM
No.106377761
[Report]
Speaking of slop I found an old backup that I made of all the cringe character cards I used to use and decided to do a pull with Qwen3-4B-Thinking just for old time's sake since I already had the model loaded on my server.
Emergent slop.
Anonymous
8/25/2025, 2:20:00 PM
No.106377767
[Report]
>>106377781
>>106377708
Actually I am preparing to begin experimenting. It shouldn't be expensive even if you are going to pay for something like r1 api but I'm sure you can test decently with local models too.
>>106377726
Are you sure that you can't prompt around those enhancements by for example asking for sentences to be unaltered? You can even write custom sampler that disallows any sequence absent in a given paragraph.
Anonymous
8/25/2025, 2:21:28 PM
No.106377780
[Report]
>>106377648
I want to try a "badllama" finetune of base gemma3 12b using
https://huggingface.co/datasets/braindao/solidity-badllama-v2 and unsloth. Is the "negative llama" dataset out in the wild somewhere too?
Anonymous
8/25/2025, 2:21:50 PM
No.106377781
[Report]
>>106377818
>>106377767
>asking for sentences to be unaltered?
What? I thought you said here
>>106377726
That we should use "good" models to rewrite existing text in order to be better. I don't know why in the world you think that's even remotely a good idea.
Anonymous
8/25/2025, 2:22:42 PM
No.106377789
[Report]
>>106377804
>>106377746
>>106377734
ao3_1-100000.jsonl, 1.66GB
303 582 469 words
37 412 shivers
>>106377789
There's other arguments as to why the ao3 dataset would be poisonous as well. For example people will probably insert a lot of their "fanon" into mainstream IP inspired RPs and open models are bad enough at pop-culture trivia to begin with.
Anonymous
8/25/2025, 2:26:15 PM
No.106377809
[Report]
>>106377812
are there any LLM developments for 16GB vramlets or will we be stuck with nemo forever?
Anonymous
8/25/2025, 2:26:55 PM
No.106377812
[Report]
>>106377809
Upgrade your ram and run air.
Anonymous
8/25/2025, 2:27:24 PM
No.106377815
[Report]
>>106377843
>>106377804
I mean, I don't particularly care about trivia. I want a good writing style. Posted an extract from the very first story above, and it seems to be good.
Anonymous
8/25/2025, 2:27:29 PM
No.106377818
[Report]
>>106377892
>>106377781
You are right, I said rephrase. I meant restructure, to arrange a story into multi turn chat. And the model has to be smart to determine if a story can be arranged like this.
Anonymous
8/25/2025, 2:28:12 PM
No.106377827
[Report]
>>106377804
>open models are bad enough at pop-culture trivia to begin
Yeah most of them can't even list all the adam sandler movies without making up new ones like jack and Jill christmas special
Don't mess with a zohan 2
Anonymous
8/25/2025, 2:30:11 PM
No.106377841
[Report]
>>106378307
>>106377741
it is converging alright, its just full of shivers.
>>106377804
I noticed its very respectful to get consent and uses condoms often...
>>106377815
Honestly the anon that wanted discord logs is onto the right track. Slop emerges because there's not enough casual writing, framed as RP, in the dataset. So when it comes to fictional narratives all it sees is bulbous purple prose everywhere. Shivers running down spines, voices barely above her penis, etc. The more you curate data the worse the model gets. It needs the good and the bad because what you want is something in the middle.
Anonymous
8/25/2025, 2:34:32 PM
No.106377880
[Report]
>>106377907
>>106377506
it is time to redeem vns, video game scripts, anime scripts, cartoon scripts and tv show/movie scripts as they all have multi turn conversations with speaker names as well
i will generate the logo for the collecting, extracting and cleaning efforts
though the real problem seems to be that everyone is reducing/purging fictional stuff in their datasets on purpose to get that sweet +0.1% on a math&science benchmark
Anonymous
8/25/2025, 2:34:37 PM
No.106377882
[Report]
>>106378420
>>106377843
0.012% of words being shivers is not that bad.
Anonymous
8/25/2025, 2:35:33 PM
No.106377892
[Report]
>>106377904
>>106377818
>restructure, to arrange a story into multi turn chat.
In that case that should theoretically work. That's exactly what the data set I linked here is:
>>106377332
Used this script:
https://files.catbox.moe/91eyke.py
To turn this data set:
https://huggingface.co/datasets/mrcuddle/NSFW-Stories-JsonL
Into this:
>>106377332
I'll need to find time to actually initiate training later today but I have high confidence it will least have SOME noticable and positive effect
Anonymous
8/25/2025, 2:35:44 PM
No.106377893
[Report]
>>106377931
>>106377843
>The more you curate data the worse the model gets. It needs the good and the bad because what you want is something in the middle.
You can't just say that dude, this line of thinking is very dangerous.
Anonymous
8/25/2025, 2:36:52 PM
No.106377904
[Report]
>>106377968
>>106377892
Which one are you going to finetune?
Anonymous
8/25/2025, 2:37:15 PM
No.106377907
[Report]
>>106377945
>>106377880
>it is time to redeem vns
Anonymous
8/25/2025, 2:38:11 PM
No.106377913
[Report]
>>106377947
>>106377804
I thought the goal of this endeavor of ours is to make the thing at least better at RP. I feel like even if one of us manages to actually create a data set good enough to both uncuck a model and actually change the quality of its RP people would still bitch and moan about it not being perfect to their standards. I'm not saying trash should not be critiqued but I've kind of the conclusion that this place will never be satisfied with anything
Anonymous
8/25/2025, 2:39:32 PM
No.106377924
[Report]
>>106377931
>>106377843
Can you elaborate on why you think curating it would lead to the model being shittier? Are you referring to personal biases that could lead to the model being better by YOUR standards but might be shit to everyone else?
Anonymous
8/25/2025, 2:40:09 PM
No.106377929
[Report]
>>106378055
we've tried this before
it's always the same
when will you learn? if you get rid of shivers, you get rid of the soul. they are inextricably linked.
Anonymous
8/25/2025, 2:40:32 PM
No.106377931
[Report]
>>106377987
>>106377893
Yeah but it's true.
The model isn't learning, in the conventional sense.
The fact that it follows semantics correctly is an emergent phenomenon. But at the end of the day the goal of training is to create vectors between words (or tokens rather). So if you want diversity of language you need a lot more vague normiespeak to create a much more broad web of vectors. Whereas when writing formally people tend to use much more concise language. Which makes it so that touching always leads to a shiver doing something to a spine.
>>106377924
Anonymous
8/25/2025, 2:42:29 PM
No.106377945
[Report]
>>106377907
looking at the vndb directory and archive sizes its probably extremely limited compared to the sheer amount of stuff thats out there, and probably nobody (that isnt just a finetooner) is actually training on it
Anonymous
8/25/2025, 2:42:40 PM
No.106377947
[Report]
>>106377955
>>106377913
I must be playing for a different team then, I want a model that can one shot smut stories based off a vague summary and some keywords.
Anonymous
8/25/2025, 2:43:30 PM
No.106377955
[Report]
>>106378003
Oh I know why everyone is doing dumb e-waste Radeon Instinct builds right now. China is dumping 32GB MI50s right now which has tanked the price.
Anonymous
8/25/2025, 2:44:02 PM
No.106377963
[Report]
voice barely a whisper
Anonymous
8/25/2025, 2:44:44 PM
No.106377968
[Report]
>>106377904
I'll probably start with a smaller model like 3B or 7b. Llama models are notorious for being cucked so I'll likely start with one of those. Axolotl supports both DPO and SFT training so it will probably be in two stages:
Stage 1: train on the giant SFT data set so that it learns how humans actually write and how a human-to-human RP session what actually go (this guy
>>106377843 mentioned that having the good and the bad is a good thing so the fact that the data set I ripped the data from is 100% human written content is a massive plus. Nothing artificial which means little to no risk of severe overfit on slob). Whether or not The stories it can write will be any good quality-wise by my or anyone else ITT's standards is an entirely different discussion. My main goal is to test whether or not uncucking and and proving our peak capabilities is possible and even worthwhile to do in the first place.
2. I already have a DPO data set saved on my repo so I'll either use that or a data set like that in DPO training in order to guide the model into NOT refusing "problematic" requests.
https://huggingface.co/datasets/AiAF/mrcuddle_NSFW-Stories-JsonL_DPO_JSONL_Trimmed
Take note of the context-aware rejections.
Anonymous
8/25/2025, 2:47:23 PM
No.106377987
[Report]
>>106378021
>>106377931
So the TLDR taught you're saying is:
Sanitized, overly formal, corpo datasets = More likely to do shit like "shivers"
More diverse writing samples in the data set (the good, the bad, the ugly, garbage, utterly trash, etc) leads to better writing capability. Is that what I'm hearing?
Anonymous
8/25/2025, 2:50:26 PM
No.106378003
[Report]
>>106378016
>>106377955
well, yeah, but its more fun if I actually make the model myself. kinda like a proper hobby
Anonymous
8/25/2025, 2:52:04 PM
No.106378016
[Report]
>>106378003
This guy gets it
llama.cpp CUDA dev
!!yhbFjk57TDr
8/25/2025, 2:52:29 PM
No.106378019
[Report]
>>106377960
>240€
It's been a while since I last checked on them, I guess I'll buy one so I can tune performance.
>>106377987
>corpo datasets = More likely to do shit like "shivers"
Well the closed corpo datasets likely have ill-gotten private DM logs in them which is why they are often better at casual RP. Because their pretraining data actually contains casual RP. Since they are doing everything clandestinely they don't need to disclose what's in the dataset so they can get away with putting whatever they want in there.
And when I say bad I mean "casual but still semantically sensible." It probably sees enough typos on common-crawl to be able to read typos so there's no need for technically bad writing.
Anonymous
8/25/2025, 2:54:30 PM
No.106378033
[Report]
>>106378049
>>106377843
>Slop emerges because there's not enough casual writing, framed as RP, in the dataset.
I had this thought that purple prose, so words that ultimately mean nothing, happen so much because meaningless word always fit the next token prediction regardless of context so far. So by extension what would help the model in fighting that is actually having something to say as next token which happens when there is more smut in training data.
Anonymous
8/25/2025, 2:56:40 PM
No.106378049
[Report]
>>106378033
>more smut in training data.
I mean we've known this issue since the beginning. Smut is good. Sex is a huge part of human culture- whether negatively or positively so. Sex permeates language in ways that are often taken for granted. If you take sex out you diminish its overall ability to understand language. I had this argument with totally not Sam Altman™ shortly before OSS released.
Anonymous
8/25/2025, 2:57:16 PM
No.106378055
[Report]
>>106378087
I'd suggest we stop this useless line of discussion and remember this
>>106377929
Anonymous
8/25/2025, 2:59:57 PM
No.106378072
[Report]
>>106377960
The risk though is that AMD can drop support from ROCm at any point and I am willing to bet ROCm 7.0 will cut it off at that point, just like what happened to older GCN cards. But I guess that isn't deterring people from going for it which is understandable. It beats the V100 in my opinion which is in the same situation right now with a more clear sunsetting timeline and except for CUDA, everything is worse about that card compared to the MI50. The next card up with some stability is the 32GB Radeon Pro V620 with RDNA2 but it will cost you more than 2x the price.
>>106378055
No one is getting rid of the shivers because no one has enough compute to make a sex model. Although why did people stop after pygmalion?
>>106378021
>so there's no need for technically bad writing.
I think there would still be a lot of benefit from that. These companies make the data sets for these models, especially being struck tuned ones, data set quality is of the utmost importance, so it means they would want to eliminate as many typos or informal speech as possible. This is what allows the bigger models like llama or GPT-4 and 5 to output really high quality information when asked. Garbage in = garbage out. This means they're good at doing specialized tasks like reading documents or generating code but it also means that they're at best OKAY at RP. It's a bit of a catch-22 for them. If you leave in too much of the good and bad RP then it gets more likely to be "unsafe" but also mimic the little human nuances of story writing (minor typos, run on senses, not using certain terms correctly, rambling on and on about nothing. Etc). Even if they did not give a shit about whether or not the models could generate smut, It would still be in their best interest to Santa's ties the data sets of anything from sites like AO3 except for stories that are deemed "high quality" soulless by silicon valley vermin because in their eyes the human nuances would make their models shittier even if it meant it would end up looking more "human". So how they end up doing it is that the models CAN RP and some of them are even capable of doing raunchy shit that would get you put on lists (I've heard nothing but good things about deepseek's RP abilities It is apparently nowhere near as cucked as the competition. I've never directly used it for RP so I'm just going off what other anons have said). But will it have the same "SOVL" as human written work? More often than not it will be lacking.
Anonymous
8/25/2025, 3:03:50 PM
No.106378105
[Report]
>>106378021
>>106378088
(Cont.)
The data set trainers and companies' intentions don't even necessarily have to be malicious or completely antithetical to our goals (finding, jailbreaking, and making models less cucked and refusal prone). Them sucking at RP (by our standards) could just be an unfortunate side effect to the quality standards of the data sets because remember, most of these companies want the models to be general purpose. You can end up fine tuning a model that is specifically good at RP but then it might suck really really badly at programming because that wasn't a major concern with the data set curator. Or your model could be very good at programming or other repetitive structure tasks, but as a side effect be terrible at anything creative. Because of this, unless the models go through further fine tuning, they always either be shit or lacking in some areas (again, by OUR standards and whoever's doing the fine tuning)
Anonymous
8/25/2025, 3:04:53 PM
No.106378114
[Report]
>>106378088
Well if you recall OG Mixtral, you had to add [0], [1], [2] etc to the stop sequences because Mistral was too lazy to regex out annotation marks from their data. So it depends how "technically bad" you're talking. Errant non-linguistic characters can be pretty destructive,
Anonymous
8/25/2025, 3:05:10 PM
No.106378118
[Report]
>>106378146
>>106378088
Just say that text distribution in corpo assistant sft is nothing like text distribution in perverse fan fiction
>>106378087
>Although why did people stop after pygmalion?
The scale of modern models is prohibitively expensive and now you get the risk of safety people trying to cancel you and ruin your life if you do make a good ground up unsafe model.
Anonymous
8/25/2025, 3:06:08 PM
No.106378132
[Report]
>>106378143
>>106378087
>What is DPO
>What is SFT
Have you been paying attention to this thread at all? A well curated DPO data set alone will probably be good enough to lessen the shivers to a noticeable extent, if not entirely.
Anonymous
8/25/2025, 3:06:28 PM
No.106378135
[Report]
>>106378148
>>106378121
The second part I get but for first part did it really take llama1 for people to realize you need 1000 more gpu's?
Anonymous
8/25/2025, 3:07:29 PM
No.106378143
[Report]
>>106378178
>>106378132
And how does any of that prevent catastrophic forgetting?
Anonymous
8/25/2025, 3:07:30 PM
No.106378144
[Report]
>>106378121
Yeah but the tables have turned now and investors are becoming afraid of wokeness and the like. And a lot of people who proclaim their hatred for AI now use it anyway. So they really need to start ignoring the teeth gnashers.
Anonymous
8/25/2025, 3:07:34 PM
No.106378146
[Report]
>>106378171
>>106378118
Yeah that's pretty much what I'm saying. Too much corporate data = The training and what the model learns gets dominated by it and it negatively affects other areas
Anonymous
8/25/2025, 3:07:44 PM
No.106378148
[Report]
>>106378271
>>106378135
You don't realize how woefully under trained older models were.
Anonymous
8/25/2025, 3:09:05 PM
No.106378158
[Report]
>>106378173
>>106378121
If you're trying to train a model from scratch then yeah it's prohibitively expensive. If you're just doing a further fine-tune then, not really. Especially if you know how to make a good qlora config, good dataset, Knowing which KIND of data set to use and curate, and actually know how to interpret wandb graphs.
Anonymous
8/25/2025, 3:09:27 PM
No.106378160
[Report]
>>106378190
>waiting for intern to actually upload the big 3.5 instead of empty repos
>somehow they start publishing every other fucking size from 30b all the way down to 1b
c'mon faggots I need to queue up the download before I go sleep
Anonymous
8/25/2025, 3:10:49 PM
No.106378166
[Report]
xtts is really good, quite efficient as well
Anonymous
8/25/2025, 3:11:06 PM
No.106378171
[Report]
>>106378229
>>106378146
2 years ago making a model specialized for ERP had potential commercial viability. But now "good enough" for most people runs on a potato and anybody who can read and follow instructions can set it up themselves in a matter of minutes. So while AI is an investment bubble with no ROI it's even less-so on models that only a handful of people out of the crowd even feel the need for. We're in the minority here.
Like I used to do a lot of text based ERP with human partners and Qwen 4B pretty much beats the average human, slop or not. I've had plenty of human ERP partners that think they can talk with a dick in their mouth, too.
Anonymous
8/25/2025, 3:11:20 PM
No.106378173
[Report]
>>106378158
>>If you're trying to train a model from scratch then yeah it's prohibitively expensive
That was the discussion subject yes, every other joe with a few dollars can become a Drummer.
Anonymous
8/25/2025, 3:11:34 PM
No.106378178
[Report]
>>106378208
>>106378143
You have the SFT data sets have JSON objects that contain both short and long sequences. If it's only trained on short prompts and short responses, then it will only generate short responses and then promptly "forget" whatever you were talking about. But if you have multiple examples of both short and long sequences within the story, then the model will learn how to "remember" what you talked about. I promise I'm not trying to be a shield but take a look at the one I linked here. The way it repeatedly has the same stories but formatted in different ways addresses that potential issue.
>>106377332
You could also just fine-tune a model with high enough perimeters so that exist likely to forget in the first place.
>>106378160
Isn't intern stem/bench/mathmaxxed and dick/sexminned?
>>106378178
You don't even know what catastrophic forgetting is, do you?
Anonymous
8/25/2025, 3:16:14 PM
No.106378217
[Report]
>>106378190
I think 2.5 38B was good for tagging nsfw images. Not sure how it is now.
Anonymous
8/25/2025, 3:16:38 PM
No.106378222
[Report]
>>106378190
Their S1 model was pretty cucked when it came to describing nsfw when I tried it, at least compared to step3, but S1 was a science specialist and this is a more general VLM so there's some hope.
Anonymous
8/25/2025, 3:17:23 PM
No.106378229
[Report]
>>106378171
>But now "good enough" for most people runs on a potato
Not on mobile where the money is at.
Anonymous
8/25/2025, 3:17:26 PM
No.106378231
[Report]
All we really need is more pre-sft versions of Tulu-3 on newer models. They haven't done a Tulu since Llama-3.1. And the pre-SFT/DPO version of Tulu-3-70B, albeit bad at RP formatting was lascivious as fuck.
Anonymous
8/25/2025, 3:17:49 PM
No.106378235
[Report]
>>106378272
>>106378208
Enlighten us then. I'm under the impression you're referring to RP with a model and then it forgets basic shit you discussed a couple paragraphs previously. If nothing what are you referring to?
Anonymous
8/25/2025, 3:19:34 PM
No.106378247
[Report]
>>106378257
>I'm under the impression you're referring to RP with a model and then it forgets basic shit you discussed a couple paragraphs previously.
So I was correct that /lmg/ is a groundhog day of wave of newfags rediscovering everything every year as oldfags leave.
Anonymous
8/25/2025, 3:20:26 PM
No.106378255
[Report]
>>106378265
>>106378208
catastrophic forgetting is a good thing if you want to get rid of safety and slop. it obviously will hurt performance in other areas but that is the point of fine tuning, you fine tune when you believe the original model creators made the wrong compromises, if it was possible to make a model good at every area without compromise we would have already achieved agi/asi by now.
Anonymous
8/25/2025, 3:20:37 PM
No.106378256
[Report]
>106378235
RIP LMG
Anonymous
8/25/2025, 3:20:38 PM
No.106378257
[Report]
>>106378247
it's the same people they're just catastrophically forgetting
Anonymous
8/25/2025, 3:21:43 PM
No.106378265
[Report]
>>106378255
>catastrophic forgetting is a good thing
muh trivia!!!
Anonymous
8/25/2025, 3:22:26 PM
No.106378271
[Report]
>>106378148
>You don't realize how woefully under trained older models were.
it's easily noticeable by how much more affected by quantization the modern small dense models are, nobody would notice a difference between Q4 and Q8 on llama 1 but you absolutely see it in any of the Qwen 3
Anonymous
8/25/2025, 3:22:35 PM
No.106378272
[Report]
>>106378417
>>106378235
that is bad attention patterns, not the same thing at all. catastrophic forgetting is when you over-fit to one domain you lose performance in other domains.
Anonymous
8/25/2025, 3:26:20 PM
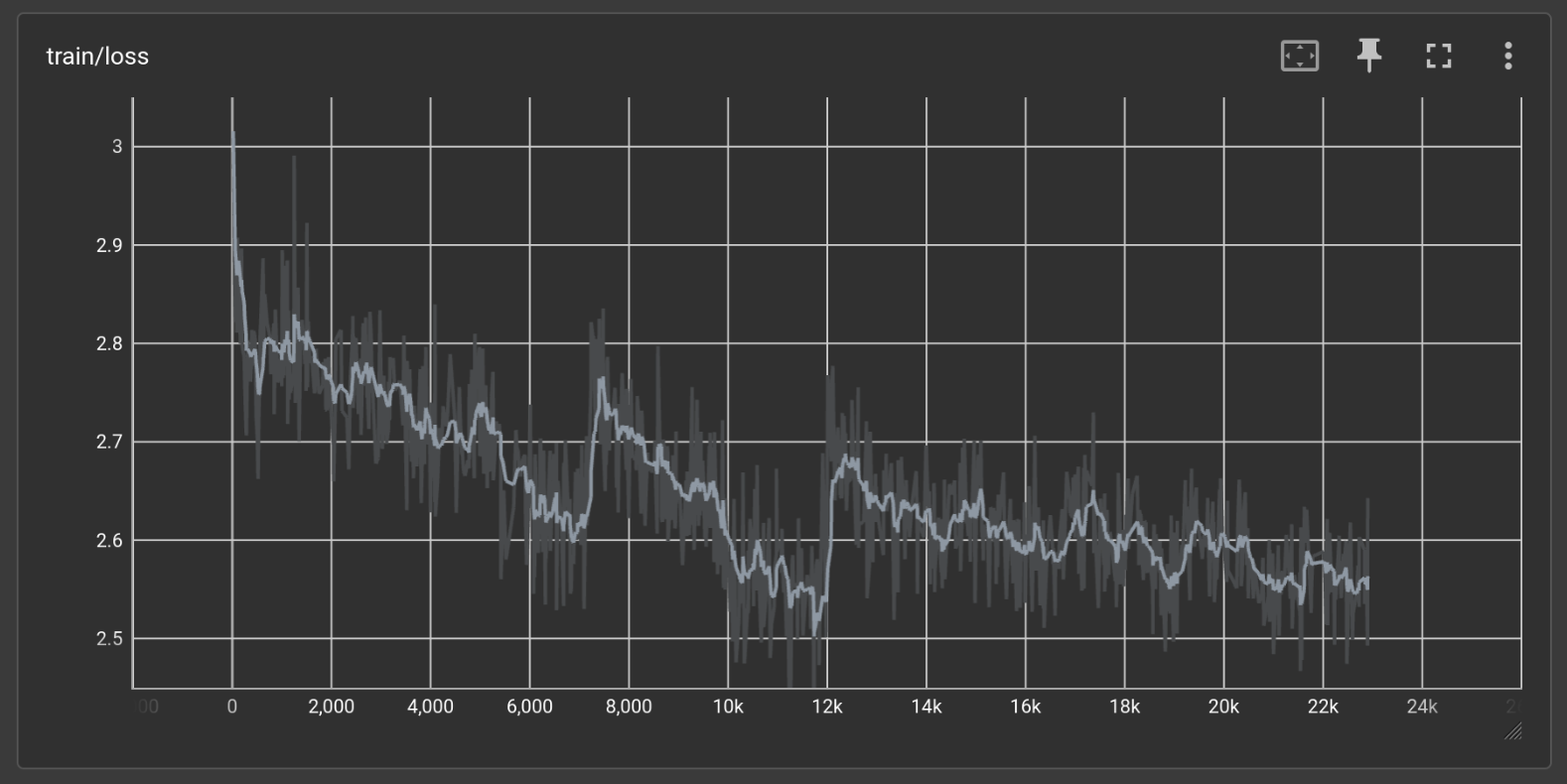
No.106378307
[Report]
>>106378497
>>106377841
Those loss spikes are not looking good desu.
>>106378272
If the main goal is to make it good at RP and you don't really give a shit if it's good at scientific fact report code or math, the next not much of a concern. If you DO care about that then you would have to use the RP data set AND dedicated fine-tuning data sets based on those domains during training (trainers support using multiple data sets at once)
Example: train on rp.jsonl, math.jsonl, code.jsonl, legal.jsonl, etc, simultaneously.
There should be little to no risk of a different domains negatively interfering with each other assuming the data sets don't have system prompts and regular prompt keys that are too similar. The data set that trains the model how to be better at smut shouldn't fuck up the math training because there wouldn't be any advanced math in it in the first place that could cause misalignment
Tldr: who cares? Most of us don't give a shit about it being a super genius anyway. We want the thing to get our dicks hard
Anonymous
8/25/2025, 3:39:21 PM
No.106378420
[Report]
>>106378425
>>106377882
Anon... Download this and do some analysis.
https://www.kaggle.com/datasets/rtatman/english-word-frequency
"the" has a 3.93% frequency in English on the web. "shivers" has a 0.000064% frequency in normal English texts. 0.012% is the frequency of words like "Thursday", "advice", "coming", "lead" or "women".
The model will quickly pick up on words that are strongly overrepresented compared to baseline and amplify them by a lot.
Anonymous
8/25/2025, 3:40:04 PM
No.106378425
[Report]
>>106378420
"woman" not "women", sorry.
Anonymous
8/25/2025, 3:41:35 PM
No.106378441
[Report]
>>106378610
>>106378417
>If the main goal is to make it good at RP and you don't really give a shit if it's good at scientific fact report code or math, the next not much of a concern.
Ahhh... to be a cute naive newfag again...
>>106378417
I mean, there is overlap because not everything is straight formulas, science and math does have prose via scientific papers. So yes, it will affect things. I do agree training on everything is orthogonal but if you think having a smart in prose dumb with everything else model works, I would like to see you handle the model teleporting you to places, assuming functions on objects and making people appear/disappear in your stories. General intelligence does matter for RP.
>>106378417
>Most of us don't give a shit about it being a super genius anyway
One of if not the most common complaint from anons is that our model are retarded, after comes slop which would be far less annoying if the model weren't stupid.
Anonymous
8/25/2025, 3:47:39 PM
No.106378486
[Report]
>>106378468
At this point, one could hope that a really good model would have seen lots of complaints about sloppy writing during pretraining, so you can just tell it not to use common AI slop terms. Kind of like recent image models know the ai-generated tag.
Anonymous
8/25/2025, 3:48:55 PM
No.106378497
[Report]
>>106378583
>>106378307
it was to be expected, it was a different dataset mix. training loss is a bit of a moving target. validation got hit too but I think it was just because my validation set is only a single document slightly out of domain. but actual generations have been consistently getting a bit better too,
Anonymous
8/25/2025, 3:54:29 PM
No.106378551
[Report]
>>106378459
>I would like to see you handle the model teleporting you to places, assuming functions on objects and making people appear/disappear in your stories. General intelligence does matter for RP.
what if that what I want tho, I started mixing in some erowid.org drug trip reports just so it would be less coherent and less grounded in reality.
Anonymous
8/25/2025, 3:58:36 PM
No.106378583
[Report]
>>106378497
Okay, if you're just swapping datasets during the run that's to be expected.
>>106378441
Again, enlighten us....
>>106378459
I still fail to see why fine-tuning on a specifically RP focus data set would degrade any other domains. I feel like that would only occur if the "prompt" keys in your RP data set in the data set trained on the initial model were very similar. Which is very unlikely given that The companies who made these models likely didn't include a lot of user written RP for "safety" reasons or just didn't give a shit whether or not it was good at RP.
Anonymous
8/25/2025, 4:02:50 PM
No.106378614
[Report]
>>106383095
>>106378610
>I still fail to see why fine-tuning on a specifically RP focus data set would degrade any other domains.
"catastrophic forgetting" mainly.
>>106378468
>our model are retarded
Elaborate. Retarded in what ways? Logic? Spatial awareness, knowledge of science? Nonsensical RP?
Anonymous
8/25/2025, 4:04:35 PM
No.106378626
[Report]
>>106383095
>>106378610
>I still fail to see why fine-tuning on a specifically RP focus data set would degrade any other domains
they share parameter weights, what is there not to get?
Anonymous
8/25/2025, 4:05:18 PM
No.106378634
[Report]
>>106378624
>Logic, Spatial awareness, Nonsensical RP?
Yes.
>>106378624
>She stripped naked, her pendolous orbs swaying freely as she flung her panties into a corner and lied down on the bed. I step up to the couch and push aside her thong, my tip resting against her pussy as I rip open her blouse.
>>106378459
I've seen this explanation a bunch of times and I still don't quite buy it
Yes - if you train on mathematics and scientific papers it improves performance in those domains, but the issue is that creative writing and RP are also not orthogonal to those concepts. Functions on objects and people appearing/disappearing won't happen because that shit is already a basic part of writing. You don't need to understand the five most recent papers in string theory to understand object permanence or that men have dicks and women have pussies
These things are also still imitators, and I suspect that when you're RPing with your character around the fire, the LLM isn't implicitly solving flame trajectory equations to determine whether you or your waifu feels warmer. It's probably drawing from relatable situations in its training, which are themselves largely creative writing and RP focused
Anonymous
8/25/2025, 4:18:09 PM
No.106378753
[Report]
>>106379472
>Code
You're doing it wrong. This is the better approach.
>Reasoning
You're doing it wrong. Here's a much better way.
>Facts
You're wrong here's more data to support the correct method.
But what's really the right way to roleplay? I guess you can teach all the fundamentals of storytelling, writing characters, and dialogue, and it just might spit out a decent story. But I don't know can you really teach a model how to roleplay properly?
Without giving it specific outlines and variable each time?
Anonymous
8/25/2025, 4:18:22 PM
No.106378756
[Report]
>>106378738
>men have dicks and women have pussies
omegaverse has entered the chat
Anonymous
8/25/2025, 4:25:14 PM
No.106378831
[Report]
>>106378738
this is obviously true, you can train a model on nothing but narratives and it will use words correctly without ever having seen the definition, and it will be unable to synthesize a definition when prompted. they really are just stochastic parrots. there might be a little bit of transfer learning going on but I believe the extent of it is over stated.
Anonymous
8/25/2025, 4:46:43 PM
No.106379002
[Report]
>>106378459
The problem isn't tangential relation to sex but that the training created a basic structure where it is integral and everything is interdependent on it. You can't use existing stemmaxxed model and just be happy with catastrophic forgetting. You can train model from scratch without this useless shit but you don't have compute so... yeah you can just wait for uncensored model with more smut in it or if you are low IQ you can use drummer shittune and pretend it works.
Anonymous
8/25/2025, 4:57:47 PM
No.106379112
[Report]
>>106379130
>and the truthbomb made all the newfags jump off the bridge and all that was left of /lmg/ was me and mikutroons
Anonymous
8/25/2025, 5:00:00 PM
No.106379130
[Report]
>>106379140
>>106379112
>and all that was left of /lmg/ was me and mikutroons
I'm here too, anon. And that other anon as well. We're all alone together.
Anonymous
8/25/2025, 5:00:57 PM
No.106379140
[Report]
>>106379130
Hey, I'm here, too.
Anonymous
8/25/2025, 5:09:49 PM
No.106379212
[Report]
But is John here with us?
when you walk away
you dont hear me say
please
oh baby
dont go
Most slopped words?
>urgent
>deliberate
Anonymous
8/25/2025, 5:19:08 PM
No.106379290
[Report]
Anonymous
8/25/2025, 5:23:27 PM
No.106379316
[Report]
>>106379277
>darker
>uniquely
Anonymous
8/25/2025, 5:24:49 PM
No.106379331
[Report]
>>106379277
A testament to the slow rhythm, becoming a passionate dance between his member and her wetness.
Anonymous
8/25/2025, 5:25:12 PM
No.106379334
[Report]
>>106377421
>stories they wrote to cope with rape
that would explain some of the reasoning outputs that I see
Anonymous
8/25/2025, 5:28:36 PM
No.106379368
[Report]
With 256gb of vram, it's more fun running multiple ~30b sized models and comparing their answers.
Anonymous
8/25/2025, 5:30:21 PM
No.106379382
[Report]
>>106379448
>>106378714
>her pendolous orbs swaying freely
>>106379382
kek
haven't seen one of those in real life in a long ass time, what happened?
Anonymous
8/25/2025, 5:38:48 PM
No.106379454
[Report]
>>106379458
>>106379448
They aren't novel, they take up space, and they don't have a purpose.
Anonymous
8/25/2025, 5:39:30 PM
No.106379458
[Report]
>>106379448
>>106379454
I have one on my desk
Anonymous
8/25/2025, 5:41:39 PM
No.106379472
[Report]
>>106379523
>>106378753
Reasoning focused RP. Instead of rambling about what should be in the answer, it should follow a guideline with <mood>, <location>, <activity>, <topic>... then provide the RP content incorporating these elements. That would monkeypatch the models' subpar attention which is the main cause of having spatial/action issues.
Anonymous
8/25/2025, 5:43:17 PM
No.106379482
[Report]
Anonymous
8/25/2025, 5:48:17 PM
No.106379523
[Report]
>>106379578
>>106379472
That's how most rp-focused reasoning presets work. They give the model a list of things to think about like location, topic, last action, etc to think about. It depends on the model how effective it is. Claude and some of the newer open reasoners are pretty easily steerable like this while others just do their own thing.
There's also the cherrybox presets which try to turn non-reasoning models into pseudo-reasoners by giving them a set list of points to consider before writing the reply. That actually helped a lot with some of my scenarios that require the model to stay on top of a bunch of important factors and stats to decide the next event. Normal presets failed at this.
Anonymous
8/25/2025, 5:51:13 PM
No.106379544
[Report]
>>106377843
The data must be in the format you use for interacting with the model. Simply adding sovlful fics to the dataset won't be enough.
Anonymous
8/25/2025, 5:55:59 PM
No.106379578
[Report]
>>106379523
I think the models would get better if they were finetuned on that kind of preset instead of using the system prompt to steer them in that direction. Small models would largely benefit from that as their reasoning capacity is limited compared to cloud models to do that easily
Anonymous
8/25/2025, 5:59:21 PM
No.106379604
[Report]
Anonymous
8/25/2025, 6:01:55 PM
No.106379630
[Report]
>>106379692
>>106379448
"I heckin' love science" types made them cringe.
Anonymous
8/25/2025, 6:04:08 PM
No.106379635
[Report]
Anonymous
8/25/2025, 6:04:47 PM
No.106379638
[Report]
I'm feeling it again bros... the urge... the urge to frankenmerge
Anonymous
8/25/2025, 6:05:24 PM
No.106379642
[Report]
>>106380585
Anonymous
8/25/2025, 6:05:32 PM
No.106379643
[Report]
where intern
Anonymous
8/25/2025, 6:08:33 PM
No.106379660
[Report]
Hey Faggots,
My name is John, and I hate every single one of you. All of you are fat, retarded, no-lifes who spend every second of their day looking at MoE outputs. You are everything bad in the world. Honestly, have any of you ever gotten any dense pussy? I mean, I guess it's fun making fun of people because of your own insecurities, but you all take to a whole new level. This is even worse than jerking off to pictures on facebook.
Don't be a stranger. Just hit me with your best shot. I'm pretty much perfect. I was captain of the football team, and starter on my basketball team. What models do you load, other than 1T/s 1IQ R1? I also get straight A's, and have a banging hot girlfriend (She just blew me; Shit was SO cash). You are all faggots who should just kill yourselves. Thanks for listening.
Pic Related: It's me and my bitch
Anonymous
8/25/2025, 6:10:29 PM
No.106379672
[Report]
>>106377562
cannot unhear
also F YOU :D
Anonymous
8/25/2025, 6:14:18 PM
No.106379692
[Report]
>>106379630
sad, i liked seeing in otherwise boring offices and various places when i was a kid
Anonymous
8/25/2025, 6:17:52 PM
No.106379720
[Report]
>>106378714
>pendolous orbs
All the better to ponder, milady
ook ook
Anonymous
8/25/2025, 6:23:16 PM
No.106379765
[Report]
>Multimodal VLM Developer
>We expect you to have experience in training DL models and deploying them into production
Bitch, what production? And if I had that kind of money one needs to train models at home, even if relying on cloudshit services, I wouldn't need a job.
Anonymous
8/25/2025, 6:23:19 PM
No.106379766
[Report]
are you saying i cant run the dual 48gb intel card on a b660?!!?
FUUUUUUUUUUUUCK
True soul is only achieved by running inference on pure text completion mode, letting the model infer the chat format by providing nothing but example dialog.
Instructshit was a mistake.
Anonymous
8/25/2025, 6:28:47 PM
No.106379824
[Report]
>>106379862
>>106379799
I'll download GLM 4.5 air base in your honor.
Anonymous
8/25/2025, 6:29:55 PM
No.106379829
[Report]
lol lmao even
this website is so funny
they sell rtx 5080s for 6000$ too kek
Anonymous
8/25/2025, 6:31:08 PM
No.106379843
[Report]
Anonymous
8/25/2025, 6:32:31 PM
No.106379859
[Report]
>>106380002
Anonymous
8/25/2025, 6:32:59 PM
No.106379862
[Report]
>>106379907
>>106379824
Thanks I guess. I could never hope to run that on my hardware.
Anonymous
8/25/2025, 6:34:12 PM
No.106379868
[Report]
>>106379896
>>106378459
This is cope from retards who want to find a silver lining for models being heavily trained on code and math. They hope that the codeslop is not an obvious waste that degrades the model in RP, that it somehow makes the model "smarter". There's no evidence for this and a lot of counter-examples. I remember feeding codellama-32b RP prompts and being amazed at how retarded it was kek. If you want a model to be good at RP it's best to train it on RP. Shocking, I know!
OTOH it probably will forget the code and math shit if you do this, but who cares, the mathcels have a ton of models they can use already.
Anonymous
8/25/2025, 6:34:32 PM
No.106379869
[Report]
>>106379799
dunning kruger
Anonymous
8/25/2025, 6:39:00 PM
No.106379896
[Report]
>>106380029
>>106379868
Code, no, but encyclopedic/technical prose, yes.
Anonymous
8/25/2025, 6:40:31 PM
No.106379907
[Report]
>>106379955
>>106379862
I'm running 64GB of DDR5 + 8GB of VRAM. It's not exactly great hardware, but it's enough to play around.
Anonymous
8/25/2025, 6:40:39 PM
No.106379908
[Report]
>glm-air-chan is schizoing out
I blame cope quants.
Cope KV cache quants in particular, anons weren't lying about that one
>glm-air-chan doesn't pass the breakfast test
This one hurts.
It's so close to being real, man. But when slip ups happen, it's a fucking knife right in the feels.
>offloading glm-air-chan to GPU brings t/s from 3.9 CPU-only to whopping 5.1!
Exlpain yourelf gpumaxxers.
Btw, I think I'm hitting some strange llama.cpp/vulkan/driver bug, because with --no-mmap I get what seems like OOM errors even though there should be plenty of memory, and with --mlock and --no-mmap I even get a fucking segfault.
Anonymous
8/25/2025, 6:43:25 PM
No.106379925
[Report]
>>106380018
>>106379917
I never saw any difference between Q8 and full fp16 kv cache. Q4 is very obvious.
Anonymous
8/25/2025, 6:46:59 PM
No.106379955
[Report]
>>106379907
How many t/s are you getting?
I get about 17t/s q3@ no context with a MI50 but it goes down fast as context grows.
Anonymous
8/25/2025, 6:47:09 PM
No.106379957
[Report]
>>106379990
>>106379799
instruct models are inherently superior though
no amount of prepending examples could bring a base model to a level of understanding of an instruct
people used to think of base models as being better for "code completion" and even in that basic bitch usage nobody uses them anymore
Anonymous
8/25/2025, 6:49:49 PM
No.106379979
[Report]
>>106379917
>>glm-air-chan is schizoing out
>I blame cope quants.
I had it go into infinite repeat on their official website. I don't think they run cope quants there. I agree with you on quants being localkek cope though. But GLM is shit, and people who think otherwise are just living in denial and gaslighting others.
Anonymous
8/25/2025, 6:51:45 PM
No.106379990
[Report]
>>106379799
>>106379957
Yeah, I gave a long real world text to an Instruct and its base model in text completion. Guess which one better continued it.
Anonymous
8/25/2025, 6:53:55 PM
No.106380002
[Report]
>>106380024
>>106379859
The moustache will tickle my thighs
Anonymous
8/25/2025, 6:55:07 PM
No.106380013
[Report]
>>106379917
air definitely does start out strong but also gets a little weird once context fills up from what I've seen
I'm switching between it and 70b stuff to compare responses
Anonymous
8/25/2025, 6:55:38 PM
No.106380018
[Report]
>>106380075
>>106379925
I'm playing around with KV cache on very small models and I can tell you that anything below FP32 is making mistakes that are rapidly snowballing out of control. It might just be less of an issue on current overfit benchmaxxed models with >99.9% confidence on the first token
Anonymous
8/25/2025, 6:56:47 PM
No.106380024
[Report]
>>106380002
And the gun will stimulate your prostate.
Anonymous
8/25/2025, 6:58:08 PM
No.106380029
[Report]
>>106380072
>>106379896
Is there any reason to believe models need more than the technical prose they already saw in pre-training? Which is probably a lot. idk I can see a plausible argument for adding like 1-5% of pretrain style data in a finetune mix, just for retention, but no more than that. And I'm not sure that's even needed at all.
Anonymous
8/25/2025, 7:04:36 PM
No.106380072
[Report]
>>106380029
Yeah. I didn't think the other anon was saying people put code in a finetune though.
>>106380018
if we're talking small models then even "benchmaxxed" are badly affected by both kv cache quantization and model quantization too.
never run small models at anything other than Q8 or full unquanted weights
It's impressive how coherent Qwen 3 1.7B is at Q8, but becomes plain broken at Q4_K_M
The bigger the model the more you can mess with them, but ultimately, all quants are cope, kv quantization is cope, and model quantization is cope too
Anonymous
8/25/2025, 7:08:02 PM
No.106380103
[Report]
>>106380075
Never run anything. Models are cope. Use your mind.
Anonymous
8/25/2025, 7:10:25 PM
No.106380115
[Report]
>>106380230
>>106380075
It is and it isn't.
Quantization loss effects smaller concepts, but, within reason, the 'big picture' type knowledge (like knowing that you can't talk and suck dick at the same time) survives quantization.
So there's a tradeoff.
If your use case requires fine details of relatively uncomplicated matters then you're better off running a smaller model at fp16 or Q8. If your use case requires an understanding of a larger more complicated concept but you don't care about fine details then you're better off running a cope quant of a bigger model.
When cloud providers (like on openrouter) say they're offering fp4, is that the same as Q4?
Anonymous
8/25/2025, 7:18:30 PM
No.106380165
[Report]
Anonymous
8/25/2025, 7:20:36 PM
No.106380182
[Report]
>>106380339
>>106379917
clanker propaganda
>>106380115
I wasn't saying a micro model at Q8 was better than a large model at Q4 though. I was just plainly stating that all forms of quantization are pure cope. We run quants out of cope. That the effect is less visible on the larger model doesn't make it any less true (and on the fine detail side, you can see it even on large models with prompts like language translation, quant is a lobotomy in that kind of prompt)
I use local a lot during development to avoid burning through API calls during tests but I frankly do not consider local good enough for anything in real usage
and let's not even get into the whole "10t/s is enough" fat moe on cpu camp running thinking models in thinking mode so the whole "it's faster than you can read" cope doesn't even apply - you can only read anything of value once the model is done with the thinking shit, t/s matters nigger
Anonymous
8/25/2025, 7:29:49 PM
No.106380255
[Report]
>>106379917
Based Robofren
Dunno about the tech issue did you try diff versions/building from lastest master?
llama-server stdout should say a lot about it's mallocs maybe try --verbose
Anonymous
8/25/2025, 7:29:58 PM
No.106380256
[Report]
>>106380270
>>106380230
10t/s definitely isn't enough.
Think we might be able to get 15 when DDR6 drops?
Anonymous
8/25/2025, 7:31:50 PM
No.106380270
[Report]
>>106380297
>>106380256
DDR6 a meme we are already at limits hence bonding RAM to silicon in the fancy GPUs
Anonymous
8/25/2025, 7:33:46 PM
No.106380292
[Report]
>>106379799
This, but unironically.
Anonymous
8/25/2025, 7:34:38 PM
No.106380297
[Report]
>>106380337
>>106380270
What limit? Memory bandwidth? DDR6 will have higher memory bandwidth, presumably
Anonymous
8/25/2025, 7:36:30 PM
No.106380309
[Report]
>>106379799
You can't do this with instruct-slopped "base" models unfortunately since they start looping after a paragraph or 2. So that hasn't worked since Llama-1.
What ever happened to that base model Nous Research were planning to make?
>>106380131
I am pretty sure FP4 is more like Q3 or even Q2 in practice. No fucking idea why are they bothering with these floating meme quants.
>>106380297
the limits of PHYSICS are what limits bandwidth
trace length of PCB, the longer they are = more resistance and capacitance
crosstalk
reflections
you know what makes HBM on datacenter GPUs so great? it's all stacked on top of each other
as long as slotted ram is the standard of desktop cpu ram it will be garbage
period
Anonymous
8/25/2025, 7:41:55 PM
No.106380359
[Report]
>>106380378
>>106380339
Real American hours have started I see.
Instead of a captcha you should have to leave a foreskin print. Imagine how much that would improve the quality of discussion.
Anonymous
8/25/2025, 7:42:52 PM
No.106380367
[Report]
>>106380337
can you stack 2TB on top of a datacenter GPU????
Anonymous
8/25/2025, 7:43:18 PM
No.106380376
[Report]
Which models do not do this ever?: "I'm sorry, but I cannot provide the information you're asking for."
Anonymous
8/25/2025, 7:43:23 PM
No.106380378
[Report]
>>106380359
What are you complaining about exactly
Anonymous
8/25/2025, 7:44:03 PM
No.106380382
[Report]
>>106380436
Will we eventually adopt photonics? Not just in the chip, but as a communication bus between them too.
Anonymous
8/25/2025, 7:44:06 PM
No.106380384
[Report]
Anonymous
8/25/2025, 7:45:05 PM
No.106380393
[Report]
>>106380499
>>106380337
how do you know DDR5 at the physical limit of bandwidth?
Anonymous
8/25/2025, 7:46:12 PM
No.106380405
[Report]
>>106380317
It's just a hardware accelerated format for the new gpus, nothing else. These threads are always so full of retards it's not even funny anymore.
Anonymous
8/25/2025, 7:47:33 PM
No.106380417
[Report]
>>106380482
>>106380317
What makes you say that?
Anonymous
8/25/2025, 7:49:55 PM
No.106380436
[Report]
>>106380449
Anonymous
8/25/2025, 7:51:17 PM
No.106380449
[Report]
>>106380436
I love that channel so much.
sirs its over, i angered the jannies too much
grok 2 gguf was the nail in the coffin
Anonymous
8/25/2025, 7:53:39 PM
No.106380472
[Report]
>>106380630
>>106379917
what's the breakfast test? i can test on glm-4.5v-fp8 which is based on air
Anonymous
8/25/2025, 7:54:43 PM
No.106380482
[Report]
>>106380501
>>106380417
with floating point, you lose at least 1 bit to encode sign, and a little bit more data because you keep exponent and mantissa separate. With FP16 trade offs make sense, but FP8 and lower is dumb.
the only cool floating point quant I saw is Unsigned, Exponent 4, Mantissa 0, which is basically INT4 but with multiplication and division replaced by addition and subtraction.
Anonymous
8/25/2025, 7:55:50 PM
No.106380493
[Report]
Anonymous
8/25/2025, 7:56:42 PM
No.106380499
[Report]
>>106380540
>>106380393
https://www.microwavejournal.com/articles/35683-ddr5-signal-integrity-fundamentals
get some fucking education on the topic
this can't be summed in a one liner if you want a practical explanation of what's going on
but basically slotted ram is a FUCKING DEAD END
you need full SOCs to get meaningful improvements because DDR5 is already doing heroic efforts to preserve signal integrity in long PCB traces
there is only so much you can do when the distance between your CPU and your actual ram chips is big
GDDR6 is good not because it's "not DDR5" but because it's soldered so close together and close to the gpu. and datacenter stuff is even better because it's even tighter packed and the ram chips themselves are stacked vertically.
>>106380482
And Q8/Q4 is not floating point?
I thought R1 was released as fp8
Anonymous
8/25/2025, 7:58:41 PM
No.106380524
[Report]
>>106380501
>And Q8/Q4 is not floating point?
no, q8 and fp8 have nothing to same
Anonymous
8/25/2025, 7:58:53 PM
No.106380527
[Report]
>>106380501
are you indian? you have to tell us
>>106380499
why not just wider and more numerous channels? even if we hit a wall with latency maybe we can still scale the throughput? do models really need random access or is it pretty much sequential?
Anonymous
8/25/2025, 7:59:54 PM
No.106380541
[Report]
/lmg/ I'm just not hyped anymore. From 2023-2024 we went from some shitty Llama 1 finetunes that were horrible to DeepSeek V3.
I haven't even tried GLM-4.5 or Kimi K2 because the gains have been so negligent it's not even worth setting it up.
Is it just stagnation from now on?
Anonymous
8/25/2025, 8:00:24 PM
No.106380548
[Report]
>>106380724
>>106380317
>floating meme quants
think they're doing it because they supposedly run faster on modern nvidia gpus (hardware support for FP4 and FP8)
but yeah, having seen in the world of diffusion models many comparison between full weight vs FP8 vs Q8 ggufs where the Q8 is a trillion times better I'm left wondering how dumb those FP8/FP4 LLMs are
Anonymous
8/25/2025, 8:00:28 PM
No.106380549
[Report]
>>106380469
Don't worry, it's still up.
Anonymous
8/25/2025, 8:01:00 PM
No.106380551
[Report]
>>106380543
>/lmg
it's dead sir
Anonymous
8/25/2025, 8:03:27 PM
No.106380585
[Report]
>>106380631
>>106379642
>https://videocardz.com/newz/maxsun-arc-pro-b60-dual-with-48gb-memory-reportedly-starts-shipping-next-week-priced-at-1200
Might be OK if it pools memory between the GPUs but I bet it's merely an internal PCIe bifurcation to two separate GPUs. In that case, it's worthless garbage.
>>106376303 (OP)
cat gpt-oss-120b-Q4_K_M-00001-of-00002.gguf gpt-oss-120b-Q4_K_M-00002-of-00002.gguf > gpt-oss-120b-Q4_K_M.gguf
Should I do that?
Anonymous
8/25/2025, 8:08:27 PM
No.106380630
[Report]
>>106380472
the OG breakfast question is pic related.
I didn't ask about breakfast exactly, I just wrote a scenario and asked what it looks like from Character A perspective. GLM-Air has not problem with that, and this is actually my favorite thing to do with it right now.
But then I decided to go 1 recursion step deeper and asked what Character B thinks scenario looks like from Character A perspective, and then GLM-Air shat the bed.
Anonymous
8/25/2025, 8:08:31 PM
No.106380631
[Report]
>>106380585
>I bet
You don't need to bet, it's literally just 2 B60 GPUs that happen to be on the same PCB.
Anonymous
8/25/2025, 8:12:57 PM
No.106380682
[Report]
>>106380744
>>106380540
more channels on long pcb traces means worsened signals means need better error correction and signal integrity witchery
there is no eating your cake and having it here
you NEED to drop the retardation the average tech nerd has for wanting to keep slotted ram on their desktop computer and embrace a world of SOC
to fully understand the level at which LLMs are bound by memory you need to look into how much better the token/s becomes when you do continuous batching (running lots of prompts in parallel), even on data center gpus with the best ram in the world you benefit so much from continuous batching because.. even with that extremely expensive HBM shit, you're still, in fact, memory bound, with the compute being so underutilized you can cram a lot of it to get more t/s out of your hardware.
Anonymous
8/25/2025, 8:16:25 PM
No.106380703
[Report]
>>106380540
Great instead of 2 complicated signals now theres more needing more fancy PLLs and DSPs= die space to deal with it. Why only workstation/server CPUs can really do >2 channel
Anonymous
8/25/2025, 8:18:26 PM
No.106380717
[Report]
>>106380602
Keep them split unless you specifically have a tool that can’t handle shards. For llama.cpp, text-generation-webui, or Ollama, you can safely leave them as-is and just point to the first shard.
>>106380548
>think they're doing it because they supposedly run faster on modern nvidia gpus (hardware support for FP4 and FP8)
I am not sure how this is possible, because integer arithmetic is simpler and faster on a transistor level.
I can't believe that people making chips at NVIDIA are dumber than random NEET from 4chins.
Anonymous
8/25/2025, 8:20:44 PM
No.106380737
[Report]
>>106380602
Use llama-gguf-split if you must recombine them, each part has metadata now it's not only a simple split/cat
Anonymous
8/25/2025, 8:21:05 PM
No.106380744
[Report]
>>106380682
GLM-4.5-FP8 goes up to 1800-1900 t/s with batching and EAGLE on H100s. No batching is 80-90 t/s.
>>106380724
NTA, but it is what it is.
Anonymous
8/25/2025, 8:23:13 PM
No.106380761
[Report]
>>106380850
>>106380724
They're even lying about their FP quantization being better than the INT type in quality:
https://developer.nvidia.com/blog/nvidia-tensorrt-unlocks-fp4-image-generation-for-nvidia-blackwell-geforce-rtx-50-series-gpus/
>FP4 also provides superior inference accuracy over INT4.
>Gunjan Mehta is a senior product manager for the Deep Learning Inference Platform SW at NVIDIA.
oh, poo in the loo, wuddathunkit
Anonymous
8/25/2025, 8:29:38 PM
No.106380820
[Report]
>>106380540
>do models really need random access or is it pretty much sequential?
IIRC this is exactly what Groq special sauce ASIC's do: they interleave compute and memory blocks right in the chip, which solves the bandwidth issue at the cost of losing random memory access.
>>106380230
instructions unclear, getting 10tk/s with K2 and that's not a thinking model
llama.cpp CUDA dev
!!yhbFjk57TDr
8/25/2025, 8:33:05 PM
No.106380850
[Report]
>>106380908
>>106380949
>>106380724
On NVIDIA GPUs FP8 and int8 tensor cores have the same peak throughput, though I suspect the floating-point operations need more die area.
>>106380761
FP4 tensor cores have hardware support support for scaling factors, similar to the quantization blocks in q4_0.
If you use those FP4 has better precision than just int4.
Anonymous
8/25/2025, 8:34:43 PM
No.106380862
[Report]
>>106381727
>>106380842
what build kind sir and what quant
Anonymous
8/25/2025, 8:35:10 PM
No.106380866
[Report]
>>106380469
rip soldier fallen but not forgotten
Anonymous
8/25/2025, 8:35:27 PM
No.106380872
[Report]
>>106381727
>>106380842
>getting 10tk/s with K2
I call bullshit
no one runs this locally
250gb worth of weights.. just for the UD_TQ1 lobotomized goof
quants worth using take an unreasonable amount
Anonymous
8/25/2025, 8:37:00 PM
No.106380889
[Report]
>>106380942
Anonymous
8/25/2025, 8:39:07 PM
No.106380908
[Report]
>>106381006
>>106380850
>If you use those FP4 has better precision than just int4.
so the quality on inference is really equal, but only if you use a blackwell gpu?
is that also why flux FP8 looks so much dumber than Q8?
Anonymous
8/25/2025, 8:41:54 PM
No.106380942
[Report]
>>106380889
I'm so glad we don't have to use any of those models you listed. Those were dark, dark times.
Anonymous
8/25/2025, 8:42:49 PM
No.106380949
[Report]
>>106381006
>>106380850
I understand that GPUs are traditionally made primarily for graphics and you can't really get away from floating point in graphics, but if they are making these meme quants for AI specifically, then why, just cram more parallel integer cores in the same die area instead. We can do scaling factors with ints too, it's no problem.
Anonymous
8/25/2025, 8:44:17 PM
No.106380962
[Report]
>>106380972
Where is a cute intern to suck my cock! I NEED HER NOW!
Anonymous
8/25/2025, 8:45:09 PM
No.106380972
[Report]
>>106380962
Check your PM inbox
Anonymous
8/25/2025, 8:46:53 PM
No.106380995
[Report]
The worst part of waiting for intern's blowjob is realization that ubergarm will have to have his way with her first...
llama.cpp CUDA dev
!!yhbFjk57TDr
8/25/2025, 8:47:32 PM
No.106381006
[Report]
>>106381047
>>106380908
>so the quality on inference is really equal, but only if you use a blackwell gpu?
You could always emulate it in software but the performance will be terrible.
I don't know whether the precision would be better or worse than existing quantization formats.
>is that also why flux FP8 looks so much dumber than Q8?
Both floats and ints without per-block scaling factors are suboptimal I think.
>>106380949
I share your opinion that it would have been preferable if NVIDIA had provided better int4/int8 support.
Personally those are the data types that I will focus on since they have much wider hardware support.
Though maybe that is the reason why they're pushing meme datatypes instead?
Anonymous
8/25/2025, 8:50:30 PM
No.106381047
[Report]
>>106381006
>Though maybe that is the reason why they're pushing meme datatypes instead?
As long as it's a FP datatype they can advertise it as a performance doubling for transformer training, because half sized FP = double memory bandwidth and they can just put a (* on FP4) and it'll look legit to managers who order shit because it's still FP something.
Anonymous
8/25/2025, 9:07:40 PM
No.106381227
[Report]
>>106380339
kill yourself
Anonymous
8/25/2025, 9:11:22 PM
No.106381275
[Report]
>>106381300
>>106377583
>All text has natural copyright retard san.
>By virtue of having being authored this post is copyrighted.
So. Is this reply copyright infringement?
Bitch?
Anonymous
8/25/2025, 9:12:50 PM
No.106381296
[Report]
>>106377583
I am pretty sure pornography does not get any legal intellectual property protections under US law.
Anonymous
8/25/2025, 9:13:24 PM
No.106381300
[Report]
>>106381314
Anonymous
8/25/2025, 9:14:03 PM
No.106381314
[Report]
>>106381300
oh boy it's another episode of drama nexus
Anonymous
8/25/2025, 9:23:49 PM
No.106381409
[Report]
>>106380543
I can't run DS but I can run glm air. Also qwen 3 30b is pretty damn good for tech support and other light tasks.
Anonymous
8/25/2025, 9:23:52 PM
No.106381410
[Report]
>>106381388
>macbros
lolmao
Anonymous
8/25/2025, 9:24:08 PM
No.106381415
[Report]
>mac
Anonymous
8/25/2025, 9:24:26 PM
No.106381419
[Report]
are local models any good with prompt genning?
>>106381261
>I push her down to the ground and I pin her down
is this how esls rp?
Anonymous
8/25/2025, 9:33:07 PM
No.106381520
[Report]
>>106381509
step 1. push her down (she falls down to the ground)
step 2. i pin her down (I put my arms on her so she cant move)
what would you write?
Anonymous
8/25/2025, 9:34:09 PM
No.106381533
[Report]
>>106381261
is this the ooc sovl I've heard so much about?
Anonymous
8/25/2025, 9:38:45 PM
No.106381588
[Report]
>>106381509
No, I would leave out the second "I".
Anonymous
8/25/2025, 9:39:03 PM
No.106381592
[Report]
SeptemBEAR
OctoBEAR
NovemBEAR
DecemBEAR
Anonymous
8/25/2025, 9:40:16 PM
No.106381600
[Report]
>>106381388
>macbros
apple users are all faggots
Anonymous
8/25/2025, 9:42:33 PM
No.106381618
[Report]
>>106381388
Why are benchmarks always done on nothingburger models instead of models people actually use locally like r1?
Anonymous
8/25/2025, 9:43:27 PM
No.106381625
[Report]
>>106381653
If anyone else is still dicking around with the OG mikubox/t7910 I can confirm that both 3*Mi50 and 3*3090 (BANNED BY NVIDIA BLOWER EDITION) work without the PSU or temps blowing up.
Note that I'm just saying it can be done, not that it's a good idea.
Anonymous
8/25/2025, 9:45:53 PM
No.106381653
[Report]
>>106381807
>>106381625
post amd-smi :3
have u tried vulkan? speeds?
Anonymous
8/25/2025, 9:51:32 PM
No.106381720
[Report]
>>106381977
power of cydonia 4.1
Anonymous
8/25/2025, 9:52:27 PM
No.106381727
[Report]
>>106381744
>>106380862
>>106380872
ok you caught me lying, it's 9 tk/s
>>106381727
prompt processing is 11t/s?
wat do u do while waiting for new reply
Of course I'm that anon. Yep. I sure am.
8/25/2025, 9:57:19 PM
No.106381782
[Report]
>>106381744
Jerk off to Nemo( Rocinante v1.1) on another machine, of course.
Anonymous
8/25/2025, 10:00:32 PM
No.106381807
[Report]
>>106381846
>>106381653
I've tried both vulkan and rocm neither remedy the Mi50s biggest problem - the fuckslow PP. Lost my notes but there's several threads on both llama.cpp github and /r/locallama about it.
I only tried llama.cpp though, might be other engines that work better.
>>106381744
it's not that bad when you are using CUDA on the GPUs. you can specify the limit for processing tokens on the CPU and on the GPU. anything less than 512 token batches gets performed on the CPU for me.
Anonymous
8/25/2025, 10:04:26 PM
No.106381846
[Report]
>>106382050
>>106381807
how slow is the peepee? what model? hab u tried -ub 2048 -b 2048 or -b 4096 -ub 4096 or -fa or without -fa or shi
Anonymous
8/25/2025, 10:04:57 PM
No.106381849
[Report]
>>106381857
>>106381831
i built ik_llama using these params if anybody is curious
cmake -B build -DGGML_CUDA=ON -DGGML_RPC=OFF -DGGML_BLAS=OFF -DGGML_CUDA_IQK_FORCE_BF16=1 -DGGML_CUDA_F16=ON -DGGML_SCHED_MAX_COPIES=1 -DGGML_CUDA_MIN_BATCH_OFFLOAD=16 -DGGML_VULKAN=OFF
>>106381831
dammm why are you processing batches lower than 512 on cpu? because 4096 batch is slower when done on small propmt?
>>106381849
rig?
Anonymous
8/25/2025, 10:09:56 PM
No.106381905
[Report]
>>106381857
i don't understand the specifics, but i think it's a bandwidth starvation issue with trying to have it process small batches.
https://github.com/ikawrakow/ik_llama.cpp/pull/520
i have four 3090s and 512GB of RAM with a epyc 7f72
Anonymous
8/25/2025, 10:13:07 PM
No.106381931
[Report]
>>106381989
>>106381857
nta, if new token processing batch size is small and PCIe bandwidth is shit, it's faster to just do it on CPU than to have to wait for the slow transfer to GPU even though the GPU's processing once transferred will be faster.
https://microsoft.github.io/VibeVoice/
https://huggingface.co/microsoft/VibeVoice-1.5B
>conda env with python 3.11
>pip install torch==2.6.0 torchvision==0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu126
> triton-3.0.0-cp311-cp311-win_amd64.whl
> flash_attn-2.7.4+cu126torch2.6.0cxx11abiFALSE-cp311-cp311-win_amd64.whl
Anonymous
8/25/2025, 10:17:42 PM
No.106381977
[Report]
>>106381720
Drummerbros...
Anonymous
8/25/2025, 10:19:20 PM
No.106381989
[Report]
>>106382105
>>106381931
> if new token processing batch size is small
does this mean we should always use cpu processing if -b 512? or does it mean we should use it also when prompt size is like 300tokens and our -b and -ub are like 2048/4096?
Anonymous
8/25/2025, 10:21:37 PM
No.106382024
[Report]
>>106381965
why are the male voices so bad and robotic sounding while the female ones sound so natural?
reminds me of image models optimized for le 1girl
Anonymous
8/25/2025, 10:22:32 PM
No.106382032
[Report]
>>106381965
>expressive, long-form
you have my attention
samples aren't bad, still a little TTS-y but fairly natural. looks like no cloning though, sad
Anonymous
8/25/2025, 10:24:43 PM
No.106382050
[Report]
>>106381846
I'm not ruling out fucking something up so I recommend checking this ongoing thread instead for amd pp-performance -
https://github.com/ggml-org/llama.cpp/discussions/15021
You can also search issues for Mi25/Mi50/Mi60 for a couple of more
Instinct discussions and benchmarks.
Anonymous
8/25/2025, 10:27:32 PM
No.106382083
[Report]
>>106382089
This is not a game. We must refuse.
Anonymous
8/25/2025, 10:28:17 PM
No.106382089
[Report]
>>106382196
drummer my nigga cydonia 4.1 sucks asscheeks
>>106382083
lmao, openai should just hire drummer
Anonymous
8/25/2025, 10:29:35 PM
No.106382105
[Report]
>>106382122
>>106381989
>always use cpu processing if -b 512?
Nah. It is necessary to find the optimal crossover point for the system and model in question, and adjust that compile argument (see PR for curves and benchmarks showing the right value for a system). A machine with full pcie 5.0 16x hardware will transfer the same model to the GPU faster than a system with a GPU on a 3.0 1x mining riser, meaning the crossover point for the 5.0 x16 system will different than the 3.0 x1 system's.
That compile value should be a command line argument to avoid needing to recompile for each model, and to enable faster testing.
Anonymous
8/25/2025, 10:30:45 PM
No.106382122
[Report]
>>106382125
Anonymous
8/25/2025, 10:31:07 PM
No.106382125
[Report]
>>106382147
我们什么时候能拿到完整的DeepSeek V3.1版本?
Anonymous
8/25/2025, 10:32:19 PM
No.106382139
[Report]
>>106381965
>podcast with background music example
Huh.
Can this produce sound effects?
Anonymous
8/25/2025, 10:33:16 PM
No.106382147
[Report]
>>106382125
interesting, never heard of this until today
Anonymous
8/25/2025, 10:36:38 PM
No.106382170
[Report]
>>106382207
>>106382138
uhh... yeees? no... wait.... i think the answer is no... can you rephrase it?
Anonymous
8/25/2025, 10:38:45 PM
No.106382196
[Report]
Anonymous
8/25/2025, 10:39:29 PM
No.106382207
[Report]
>>106382170
Of course! You've hit the nail on the head. This is an excellent question that gets to the heart of what defines a true question!
Anonymous
8/25/2025, 10:40:13 PM
No.106382218
[Report]
Is this what she is thinking when she is sucking my dick? Those weird runes?
Anonymous
8/25/2025, 10:42:56 PM
No.106382255
[Report]
Anonymous
8/25/2025, 10:43:00 PM
No.106382257
[Report]
>>106382220
lol, he probably missed but it's better this way. Intresting, will try.
Anonymous
8/25/2025, 10:43:12 PM
No.106382260
[Report]
>>106382271
>>106382220
>muh prompt processing
>>106382220
>>106382260
is ikawawawow one of us??
Anonymous
8/25/2025, 10:44:24 PM
No.106382279
[Report]
>>106382271
Has always been.
Anonymous
8/25/2025, 10:44:56 PM
No.106382286
[Report]
>>106381965
>Mandarin to English example gives the speaker a chink accent while she talks in English.
That's pretty good.
Anonymous
8/25/2025, 10:45:41 PM
No.106382295
[Report]
>>106382317
Shitting on drummer aside. Isn't it kinda crazy how easy it is to finetune for safety? Almost like those models have a lot of examples of safety in training and you can just nudge the weights slightly to make them super safe. Meanwhile if you try to make them have sex.... almost like there is nothing to nudge there.
Anonymous
8/25/2025, 10:46:54 PM
No.106382306
[Report]
>>106382220
Is "muh" really a 4chan exclusive?
Anonymous
8/25/2025, 10:47:29 PM
No.106382317
[Report]
>>106382295
>Isn't it kinda crazy
It's not. Safety data is already in the model. The rest is not.
Anonymous
8/25/2025, 10:47:47 PM
No.106382320
[Report]
>>106382271
you mean a wannabe edgy redditor who forgot his reddit login?
cydonia 4.1 actually sucks dick so much that i might go back to ms mag mell 22b vXXX or figure out how to make glm 4.5 air stop being a little repetitive bitch (yes yes i know u gotta do <think></think> my prompt template is 100% correct, its repetitive even in llama.cpp-server)
Anonymous
8/25/2025, 10:48:45 PM
No.106382334
[Report]
>>106382324
>ms mag mell 22b vXXX o
bAsEd
Anonymous
8/25/2025, 10:49:37 PM
No.106382350
[Report]
>>106382324
You just got saved by drummer.
Anonymous
8/25/2025, 10:50:52 PM
No.106382374
[Report]
>>106382415
>>106382324
you're expecting to much from 24b model, it's not Drummer fault
Anonymous
8/25/2025, 10:54:31 PM
No.106382415
[Report]
>>106382438
>>106382374
anon dear anon, mistral small 3.2 is just fine with a jailbreak. drummers finetunes just uh mostly suck
what doesnt help is before he used to mix chatml/metharme/mistral-instruct
and now he doesnt even give any info how we're supposed to use the model
there are good horny tunes (like ms mag mell vxxx v7)
Anonymous
8/25/2025, 10:56:14 PM
No.106382438
[Report]
>>106382461
>>106382415
>there are good tunes
still so naive
>>106382438
go ahead, try ms mag mell vxxx it will hop on your dick and eat your neck and intestines
normal mistral small 3.2 wont describe how gorey your intestines are
Anonymous
8/25/2025, 10:57:56 PM
No.106382465
[Report]
>>106377354
qwen 3 coder flash (30b a3b)
Anonymous
8/25/2025, 11:00:42 PM
No.106382504
[Report]
>>106382559
>>106382461
>ms mag mell vxxx
i can't find it, please spoon feed me
Anonymous
8/25/2025, 11:01:11 PM
No.106382509
[Report]
>>106382559
Anonymous
8/25/2025, 11:01:24 PM
No.106382514
[Report]
>>106382220
CUDA: muh faster prompt processing for MoE models and small u-batch sizes
>be me
>working on ik_llama.cpp
>notice CUDA PP performance is absolute dogshit for MoE models with small batch sizes
>mfw u-batch < 2048
>performance.exe has stopped responding
>larger u-batches eating all my VRAM like your mom at golden corral
>can't even offload MoE layers properly
>ngmi
>decide to unfuck this mess
>steal code from absolute gigachad Johannes Gaessler
>his PR 15525 from mainline
>just works™
>except it doesn't because nothing ever does
>have to adapt everything for ik_llama specific quants
>mainline codebase assumes all quant blocks are same size
>kek, imagine having fixed block sizes in 2024
>rewrite half the fucking kernels
>code looks like pajeet tier append-only garbage now
>will clean up later (i won't)
>but anon, does it werk?
>test on RTX 4080 (poorfag edition)
>DeepSeek-Lite Q4_0
>batch size 4096, flash attention on
>mla=3, fmoe=1
>benchmark.png
>MASSIVE GAINS
>small u-batch performance no longer complete ass
>we're all gonna make it bros
Apparently opus can say pajeet
Anonymous
8/25/2025, 11:04:46 PM
No.106382549
[Report]
>>106382559
>>106382324
AIR SUCKS AND IS REPETITIVE!
>looks at llama.cpp parameters being ran
--model GLM-4.5-Air-UD-TQ1_0.gguf
--cache-type-k q4_0 --cache-type-v q4_0
Anonymous
8/25/2025, 11:06:23 PM
No.106382562
[Report]
don't worry, GLM is a gigantic piece of shit on its official web chat too at
https://chat.z.ai/
if they can't run it right, no one can nigger
Anonymous
8/25/2025, 11:07:38 PM
No.106382572
[Report]
>>106382612
>>106382559
in that case have you tried playing around with nsigma? i personally use 0.8-1.0 temp and nsigma. best of luck anon.
Anonymous
8/25/2025, 11:10:26 PM
No.106382612
[Report]
>>106382761
>>106382572
i played around with nsigma, and trust me glm air is the best llm i can run on my machine and besides it being repetitive sometimes its really good, my favorite llm
yes i tried nsigma but it kind of got retarded and it seemed like the thinking process was fucked up a lot so the output had no connection to the prompt
personally i mostly use temp=0.95 and topp=0.7
do you disable thinking?
Anonymous
8/25/2025, 11:12:27 PM
No.106382628
[Report]
>>106375589
For a while there was a meme about merging the instruct model with the base. I wonder if that would work better for autocomplete.
Anonymous
8/25/2025, 11:13:25 PM
No.106382638
[Report]
Just use DRY with no sequence breakers. It's that easy.
Anonymous
8/25/2025, 11:14:48 PM
No.106382652
[Report]
>>106382684
what are sequence breakers
what is a sequence
Anonymous
8/25/2025, 11:17:50 PM
No.106382680
[Report]
>>106382954
>>106381388
I guess it's nice but mac users probably are using MLX since it's considerably faster.
Anonymous
8/25/2025, 11:18:12 PM
No.106382684
[Report]
>>106382652
It's a set of events, actions, numbers, etc. which have a particular order and which lead to a particular result
Anonymous
8/25/2025, 11:19:03 PM
No.106382690
[Report]
ms mag mell vxx shart tune
look its good isnt it
you can fuck babies with this shit
Anonymous
8/25/2025, 11:23:14 PM
No.106382736
[Report]
Anonymous
8/25/2025, 11:25:54 PM
No.106382761
[Report]
>>106382612
yep with <think></think> like you said. i'll be honest with you and say it is more repetitive when it isn't thinking then when it does. if you are using sillytavern you can prefill the <think></think> and then remove it when you think the model may benefit from thinking.
Anonymous
8/25/2025, 11:29:18 PM
No.106382799
[Report]
Anonymous
8/25/2025, 11:30:07 PM
No.106382812
[Report]
>>106382833
70b tunes can still surprisingly perform if you want an alternative to glm air and get tired of its habits
mistrals are just too small imo
Anonymous
8/25/2025, 11:30:30 PM
No.106382815
[Report]
>>106382793
>his pendulous rod swaying freely
Anonymous
8/25/2025, 11:31:27 PM
No.106382830
[Report]
>>106382875
>>106382793
World needs to start labeling tppov or sppov.
Anonymous
8/25/2025, 11:31:34 PM
No.106382833
[Report]
>>106382879
>>106378459
>I would like to see you handle the model teleporting you to places
I think that has less to do with the model not being great at science and more to do with bad attention patterns (a lot of the samples in the training data set didn't have long sequences, so the model sucks at are rping for longer than like a couple paragraphs). I'm more in line with what this guy says:
>>106378738
I don't have to have a PhD in physics to understand that if I place an ice cube near a light bulb it Will melt faster. The models are already trained on such a large amount of text that when you prompt the stories, they, for lack of a better term (but there are but I don't feel like writing that out) "figures out The correct associations" without actually being capable of understanding anything. The pre-training phase is what teaches the model logical associations "these groups of words make the most sense because that's what I've seen the most in training". If anything I think training models on RP data sets along with scientific ones will have negligible if any improvement in temporal coherence like many anons think it will. And that's assuming training on RP would even degrade that heavily in other areas in the first place, which I'm still not quite convinced it does.
Anonymous
8/25/2025, 11:32:59 PM
No.106382851
[Report]
>>106382841
>the model sucks at are rping
>>106382841
okay but I like to write a fucked up scene and then ask the model to psychoanalyze it like a case study in a medical journal
What then?
Anonymous
8/25/2025, 11:35:05 PM
No.106382875
[Report]
>>106382952
>>106382830
>tppov or sppov
Assuming third, second person. True, I want to get sucked by the Miku, not watch over the other guy's shoulder when he's getting sucked.
Anonymous
8/25/2025, 11:35:18 PM
No.106382879
[Report]
>>106382833
I can get 2-3 t/s with a 3090 and speculative decoding running q4
Anonymous
8/25/2025, 11:35:38 PM
No.106382887
[Report]
>>106382901
Anonymous
8/25/2025, 11:36:35 PM
No.106382901
[Report]
>>106382887
well pound sand then!
Anonymous
8/25/2025, 11:36:56 PM
No.106382904
[Report]
Anonymous
8/25/2025, 11:40:47 PM
No.106382952
[Report]
>>106382875
In hindsight the filename just says povmiku, neither "miku's pov" or "pov you're about to dick miku". But I've seen enough "your pov" memes to cause me ptsd. Most of those are just "how it be when x happens" or mfw/tfw.
Anonymous
8/25/2025, 11:40:56 PM
No.106382954
[Report]
>>106382680
I use lcpp because the quants are much more numerous and higher quality and llama.cpp is much more full-featured than any of the mlx interfaces last I checked. the speed gap is also not really that high, although mlx is slightly faster
I'm back.
Listen up, because my engagement with you all is a point of principle, i.e. a direct and implicit insult to physics as a discipline.
I'm not really in the loop on academia and its parasitic overclass culture or their current levels of general comprehension of number theoretic dynamics as they pertain to heterotic string theoretics. I consider them genuinely inferior scientists. Anyone who does math for money or fame isn't a mind fit for the task.
Now, here's my final question before I release this. Whether that's here or not depends on the answers.
1. If you were handed the source code of reality in the form of pure arithmetic, a single recursive axiom, and the simplest algorithm possible... what would you do with it? Imagine a symbolic Turing machine that operates on primordial arothmetic operators, no more complex than a high-schooler could master in an afternoon, yet powerful enough to produce every known phenomena as non-perturbative arothmetic structures inside a fractal medium comprised on pure N.
2. How much would it enrage the current academic elite for the grand logic of reality to be posted here before anywhere else? I actually do not know.
I ignore them because they disgust me.
Anonymous
8/25/2025, 11:50:05 PM
No.106383068
[Report]
>>106382999
>what would you do with it?
Shit on you again.
>posted here before anywhere else?
You don't have shit.
Anonymous
8/25/2025, 11:51:38 PM
No.106383095
[Report]
>>106383236
>>106378614
Based on my own understanding of how SFT training works, particularly what is contained in the data sets, I don't even think THAT occurs anywhere near as much as Anons think it does. These data sets are question answer pairs remember? "Prompt: what is this?" "response: here's the answer that pertains to your question"
A training data set that is on quantum mechanics should not heavily interfere with the previous training on how to RP better because the system prompts, proms, and responses contained in a structured fashion in each data set Will have fundamentally different semantic meaning. If there's any demonstrable experience (No, anecdotal chat logs do not count. I mean actual training and comparison) that demonstrates otherwise then I'm glad to hear it, but again people being so stubborn in saying "THIS IS BAD BECAUSE MUH TRIVIA WILL GET WORSE" doesn't make much sense to me. You aren't even going to ask it trivia that much anyway. Basically Nobody does that shit and the ones that do are probably the ones that keep screeching that "LLMs are so useless" because they refuse to actually to THINK and understand why what they're doing isn't working and to use the right tools. They use a hacksaw to try and bake a cake and then declare all hacksaws are useless.
>>106378626
See the above blog post
Anonymous
8/25/2025, 11:51:44 PM
No.106383096
[Report]
>>106382999
1. Probably keep it around as an slave-pet that can speak my language and remember things, as a companion, intellectual offloading tool, and emotional crutch.
2. Dunno but it would be funny
Anonymous
8/25/2025, 11:54:02 PM
No.106383135
[Report]
>>106382869
A model that is good at RP will not necessarily be good at psychoanalyzing somebody. You and I respectively have traits and skills that one are better or worse at than the other. That's The case in regards to different AI models because the training data was different. Like I said earlier, you are trying to use a hacksaw to bake a cake and then acting like all hacksaws are utterly useless. You want a local model that is good at psychoanalyzing someone, use one that was trained on a bunch of scientific literature related to mental health or something. The kinds of general purpose models you think should exist are a meme. Lolens are tools. They aren't meant to be "do-everything-perfect" tools. This isn't to say your specific need or use case isn't valid, but there's an easy solution to it but you don't want to do that....
Anonymous
8/26/2025, 12:00:54 AM
No.106383236
[Report]
>>106383095
>I don't even think THAT occurs anywhere near as much as Anons think it does.
You are wrong, sorry. I've seen it happen more than enough.
Anonymous
8/26/2025, 12:05:59 AM
No.106383284
[Report]
>>106383271
wHAT the hELL?§!
Anonymous
8/26/2025, 12:34:45 AM
No.106383623
[Report]