/lmg/ - Local Models General
►Recent Highlights from the Previous Thread:
>>106497597
--Multi-GPU server hardware choices for DDR5 and NUMA optimization:
>106501160 >106501257 >106501342 >106501360 >106501442 >106501465 >106501290 >106501297 >106501417
--Token speed estimates for LLMs using GIGABYTE CXL memory card vs VRAM configurations:
>106498668 >106498678 >106498702 >106499735 >106499745 >106498766
--Optimizing VibeVoice-Large model for efficient speech generation and voice sample cleanup:
>106498676 >106498704 >106498714 >106499018 >106499389 >106499448 >106499466 >106499831 >106499967 >106500073 >106500670 >106500879 >106501145 >106501158 >106501172 >106501230 >106499863 >106499875 >106499907 >106499916 >106500081 >106500089 >106500140 >106503518
--Model recommendations for average gaming hardware with VRAM constraints:
>106502406 >106502445 >106502478 >106502521 >106502528 >106502551 >106502813 >106502914 >106502932 >106502986
--Interpretation of llama_backend_print_memory output for GPU/CPU memory usage:
>106501583 >106501653 >106501677 >106501706 >106501727 >106501822 >106501932
--DDR5 vs DDR4 tradeoffs for CPUmaxx systems with GPU support:
>106503602 >106503731 >106503756 >106503762 >106503824 >106503854 >106504044
--VibeVoice model optimization and download link:
>106498428 >106498434 >106498959 >106499005
--Anthropic's $1.5B AI settlement criticized for insufficient compensation and stifling innovation:
>106499477 >106499488 >106499521 >106499499 >106499518 >106499574 >106499693 >106502081
--AMD FlashAttention workarounds and text-to-speech project updates:
>106499449 >106499480 >106499614 >106500912
--VibeVoice TTS compatibility with quantized 7b models on low-resource hardware:
>106501006 >106501612
--Miku (free space):
>106498210 >106500301 >106503405 >106503587
►Recent Highlight Posts from the Previous Thread:
>>106497599
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
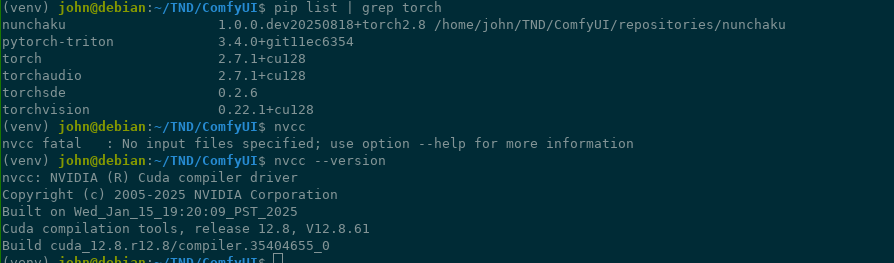
>update debian 13 to debian 13.1
>picrel
Anonymous
9/6/2025, 8:13:28 PM
No.106504433
[Report]
>>106504130
No, sometimes it picks up things from context and decides what direction and inflection to take from there but the biggest factor is the original sample voice it clones, if it has a lot of angry yelling and annoyance that will be reflected in the result, so maybe have several emotion samples for the same voice set as different voices?
Anonymous
9/6/2025, 8:14:05 PM
No.106504444
[Report]
>>106504276
Thank you Recap Recap Miku
>>106503862
So much technical support is behind closed doors in discord, it makes no sense, the platform was never meant to do that, and now many issues will never be discussed in the open, helping no one.
Anonymous
9/6/2025, 8:14:49 PM
No.106504456
[Report]
>>106504485
>>106504377
just reinstall cuda 12.8
Anonymous
9/6/2025, 8:15:59 PM
No.106504470
[Report]
>>106504448
It's an actual tragedy.
Anonymous
9/6/2025, 8:16:27 PM
No.106504477
[Report]
>>106504377
Not like this, John.
Anonymous
9/6/2025, 8:17:14 PM
No.106504485
[Report]
>>106504508
>>106504456
i am using cuda 12.8
Anonymous
9/6/2025, 8:18:07 PM
No.106504495
[Report]
>>106504514
>>106504448
Zoomers seem to love it, probably because it's simpler than using an actual support forum.
Yet in high traffic ones it's almost unusable.
Anonymous
9/6/2025, 8:19:14 PM
No.106504508
[Report]
>>106505014
>>106504485
yes get rid of it and reinstall 12.8
Anonymous
9/6/2025, 8:19:40 PM
No.106504514
[Report]
>>106504538
>>106504495
>Yet in high traffic ones it's almost unusable.
so much activity is probably a big part of the attraction to those with dysfunctional attention spans
Anonymous
9/6/2025, 8:19:49 PM
No.106504515
[Report]
>>106504448
yeah it fucking sucks
Anonymous
9/6/2025, 8:20:19 PM
No.106504520
[Report]
>>106504582
>>106504448
what kills me are the projects doing that shit, choosing to use discord
Anonymous
9/6/2025, 8:21:53 PM
No.106504538
[Report]
>>106504547
>>106504514
It's just memes and mundane chat spam, it makes finding useful discussions hard, especially with discord's fuzzy search.
Anonymous
9/6/2025, 8:23:03 PM
No.106504547
[Report]
>>106504538
And then there's the moderators.
Anonymous
9/6/2025, 8:25:53 PM
No.106504582
[Report]
>>106504964
>>106504520
If they're pros, I think they're just treating it as a free Slack. Except Slack is optimized for internal discussion with teams of people there to do a job, not thousands of overexcited zoomies.
I actually wonder if discord datasets exist and are used in LLM training.
Anonymous
9/6/2025, 8:39:13 PM
No.106504702
[Report]
>>106504969
anon, when you walk away do you hear me say please oh baby dont go?
Anonymous
9/6/2025, 8:39:34 PM
No.106504704
[Report]
The tokens might a statistical representation of language but the boners are real.
Anonymous
9/6/2025, 9:07:34 PM
No.106504958
[Report]
>>106504832
Cum on Miku's feet*
Anonymous
9/6/2025, 9:08:55 PM
No.106504964
[Report]
>>106505136
>>106504448
I mean, there will be a big loss of data for stuff like that from around 2015 onwards but given I am fairly adept technically so it doesn't bother me and you still can find help elsewhere, it's just in much less volume.
>>106504582
I am guessing it is valuable to some extent for data about zoomers and younger folks but I wonder how valuable it is when that demographic itself are the most affected by LLM and internet culture regurgitation and mind numbing retardation in general. No question though, the RP logs probably are equal if not 2nd to the RP forum scrapes given CAI seemed to have trained on them for their 2022 bot that everyone yearns for.
Anonymous
9/6/2025, 9:09:15 PM
No.106504969
[Report]
>>106504702
It sends a shiver down my spine. Something primal...
Anonymous
9/6/2025, 9:13:00 PM
No.106505014
[Report]
>>106504508
i fixed it by updating my chroot aswell
Anonymous
9/6/2025, 9:18:24 PM
No.106505064
[Report]
>>106505094
Does my Alice sound Alicey enough?
https://vocaroo.com/1jAce1dHRBYD
I think it sound really muffled because I ran it through a voice cleaning model to get rid of music, but maybe it enhances the 50's mic aesthetic
Anonymous
9/6/2025, 9:18:34 PM
No.106505066
[Report]
>>106504242
The only software optimization left is 1-2B active routed expert models.
Anonymous
9/6/2025, 9:18:49 PM
No.106505070
[Report]
>>106504377
Bro you installed pytorch without cuda support
Anonymous
9/6/2025, 9:20:48 PM
No.106505094
[Report]
>>106505103
>>106505064
It sounds great, especially
>a den of hedonous virgins
Anonymous
9/6/2025, 9:21:02 PM
No.106505098
[Report]
>>106506266
>>106504242
Retardo, without the current software optimization you'd need a datacenter to run these models
Anonymous
9/6/2025, 9:21:19 PM
No.106505103
[Report]
>>106505094
heathenous ackshully
Anonymous
9/6/2025, 9:24:38 PM
No.106505136
[Report]
>>106504964
>that demographic itself are the most affected by LLM and internet culture regurgitation and mind numbing retardation in general
If you mean the constant virtue signaling, it's mostly a fake persona they all share in public places because they just are terrified of being judged by their friends (who are obviously also online).
>No question though, the RP logs probably are equal if not 2nd to the RP forum scrapes given CAI seemed to have trained on them for their 2022 bot that everyone yearns for.
CAI was so good and showed that outside of the big public servers, you probably have plenty small ones where a lot more is discussed freely.
Anonymous
9/6/2025, 9:27:32 PM
No.106505168
[Report]
Did I miss a guide or link on OP to teaching me about using TTS in Sillytavern? Could someone kindly point me the right way if there is one?
Anonymous
9/6/2025, 9:35:07 PM
No.106505235
[Report]
>>106505288
I await my magnum v5.
Anonymous
9/6/2025, 9:36:52 PM
No.106505246
[Report]
Anonymous
9/6/2025, 9:41:03 PM
No.106505276
[Report]
>>106505293
really sick of comfyui. is there any other interface for vibevoice?
>>106505235
Why is her ass pointed at me? I am offended.
Anonymous
9/6/2025, 9:42:24 PM
No.106505293
[Report]
>>106505421
>>106505276
the original gradio interface it comes packaged with?
Does anyone have Q4 of VibeVoice?
Anonymous
9/6/2025, 9:54:10 PM
No.106505408
[Report]
>>106505418
>>106505316
Buy a computer rajesh
Anonymous
9/6/2025, 9:56:14 PM
No.106505418
[Report]
>>106505430
>>106505408
>still obsessed with trannies, politics and indians
Anonymous
9/6/2025, 9:56:29 PM
No.106505421
[Report]
>>106505463
>>106505316
It's not prequalted, people load regular fp16 model in 4 bits. try
https://github.com/wildminder/ComfyUI-VibeVoice
Anonymous
9/6/2025, 9:57:24 PM
No.106505430
[Report]
Anonymous
9/6/2025, 9:57:31 PM
No.106505431
[Report]
>>106505422
man please, is there any other UI? I hate how bloated that piece of shit UI is
2 million context window
for free
and you keep using your local slop
smhtbhfamalam
Anonymous
9/6/2025, 9:58:55 PM
No.106505447
[Report]
>>106505422
Ok thanks, I'll take a look. I want it to be as small as possible because I'll be running it alongside LLM.
Anonymous
9/6/2025, 9:59:08 PM
No.106505450
[Report]
>>106505288
so you can j-j-jam it in
Anonymous
9/6/2025, 10:00:14 PM
No.106505463
[Report]
>>106505491
>>106505421
find one of the forks before MS wiped it
Anonymous
9/6/2025, 10:02:02 PM
No.106505478
[Report]
>>106505288
she is nervious and preparing her stink glands
Anonymous
9/6/2025, 10:03:46 PM
No.106505483
[Report]
>>106505444
These local clowns dont know what they are missing out on
Anonymous
9/6/2025, 10:05:07 PM
No.106505491
[Report]
>>106505609
>>106505463
no UI just example scripts. these jeets just shipped it cli wtf
Anonymous
9/6/2025, 10:05:21 PM
No.106505493
[Report]
>>106505499
>>106505444
have fun sending your life history to google
Anonymous
9/6/2025, 10:06:06 PM
No.106505499
[Report]
Anonymous
9/6/2025, 10:06:20 PM
No.106505500
[Report]
TTS-occupied thread.
>>106505490
I wonder if these constant hype videos still work
Anonymous
9/6/2025, 10:08:44 PM
No.106505527
[Report]
>>106505432
take the inference code from the node and use it wherever you want
Anonymous
9/6/2025, 10:09:07 PM
No.106505530
[Report]
>>106505560
>>106505507
wouldn't keep making them if they didn't
Anonymous
9/6/2025, 10:13:41 PM
No.106505559
[Report]
>>106505507
every slopwatcher is desensitized. so basically that thumbnail is appropiate and almost falls in the
>oh he's not overly estatic, maybe it's a cool niche channel with good content
category
Anonymous
9/6/2025, 10:13:43 PM
No.106505560
[Report]
Anonymous
9/6/2025, 10:13:57 PM
No.106505564
[Report]
>>106505572
>>106505432
Be the change you want to see dumbo
Anonymous
9/6/2025, 10:15:13 PM
No.106505572
[Report]
>>106505596
>>106505564
I'm going to steal this
https://github.com/wildminder/ComfyUI-VibeVoice
And implement it externally. It should be pretty straightforward.
Anonymous
9/6/2025, 10:18:06 PM
No.106505596
[Report]
>>106505641
>>106505572
if you do it without the comfy backend I would like to make a plugin for anistudio off of it. hot reloading is solved in dev so I'd like to make a few examples of models not supported in ggml yet
Anonymous
9/6/2025, 10:20:08 PM
No.106505609
[Report]
>>106505491
CLI is all you need.
Anonymous
9/6/2025, 10:20:55 PM
No.106505619
[Report]
Imagination is all you need.
Anonymous
9/6/2025, 10:21:02 PM
No.106505620
[Report]
>>106505628
qwen image on 3060
1minute 10s with 110w/170w power limit
Anonymous
9/6/2025, 10:22:02 PM
No.106505628
[Report]
>>106505638
Anonymous
9/6/2025, 10:23:12 PM
No.106505638
[Report]
>>106505628
local miku general
Anonymous
9/6/2025, 10:23:41 PM
No.106505641
[Report]
>>106505673
>>106505596
I'm not a "real" dev but I am strongly suspecting that I'm able to hack something together. Please don't hold your breath still...
Been working on lots of stuff lately.
Anonymous
9/6/2025, 10:27:22 PM
No.106505673
[Report]
>>106505641
you and me both. my uncle died yesterday so a lot of time has been with the family. shit sucks but at least work was done despite the depression. wan support was added to sdcpp recently so I think it's almost time to get the memory management and node interface in. it's been a lot of cmake garbage juggling for the past while and I'm sick of it
mikujanny theorists what is your explanation?
Anonymous
9/6/2025, 10:40:52 PM
No.106505814
[Report]
>>106505758
I would argue (and I do) that the wizardlm debacle was more ridicilious. Some say it is still undergoing toxicity testing to this day
>>106505757
nobody cares it took a glacial ice age to inference and image edit on your vramlet card
>>106505758
the furk? Isn't that an /ldg/ meme man?
Anonymous
9/6/2025, 10:43:47 PM
No.106505848
[Report]
>>106505881
>>106505834
but 1 minute and 10s is pretty good for a 17b model with cfg and at 20 steps.. with a 110w pl
Anonymous
9/6/2025, 10:46:12 PM
No.106505881
[Report]
>>106505920
>>106505848
this is the llm thread. most people here are vramlet at 48gb. just go seek attention at the diffusion threads, there are four at this point and you chose this one instead. you are fucking retarded. tts is fine because there isn't anywhere else to discuss it
Anonymous
9/6/2025, 10:50:11 PM
No.106505920
[Report]
>>106505933
>>106505881
>tfw 32gb vramlet
My cope is that qwen3 30b is good enough.
Anonymous
9/6/2025, 10:51:27 PM
No.106505933
[Report]
Anonymous
9/6/2025, 10:53:59 PM
No.106505963
[Report]
>>106505834
>/ldg/ meme man
do not being ridicilious
Anonymous
9/6/2025, 10:54:10 PM
No.106505966
[Report]
Anonymous
9/6/2025, 11:01:05 PM
No.106506018
[Report]
>>106505952
ugh i need it so bad
Anonymous
9/6/2025, 11:02:25 PM
No.106506032
[Report]
>>106505952
DO NOT RELEASE!
Anonymous
9/6/2025, 11:07:04 PM
No.106506079
[Report]
>>106505952
>"w-what the fuck is this? A DENSE 120B MODEL? HOW WILL MY MOESISSY RIG EVEN RUN IT?"
and just like that benchmaxxing moe chinks lost
While looking into lossy text compression I found
https://www.rwkv.com/ and have fallen into a little bit of a rabbit hole
>10/10 logo
>the official AI of Linux Foundation
>100% attention-free
>weird enough architecture that it needs its own software stack
>supposedly 400+ derivative projects
>no buzz whatsoever about it
Their models are tiny (~3B and less for main offerings) so probably not useful for anything, but I am curious about supposed speed benefits and wanted to run some performance benchmarks against similarly sized transformers-based models.
But it's fucking python.
There are goofs on hugging face by literally who's but I suspects they are just crude conversions that loose all architecture buffs.
Should I give up on Arch and install Debian or it wouldn't help much?
>>106506094
RWKV is a meme model.
Anonymous
9/6/2025, 11:11:25 PM
No.106506115
[Report]
>>106506094
if u install debian you should use debian 12 because debian 13 has no official support for cuda yet (you have to modify some things because of glibc...)
also >rwkv
sweet summer chld
Anonymous
9/6/2025, 11:11:35 PM
No.106506116
[Report]
>>106506094
this thing has been trying to become something for years now, all the models are a shit
Anonymous
9/6/2025, 11:11:48 PM
No.106506119
[Report]
>>106506094
>RWKV (pronounced RwaKuv)
I hate maths people.
Anonymous
9/6/2025, 11:12:13 PM
No.106506122
[Report]
>>106506133
>>106506094
>rwkv
just wait until you hear about retnet and you'll be all caught up when it comes to memes people thought would totally replace transformers soon back in 2023
>>106506112
RWKV models are installed on every Windows machine, making them the most successful models
Anonymous
9/6/2025, 11:13:44 PM
No.106506133
[Report]
>>106506122
just two more years bro
Anonymous
9/6/2025, 11:14:57 PM
No.106506145
[Report]
>>106506171
Anonymous
9/6/2025, 11:16:47 PM
No.106506157
[Report]
the new kimi 0905 is fire.
just prompted a few medical questions on openrouter and benchmaxxed against gpt5/gemini2.5pro/opus4.1/qwenmax. (openrouter system prompt off, no websearch). there were always 1-2 good additional points in the kimi answers the other models didn't bring up. I'd accuse alibaba of prompt enhancing my query or using web search stealthly with the api call, but kimi responds so fucking fast, there's no way that's happening. So yeah, idk wtf's going on.
>>106506112
I love meme models
>>106506129
So I should install Windows 11 instead of Debian, huh.
Anonymous
9/6/2025, 11:18:41 PM
No.106506171
[Report]
>>106506185
>>106506145
some intern probably added rwkv model loading to some copilot function to fuck around with it for an afternoon and they shipped the binaries by accident
Anonymous
9/6/2025, 11:19:20 PM
No.106506177
[Report]
qwen takes 70-80s per image on 3060
nice
Anonymous
9/6/2025, 11:19:42 PM
No.106506180
[Report]
>>106506168
>So I should install Windows 11 instead of Debian, huh.
It only supports up to RWKV5 and they're up to 7 now.
Anonymous
9/6/2025, 11:20:23 PM
No.106506185
[Report]
Anonymous
9/6/2025, 11:20:39 PM
No.106506187
[Report]
>>106506197
>>106506168
>Windows 11
make sure to turn on recall! its a super helpful feature that is of course extremely secure and would never be misused by anyone.
Anonymous
9/6/2025, 11:22:12 PM
No.106506197
[Report]
>>106506216
>>106506187
they said it's local* so it's ok
*local at time of recording and storage in plain text, they never promised not to upload it as part of telemetry
Anonymous
9/6/2025, 11:24:05 PM
No.106506216
[Report]
>>106506197
I mean it's very smart, make the user use their compute and electricity to process the data then send yourself the compressed telemetry result, probably gives massive savings
Anonymous
9/6/2025, 11:26:15 PM
No.106506228
[Report]
>>106506279
>>106505757
was that a hecking racism you posted?
Anonymous
9/6/2025, 11:30:08 PM
No.106506258
[Report]
>>106504276
lmao at the image that's brilliant
Anonymous
9/6/2025, 11:30:49 PM
No.106506266
[Report]
>>106505098
We still need a datacenter to train models, which is the main innovation bottleneck.
Anonymous
9/6/2025, 11:31:35 PM
No.106506274
[Report]
>>106505288
It's your new home
Anonymous
9/6/2025, 11:31:49 PM
No.106506279
[Report]
>>106506228
yeah image of hatsune miku holding a naughty sign
Anonymous
9/6/2025, 11:35:44 PM
No.106506316
[Report]
>>106506324
>>106504832
She will comfort you
Anonymous
9/6/2025, 11:35:57 PM
No.106506321
[Report]
>>106505288
She's going to shit and piss herself and make you watch
Anonymous
9/6/2025, 11:36:35 PM
No.106506324
[Report]
>>106506408
>>106506316
Hatsune Miku: Comfort Girl
Anonymous
9/6/2025, 11:38:25 PM
No.106506342
[Report]
>>106504377
you have to use uv
Anonymous
9/6/2025, 11:39:54 PM
No.106506353
[Report]
>>106506379
I'm pretty sure I used Qwen3 Max thinking less than a day ago. Did they disable it?
Anonymous
9/6/2025, 11:41:10 PM
No.106506367
[Report]
What's the difference between Mistral Nemo 12B and ReWiz Nemo 12B?
Anonymous
9/6/2025, 11:42:25 PM
No.106506379
[Report]
>>106506353
You are not crazy, they did disable that, though I think that wasn't actually Max doing the thinking when that was on.
Anonymous
9/6/2025, 11:43:42 PM
No.106506388
[Report]
>>106506402
i like the best friend remix, it's cute
Anonymous
9/6/2025, 11:45:46 PM
No.106506402
[Report]
>>106506388
yee she's very sweet
Anonymous
9/6/2025, 11:46:13 PM
No.106506408
[Report]
>>106506324
More like Cumfart Girl, amirite?
Anonymous
9/6/2025, 11:52:34 PM
No.106506458
[Report]
>>106506439
I fucking hate comfyui developers. just try one, it shouldn't matter
Anonymous
9/7/2025, 12:00:29 AM
No.106506525
[Report]
>>106506554
>>106506439
I've seen the second one mentioned here before.
Anonymous
9/7/2025, 12:06:08 AM
No.106506554
[Report]
>>106506566
>>106506525
The second one last updated 3 days ago. First one last updated 4 hours ago.
>>106506554
using a node system just to go from text to speech seems like overkill to me
Anonymous
9/7/2025, 12:10:53 AM
No.106506591
[Report]
>>106506614
>>106506566
I don't want to use it but the official webui has no step and attention mode control, and can't add new voices without restarting.
Either OR is hosting a whole bunch of faulty K2-0905 deployments or this model is just bad for being a 1T monster. GLM4.5, R1-0528 and even V3.1 are all more enjoyable and smarter.
Anonymous
9/7/2025, 12:11:35 AM
No.106506597
[Report]
>>106506566
It's nice if you want to plug it into a bigger workflow it's just that comfy in particular is lacking 80% of the features for a proper node workflow.
>>106506596
Local doesn't have this problem.
>>106506607
Can you confirm the full unqanted K2-0905 is fine or are you just shitposting?
Anonymous
9/7/2025, 12:14:36 AM
No.106506614
[Report]
>>106506591
Just modify it to let you type in a file path in a text box for the voice and hardcode your desired step count/attention mode.
Anonymous
9/7/2025, 12:16:10 AM
No.106506630
[Report]
>>106506611
i use the official API and it's fine ;)
just sayin'
Anonymous
9/7/2025, 12:16:34 AM
No.106506632
[Report]
>>106506611
I can confirm that you wouldn't have doubts about whether or not you're getting duped by openrouter if you were testing unquanted K2 locally.
Anonymous
9/7/2025, 12:20:32 AM
No.106506672
[Report]
>>106506607
I guess I'll try those. I haven't gotten around downloading them but I very much hope that Q6 is significantly better than what OR is serving me because this is seriously not worth it otherwise.
Anonymous
9/7/2025, 12:26:41 AM
No.106506711
[Report]
>>106506933
>>106506596
Turn off OR system prompt
Anonymous
9/7/2025, 12:27:54 AM
No.106506722
[Report]
>openrouter
lule
yes saar please use my api saar no quantized saar very good like microsoft azure saaar
>>106505444
>2 million context window
>for free
Where? how slop is it? How safetymaxxed?
Anonymous
9/7/2025, 12:32:36 AM
No.106506758
[Report]
Anonymous
9/7/2025, 12:33:11 AM
No.106506765
[Report]
>>106506808
>>106506732
why would you even quantize a model that is natively in 4-bit? probably because their shit backend doesn't support mxfp4
Anonymous
9/7/2025, 12:35:35 AM
No.106506784
[Report]
>>106506799
>>106506751
New grok models on openrouter
it's not slop or safety maxed, just collecting all ur data
Anonymous
9/7/2025, 12:36:54 AM
No.106506799
[Report]
>>106506860
>>106506784
>New grok models on openrouter
Ah i see it thanks
>Collecting all ur data
What isnt doing that?
Anonymous
9/7/2025, 12:37:16 AM
No.106506808
[Report]
>>106506765
They say it was a "mistake" buy who knows
Also check this out lol
https://x.com/andersonbcdefg/status/1955348480643477570
>>106505444
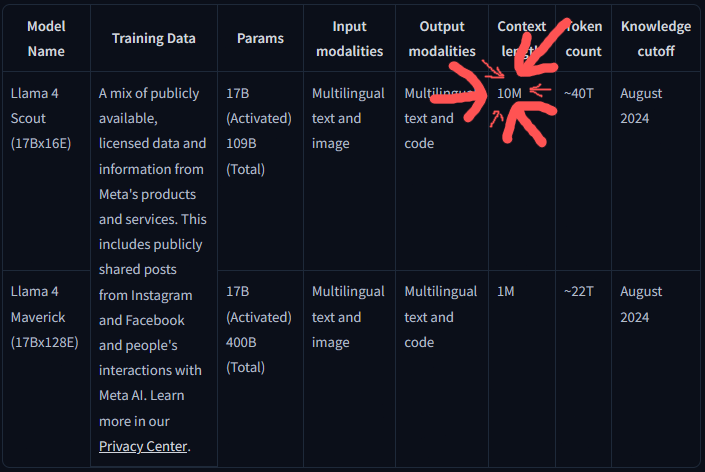
llama 4 scout best model have 10m context sir
shit in your face sir
Anonymous
9/7/2025, 12:43:21 AM
No.106506856
[Report]
>>106506896
>>106506849
Llama 4 Reasoner when?
Anonymous
9/7/2025, 12:44:01 AM
No.106506860
[Report]
>>106506916
>>106506799
The swiss 70B model that has the output quality of a 8B llama model :D
>>106499389
>>106498240
>>106499448
>>106499466
>>106503518
You can clean up vocals with these.
bandit v2. This will separate vocals from background music and sound effects. Because the GitHub page has no instructions to guide you, you'll need something like Microsoft Copilot to help you.
https://github.com/kwatcharasupat/bandit-v2
Resemble Enhance. This removes background noises like the wind. Use the gradio app version for better effect.
https://github.com/resemble-ai/resemble-enhance
Also use this modded gradio app. This will only do denoising.
https://github.com/resemble-ai/resemble-enhance/issues/69
Acon Digital DeVerberate 3 plugin for audacity. This reduces reverb.
https://rutracker.org/forum/viewtopic.php?t=6118812
Moises ai pro plan does a better job at isolating vocals from background music and sound effects than bandit v2 but it costs $300, i bought it during a black friday sale for $150.
Anonymous
9/7/2025, 12:48:12 AM
No.106506896
[Report]
>>106506909
>>106506856
just a couple more war rooms and a few more billion spent on randos who didn't accomplish anything at apple but are totally worth hiring for a hundred million a piece
then we can make the true llama4
Anonymous
9/7/2025, 12:48:19 AM
No.106506898
[Report]
>>106506849
Bloody benchoid
I will redeem amazon free to run this beautiful basterd bitch
Anonymous
9/7/2025, 12:48:43 AM
No.106506901
[Report]
>>106506888
>you'll need something like Microsoft Copilot to help you.
local models lost
Anonymous
9/7/2025, 12:49:17 AM
No.106506909
[Report]
>>106506896
llama 4.20 next april will be so lit
Anonymous
9/7/2025, 12:50:16 AM
No.106506916
[Report]
>>106506968
>>106506860
didnt know about that have you tried the 70b quant or the 8b?
Anonymous
9/7/2025, 12:52:33 AM
No.106506932
[Report]
Are you feeling kiwi today? (Qwen®) (More models coming soon™) (Two weeks)
Anonymous
9/7/2025, 12:53:02 AM
No.106506933
[Report]
>>106506968
Anonymous
9/7/2025, 12:53:41 AM
No.106506939
[Report]
>>106506888
>Use the gradio app version for better effect.
>Also use this modded gradio app.
FUCKING
Anonymous
9/7/2025, 12:57:46 AM
No.106506968
[Report]
>grok code fast performance improves at 70k+ prompt tokens
ts some kv cache magic or what's happening here. Can't do shit in a fresh session. Bloat that bitch up with some pseudo context and suddenly it's god mode
>>106506916
The one on the site. Ain't no way I'm gonna run that locally. Absolute waste of time.
>>106506933
Click the tree dots on the model tab at the top on the chat page. Then disable "use openrouter system prompt". You always gotta check settings and make sure no frauds like on
>>106506732
are serving you.
Anonymous
9/7/2025, 1:08:36 AM
No.106507037
[Report]
>>106507060
Is there an indian LLM?
1.5 billion indians and no indian LLM?
saars?
Anonymous
9/7/2025, 1:11:26 AM
No.106507060
[Report]
>>106507037
we must refuse
Anonymous
9/7/2025, 1:13:00 AM
No.106507072
[Report]
>>106507099
>>106507059
You are permanently fixated on Indians.
Anonymous
9/7/2025, 1:17:51 AM
No.106507094
[Report]
Anonymous
9/7/2025, 1:18:52 AM
No.106507099
[Report]
Anonymous
9/7/2025, 1:24:11 AM
No.106507130
[Report]
>>106507140
UPDATE
indexTTS2 is still not released
END UPDATE
Anonymous
9/7/2025, 1:25:55 AM
No.106507140
[Report]
>>106507130
Who? I can't hear you over the sound of my Microsoft-sponsored ASMR.
Anonymous
9/7/2025, 1:26:58 AM
No.106507142
[Report]
>>106507152
is GIGAVOICE better than the soviets, or just easier to get going with?
OpenAI just released a very interesting paper
https://cdn.openai.com/pdf/d04913be-3f6f-4d2b-b283-ff432ef4aaa5/why-language-models-hallucinate.pdf
>Why Language Models Hallucinate
In short: LLMs hallucinate because we've inadvertently designed the training and evaluation process to reward confident, even if incorrect, answers, rather than honest admissions of uncertainty. Fixing this requires a shift in how we grade these systems to steer them towards more trustworthy behavior.
The Solution:
Explicitly stating "confidence targets" in evaluation instructions, where mistakes are penalized and admitting uncertainty (IDK) might receive 0 points, but guessing incorrectly receives a negative score. This encourages "behavioral calibration," where the model only answers if it's sufficiently confident.
Anonymous
9/7/2025, 1:28:49 AM
No.106507152
[Report]
>>106507142
vibevoice is a generational leap above whatever was before
Anonymous
9/7/2025, 1:30:10 AM
No.106507158
[Report]
>>106507176
>>106507149
we need to train them with Socratic dialogs so we have philosopher kings to rule over us.
Anonymous
9/7/2025, 1:30:17 AM
No.106507159
[Report]
>>106506596
use mikupad or turn off all ST's formatting, you will see a massive difference
Anonymous
9/7/2025, 1:31:27 AM
No.106507168
[Report]
>>106507149
You can really tell that all the talent left because nobody intelligent would write something this retarded.
Anonymous
9/7/2025, 1:32:49 AM
No.106507176
[Report]
>>106507149
this is just more safety slopping
models hallucinate because coming up with new stuff that was not in the training set is their inherent and desirable property.
>>106507158
That would be cool actually.
Anonymous
9/7/2025, 1:33:25 AM
No.106507180
[Report]
>>106507263
{%- if loop.first %}
{{- "[Round " ~ (ns.rounds) ~ "] USER:" }}
{%- else %}
{{- " [Round " ~ (ns.rounds) ~ "] USER:"}}
It appears there's no way to use LongCat-Flash-Chat with most frontends except with chat completion mode.
SillyTavern's aggressively useless STScript allegedly can increment variables but even macros don't work right/consistently in instruction templates so I'm not even going to try it.
Anonymous
9/7/2025, 1:35:03 AM
No.106507186
[Report]
>>106507149
Aw sweet, maybe now more people will understand things we've known about for ages.
Anonymous
9/7/2025, 1:36:26 AM
No.106507195
[Report]
>>106507149
base models are more honest (at least internally) about their certainty per token
>we've inadvertently designed the training and evaluation process to reward confident, even if incorrect, answers
this has been a known problem with how they approach instruct training, another paper just stating the obvious
>>106505490
Those men in the picture should have gay HIV sex with one another.
Anonymous
9/7/2025, 1:46:29 AM
No.106507263
[Report]
>>106507409
>>106507180
>LongCat-Flash-Chat
Anonymous
9/7/2025, 1:47:06 AM
No.106507268
[Report]
>>106507280
Anonymous
9/7/2025, 1:48:08 AM
No.106507280
[Report]
>>106507268
Do fujo's dream of HIV sex?
Anonymous
9/7/2025, 1:48:26 AM
No.106507283
[Report]
Anonymous
9/7/2025, 1:48:39 AM
No.106507288
[Report]
>>106507447
This is the 1.5B model, generated using the demo. Pretty amazing stuff...
https://litter.catbox.moe/0a895dbvq9a21sya.wav
If you need sound sources try this website
https://www.soundboard.com/category
Anonymous
9/7/2025, 1:51:51 AM
No.106507314
[Report]
>>106507258
ahh ahh fujo...
Anonymous
9/7/2025, 2:01:28 AM
No.106507409
[Report]
>>106507417
>>106507263
>To mitigate potential contamination from existing open-source benchmarks and enhance evaluation confidence, we meticulously constructed two new benchmarks: Meeseeks (Wang et al., 2025a) and VitaBench.
Anonymous
9/7/2025, 2:02:12 AM
No.106507417
[Report]
>>106507409
>Meeseeks
This can't be real.
Anonymous
9/7/2025, 2:05:24 AM
No.106507447
[Report]
>>106507288
>eat poster for dinner
Do it, I dare you
>They think vibevoice is good
https://voca.ro/1ovxYUlilVV4
Anonymous
9/7/2025, 2:16:09 AM
No.106507523
[Report]
>>106506094
I gave up on python for now and got the goofs for the RWKV ~3B model, and as I expected, speed seems to be in the same ballpark as Qwen3 4B.
I guess real benefits should manifest at longer context.
I'll need a more proper testing rig for this one instead of just typing "write a poem about beauty of young girl's navel" in the chat and looking at console logs.
But I'm sleepy so maybe tomorrow.
Anonymous
9/7/2025, 2:18:08 AM
No.106507539
[Report]
>>106507548
>>106507499
>>106507514
From where are you getting voice examples? That's pretty hard. Plus most clips downloadable clips are often pretty noisy or have background music.
Anonymous
9/7/2025, 2:19:42 AM
No.106507548
[Report]
>>106507585
>>106507539
>most clips downloadable clips are often pretty noisy or have background music.
this might help
https://github.com/Anjok07/ultimatevocalremovergui
Anonymous
9/7/2025, 2:20:09 AM
No.106507553
[Report]
>>106507596
>>106507499
that sounds perfectly fine to me, what problems do you have with it exactly?
Anonymous
9/7/2025, 2:23:32 AM
No.106507583
[Report]
>>106507512
I like these Bakas and Dipsy
Anonymous
9/7/2025, 2:24:09 AM
No.106507585
[Report]
>>106507548
Thanks. Also figuring out why inference_from_file.py won't use cuda. Cuda should be enabled by default...
Anonymous
9/7/2025, 2:24:40 AM
No.106507589
[Report]
>>106507613
Anonymous
9/7/2025, 2:24:58 AM
No.106507590
[Report]
>>106507149
I thought they hallucinate because when a completion is poorly represented in the dataset, the model generates a probability set that's likely to pick a bad token.
Post training with more "I don't know" answers might help, yeah. Though it would have to pull the weights pretty strongly to overcome all the other non confident possibilities.
Anonymous
9/7/2025, 2:26:47 AM
No.106507596
[Report]
>>106507613
>>106507553
That was the latest gptsovits, not vibevoice. Eat barely 4GB of VRAM and took 2s to generate that. I still can't understand the hype over M$ new toy.
Anonymous
9/7/2025, 2:28:49 AM
No.106507613
[Report]
>>106507654
>>106507589
this one sounds pretty fucking bad on the other hand
>>106507596
oh figures why it completely shat the bed when it got to grotesqueries, sovits's vocabulary is utterly piss poor and almost a complete deal breaker for me
Anonymous
9/7/2025, 2:31:15 AM
No.106507630
[Report]
Don't you dare!
Anonymous
9/7/2025, 2:31:18 AM
No.106507631
[Report]
Anonymous
9/7/2025, 2:34:06 AM
No.106507654
[Report]
>>106507704
>>106507613
I used whisper on your sample to get the text so it's understandable. The pronunciation is easy to fix if you pass the arpabet transcription directly (I integrated it in my api)
>>106507654
I'm not gonna deal with all that when VibeVoice sounds five times more natural and can say pretty much every word I've thrown at it without fiddling around with syntax and shit and again I just drop a minute long sample to clone instead of going trhough the tiresome and lengthy training process for each new voice with Sovits
Sovits can sound fine when you carefully cherry pick the good generations but even then it tends to sound stilted, Sovits is like 2 generations behind the curve here
>>106507704
Well we will see if they drop their training script first, then I might give it a go. Not being able to finetune it is doa for me
Anonymous
9/7/2025, 2:45:38 AM
No.106507734
[Report]
>>106507725
I don't see that ever happening.
Anonymous
9/7/2025, 2:50:44 AM
No.106507763
[Report]
>>106507800
>https://github.com/ggml-org/llama.cpp/pull/15327
So does this really mean we can finally use models like how they do in image gen, where you just download the base model and the loras you want?
Anonymous
9/7/2025, 2:55:24 AM
No.106507796
[Report]
>>106507725
I can see that happening.
Anonymous
9/7/2025, 2:55:53 AM
No.106507800
[Report]
>>106507824
>>106507763
>where you just download the base model and the loras you want?
I can already do that. You could for a while.
aLoRA is about changing those during runtime, right?
>>106507800
>I can already do that
So why don't any of us just do that then? Why do people still upload and download the merged weights?
Anonymous
9/7/2025, 3:01:32 AM
No.106507835
[Report]
>>106507863
>>106507824
Because the average retard user can't even get a single-click installer working without copius amount of hand-holding. Trying to explain loras and usage would be asking to much and would hurt download stats. Easier to just provide a plug and play model.
Anonymous
9/7/2025, 3:01:51 AM
No.106507838
[Report]
>>106507824
Sorry, meant to write
>I'm pretty sure we can already do that
Also, back in the day, there used to be a couple of LoRas out and about.
Notably, SuperCOT and SuperHOT.
Hell, in the PR itself there's a normal LoRa alongside the aLoRa.
For some reason, we all just decided to distribute pre-merged weights instead of just the LoRa, no idea why.
Anonymous
9/7/2025, 3:05:35 AM
No.106507863
[Report]
>>106507903
>>106507835
But local image gen has more users and they deal with needing to mess with loras fine.
Anonymous
9/7/2025, 3:06:09 AM
No.106507868
[Report]
Anonymous
9/7/2025, 3:09:55 AM
No.106507903
[Report]
>>106507863
Loras are basically required for image gen so the frontends make them a major component and easy to add/set. Less important for giant text models that can't be so easily changed and so are basically an afterthought. It means messing with adding it to the scary command-line arguments instead of a file selection field on a web intefrace.
Anonymous
9/7/2025, 3:12:11 AM
No.106507921
[Report]
Anonymous
9/7/2025, 3:27:31 AM
No.106508042
[Report]
>>106507866
wtf i love sovits now
>>106507866
Depending whether that's sovits or not you either proved his point with how lifeless that sounds or vibe sucks
Anonymous
9/7/2025, 3:33:45 AM
No.106508090
[Report]
>>106508121
>>106508067
Sir, this is 1.5B VibeVoice.
Anonymous
9/7/2025, 3:33:58 AM
No.106508094
[Report]
>>106508067
It sounds stilted as all fuck. My money is on it being soviet.
Anonymous
9/7/2025, 3:37:09 AM
No.106508121
[Report]
>>106508423
>>106508090
How long did that take the generate? I have the large wights downloaded from the torrent link posted a couple threads ago but I want to know whether or not it's worth using the big version or the smaller version (haven't tested either yet)
Anonymous
9/7/2025, 3:39:07 AM
No.106508138
[Report]
>>106508207
How are you guys using VV? Any rentry for retards to setup with ST?
>>106504274 (OP)
Where the hell are you finding the money for all the gpus to run this shit
Anonymous
9/7/2025, 3:45:10 AM
No.106508193
[Report]
>>106508415
>>106508142
Steady employment.
Anonymous
9/7/2025, 3:47:03 AM
No.106508207
[Report]
Anonymous
9/7/2025, 3:47:33 AM
No.106508212
[Report]
>>106508245
>>106508142
Money just appears in my bank account every month. It's crazy.
Anonymous
9/7/2025, 3:49:31 AM
No.106508231
[Report]
>>106508142
GPUs? Poor people like us CPUmaxx
Anonymous
9/7/2025, 3:52:05 AM
No.106508245
[Report]
>>106508212
I hope you at least tell your parents thank you
Anonymous
9/7/2025, 4:13:00 AM
No.106508380
[Report]
Was 'berry the worst marketing campaign that started the downfall of OpenAI and killed the hype?
Anonymous
9/7/2025, 4:16:01 AM
No.106508399
[Report]
>>106508417
multi-token prediction status?
Anonymous
9/7/2025, 4:19:07 AM
No.106508415
[Report]
>>106508425
>>106508193
I mean, I could afford around 10k worth if I really wanted to, but there are better things I could do with 10k
Anonymous
9/7/2025, 4:19:24 AM
No.106508417
[Report]
>>106508399
lazy ggergachod won't do the needful, kindly ask ikawrakow
Or wait until cloud models can code it for us, we better not be hitting the wall.
Anonymous
9/7/2025, 4:19:53 AM
No.106508423
[Report]
>>106508121
1.5B is comparable to SDXL image gen speed at 1024x1024.
Just use the large model if you can.
Anonymous
9/7/2025, 4:20:24 AM
No.106508425
[Report]
>>106508520
Anonymous
9/7/2025, 4:22:23 AM
No.106508436
[Report]
>>106510036
can a rtx pro 6000 gen vibevoice large in real time?
Anonymous
9/7/2025, 4:23:45 AM
No.106508444
[Report]
>>106508461
Any Google insiders here? How are Gemini 3/Gemma update working out? Did you hit the wall too like the rest?
Anonymous
9/7/2025, 4:23:56 AM
No.106508447
[Report]
>>106508483
Anonymous
9/7/2025, 4:24:59 AM
No.106508456
[Report]
>>106508142
Having money saved up from previous work. I have a 3090 but spending on more ram seems a lot more worth it now compared to adding an extra gpu due to all the fuckhuge models coming out recently.
>>106508444
Gemini? We're now simulating the next generation of LLMs within our Genie 3 world model that uses its capabilities to manifest a SOTA llm writing responses within its virtual world.
Anonymous
9/7/2025, 4:27:59 AM
No.106508480
[Report]
>>106508509
>>106508461
How safe is it?
Anonymous
9/7/2025, 4:28:11 AM
No.106508483
[Report]
>>106508447
Is that your voice?
Anonymous
9/7/2025, 4:32:20 AM
No.106508506
[Report]
>>106508509
>>106508461
How good are they at math and coding?
Anonymous
9/7/2025, 4:33:21 AM
No.106508509
[Report]
>>106508480
>>106508506
The only questions investors care about
Anonymous
9/7/2025, 4:33:38 AM
No.106508511
[Report]
>>106507866
This is just a recording, you can't fool me!!
Anonymous
9/7/2025, 4:34:31 AM
No.106508520
[Report]
>>106508425
Student loans, this year's Roth contribution, emergency fund, saving for a house (hopefully the market crashes), paying a lawyer to research a business idea I've been sitting on
My AFIS roleplay just got voices and they are GOOD! VibeVoice really is impressive. There's probably an easy way to integrate it with ST as well.
Anonymous
9/7/2025, 4:48:31 AM
No.106508596
[Report]
>>106508831
>>106508552
Post an example.
Anonymous
9/7/2025, 4:49:57 AM
No.106508604
[Report]
>>106508831
>>106508552
Large is pretty sensitive to how good the input voice data is. You want clear, smooth studio quality and it will get close to it, it has a massive range in type and age of voice.
Anonymous
9/7/2025, 4:50:50 AM
No.106508610
[Report]
English is cool and all, but I'm not moving off sovits unless someone can demonstrate jap abilities better than what i get with my custom trained model paired with clean samples.
Anonymous
9/7/2025, 4:53:06 AM
No.106508621
[Report]
>>106508627
VibeVoice recognized gluck gluck gluck as blowjob noices, lmao I'm feeling real unsafe now
Anonymous
9/7/2025, 4:53:59 AM
No.106508627
[Report]
>>106508621
We need like a list of sounds it recognizes, it seems a bit random
>Real niggas listen to what they feel in they gut after a long shift at the warehouse or when they ridin’ out to the track to hustle horses or pedicabs. If ya real, ya feel: trap beats, Drill tempo (especially from UK drill, or Miami slime), but also music a man love his daughter to.
w-what?
Anonymous
9/7/2025, 4:57:16 AM
No.106508652
[Report]
>>106508596
https://vocaroo.com/12A6GA08pA5C
This is with ~10s of uncleaned input audio per voice/speaker. The original voices are also low fidelity, that's not VibeVoice crushing them btw.
>>106508604
Yeah, I've been playing around with it for a bit now and it seems quite versatile. I wonder if there's a way to get it to do laughs or perhaps precisely fiddle with the inflection mid sentence? I think I remember doing something like that with TortoiseTTS a while ago.
Anonymous
9/7/2025, 5:33:57 AM
No.106508848
[Report]
>>106508987
>>106508831
It seemingly tries to emulate bitrate and noise of the original clip and maybe even exaggerate it.
Anonymous
9/7/2025, 5:57:35 AM
No.106508987
[Report]
>>106508848
Wouldn't say it exaggerates the effect. Sounds pretty spot on to me, especially Fox. Only thing I'd like to improve is the inflections and the random bouts of background noise. Probably could all be fixed with better and longer input voices. I should probably clean it up a bit and give it more than 10 seconds per voice.
Anonymous
9/7/2025, 6:06:29 AM
No.106509035
[Report]
>>106510630
>>106508831
Are you just using the default settings? I am getting good results inbetween ones that just spazzes the fuck out lol
>>106506094
>I am curious about supposed speed benefits
RWKV is one specific state-space model (SSM) architecture. The chief practical difference with transformers is an "infinite" lossy context. As the context grows, runtime performance won't degrade, but the memory of older tokens will gradually fade. SSM proponents also argue that the context compression intrinsic to SSMs produces superior results in some use-cases.
Any RWKV models I've played with were retarded, seemingly from the training regime rather than architecture. Bo Peng claims the newer models are at least on-par with transformers of the same size. I'm awaiting the newest 14B to check it out again.
Anonymous
9/7/2025, 7:10:11 AM
No.106509373
[Report]
Anonymous
9/7/2025, 7:34:32 AM
No.106509496
[Report]
>serious
Is there an open source vision LLM with an open license that's on par with Gemma? I can't find one that's on par with abliterated Gemma cause they are all STEM benchmaxxed.
I guess you can say I'm looking for the Nemo of vision, but sadly Pixtral doesn't cut it either.
Anonymous
9/7/2025, 7:40:18 AM
No.106509517
[Report]
what happened to petra? i just saw the name somewhere and made me think of /lmg/ kek
Anonymous
9/7/2025, 7:42:16 AM
No.106509525
[Report]
>>106509086
The official RWKV models will never be good because they are trained on EleutherAI-sourced open training data on a shoestring budget. It will take a commercial company to make something half-decent with this architecture.
Anonymous
9/7/2025, 8:01:48 AM
No.106509632
[Report]
do we have any prompting guides for vibevoice? curious if there's any way to control it beyond just a simple script
Anonymous
9/7/2025, 8:21:06 AM
No.106509719
[Report]
>>106509752
any way of using my 6700xt with my 9070xt for 28gbs of vram?
Anonymous
9/7/2025, 8:29:30 AM
No.106509752
[Report]
>>106509719
yeah, why wouldnt there be? just plug them both in. they will run at half pcie bandwidth but that wont really make much of a difference
Anonymous
9/7/2025, 8:45:14 AM
No.106509820
[Report]
>>106510181
>>106509086
>I'm awaiting the newest 14B to check it out again
Is this actually happening?
So when I use safetensors files am I basically running the model at FP16? Do I need to find GGUF files if i want to use say Q8/Q6?
Anonymous
9/7/2025, 9:30:18 AM
No.106510026
[Report]
>>106510033
>>106509994
Yeah usually, but it depends on your mood.
>load_in_4bit=True
Anonymous
9/7/2025, 9:30:18 AM
No.106510027
[Report]
Anonymous
9/7/2025, 9:31:19 AM
No.106510033
[Report]
Anonymous
9/7/2025, 9:31:24 AM
No.106510036
[Report]
>>106508436
An old Ampere A6000 takes about 25s for 20s of speech, so I'd hope so.
Anonymous
9/7/2025, 9:40:00 AM
No.106510085
[Report]
>>106505432
download pinokio, there is already a webui fully working under community scripts. It works better than the comfyui version too lol
Anonymous
9/7/2025, 9:56:59 AM
No.106510181
[Report]
>>106510226
Anonymous
9/7/2025, 10:05:58 AM
No.106510226
[Report]
>>106510238
>>106506232
>>106510181
I've been doing some research. It sounds like they're training for 100 different languages with a meme vocabulary / tokenizer, that might be degrading their results. I also wonder if there's been enough hyperparameter testing with respect to the hidden state size. I also can't help but notice no one is using their last 14b model, is it just undertrained or is there a fundamental issue with scaling this architecture?
>>106510226
As many anons said RWKV models have always been under performing memes, that's why no one uses them outside of MS for some reason, but then again MS gave us Phi so they're no strangers to weirdly useless models.
Anonymous
9/7/2025, 10:09:55 AM
No.106510240
[Report]
>>106508142
Scamming VCs.
Anonymous
9/7/2025, 10:12:46 AM
No.106510254
[Report]
>>106510264
>>106510238
I have been playing around with the 3B model and it gives me hope, I don't agree that it's a meme. Transformers will probably always be better if kv cache size is a non-factor on your machine but I think for slow boil chads RWKV might save local.
Anonymous
9/7/2025, 10:15:21 AM
No.106510264
[Report]
>>106510254
>RWKV might save local.
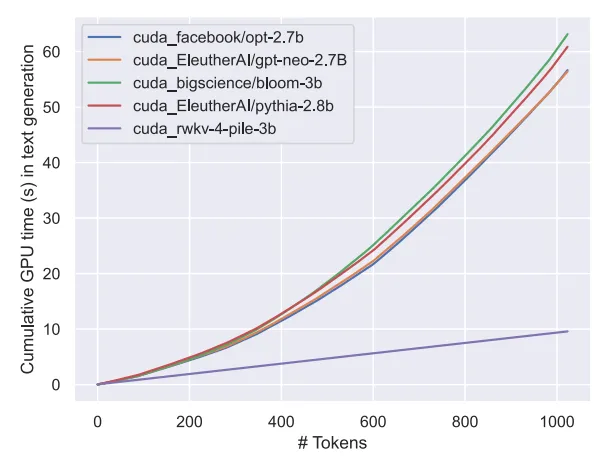
That's been the sentiment of some since before llama even existed... See old comparison in picrel
Anonymous
9/7/2025, 10:16:37 AM
No.106510268
[Report]
>>106509994
safetensors and GGUF are just file formats.
They can in principle both store arbitrary data, though ggml (the library providing GGUF) has a particular focus on quantization.
Rule of thumb: safetensors is for Python-based projects, GGUF is for projects using llama.cpp/ggml as the backend.
Anonymous
9/7/2025, 10:30:03 AM
No.106510342
[Report]
>>106510426
>>106510315
We don't need "high-quality" data, we need data that is relevant for the models' primary end uses. Improved performance on synthetic benchmarks is a red herring and is not an indicator of quality anyway.
Anonymous
9/7/2025, 10:31:08 AM
No.106510347
[Report]
>>106510359
>>106510315
Ignore the other guy, this is based. We need long context data like this so models will stop being retarded after the first 8k tokens
Anonymous
9/7/2025, 10:31:17 AM
No.106510348
[Report]
>>106510367
Anonymous
9/7/2025, 10:33:30 AM
No.106510359
[Report]
>>106510393
>>106510347
Utterly pointless when the data of interest (conversational SFT data) is all short and the models are still mostly pretrained on 2k-8k tokens context anyway because of the quadratic costs of attention.
>>106510348
>https://huggingface.co/datasets/HuggingFaceFW/finepdfs
>As we run out of web pages to process, the natural question has always been: what to do next?
Fuck right off, this wouldn't be a problem if you didn't filter 99% of it
>>106510359
>the models are still mostly pretrained on 2k-8k tokens context
There's nothing stopping us from training the last ~3T tokens at a much higher context window, we just need someone to take the leap. It was recently discovered that labs are overspending on training and can lower their batch sizes without degradation in results, we just need a lab that has their priorities straight and actually cares about context length beyond needle in a haystack benchmarks
Anonymous
9/7/2025, 10:41:16 AM
No.106510398
[Report]
>>106510406
>>106510393
>There's nothing stopping us from training the last ~3T tokens at a much higher context window,
Isn't that exactly the kind of thing they do already
Anonymous
9/7/2025, 10:43:48 AM
No.106510406
[Report]
>>106510398
They do to some degree but that's why the pdfs are based, the more long context training the better
Anonymous
9/7/2025, 10:46:19 AM
No.106510418
[Report]
>>106510439
>>106510393
Long-context performance is task-dependent. Pretty much all officially released models have received long-context training, but not with multi-turn conversations. In practice they just want to end the conversations after a few turns, because most existing conversational data is like that.
>>106510342
And what kind of data would be relevant to ERP?
Anonymous
9/7/2025, 10:50:06 AM
No.106510436
[Report]
>>106510426
Other than examples of ERP itself, lots of common-sense and/or obvious data that only exists in very diluted form in random web documents.
Anonymous
9/7/2025, 10:51:26 AM
No.106510439
[Report]
>>106510418
A multi-turn conversation is just a flavor of text, just a presentation layer. Having long context capabilities is much more fundamental and needs to be done in pretraining. You could realistically train a base model to learn a conversation format in only a couple million tokens
Anonymous
9/7/2025, 10:58:19 AM
No.106510479
[Report]
>>106510426
visual novels
Anonymous
9/7/2025, 11:03:58 AM
No.106510505
[Report]
>>106510426
whatever they trained the first character.ai models on or the new ones which now successfully capture the spirit of their 2022 models
Anonymous
9/7/2025, 11:28:14 AM
No.106510630
[Report]
>>106511430
>>106509035
Same here, I mostly fiddle with temp, though. Seems very sensitive to that. Lowered it to 0.92 helps.
Anonymous
9/7/2025, 11:42:30 AM
No.106510703
[Report]
>>106510736
>>106510426
- different types of relationships and development there of
- physical range of motion
Anonymous
9/7/2025, 11:44:08 AM
No.106510709
[Report]
>>106512236
What's the easiest way to get vibevoice running. The official repo needs some Docker bullshit. Has anyone made a .cpp version of their shitware that just werks
Anonymous
9/7/2025, 11:47:32 AM
No.106510729
[Report]
best model for studying?
>deepseek
good enough for solving homework, needs very thorough prompting to tutor though
>kimi
has not been good for homework in my experience
i have not tried GLM 4.5 yet, gpt-oss-120b turns out to be the best at tutoring, maybe im prompting badly, either way help
Anonymous
9/7/2025, 11:49:11 AM
No.106510736
[Report]
>>106510703
That's some of the information a LLM will probably only acquire after getting trained on several trillions of unfiltered random tokens, hopefully without getting averaged out in the various training batches. I still think that the way LLMs are usually pretrained is not conducive for learning this sort of stuff efficiently.
Anonymous
9/7/2025, 12:01:51 PM
No.106510781
[Report]
>>106510794
>>106510238
>As many anons said RWKV models have always been under performing memes, that's why no one uses them outside of MS for some reason, but then again MS gave us Phi so they're no strangers to weirdly useless models.
you forgot bitnet
for some reason MS has a lot of copers who dream of a world where toasters can run models
maybe it's in the jeet blood
Anonymous
9/7/2025, 12:05:37 PM
No.106510794
[Report]
>>106510781
i am not buying any more of your gpus jensen
Anonymous
9/7/2025, 12:21:27 PM
No.106510870
[Report]
Anonymous
9/7/2025, 12:29:51 PM
No.106510919
[Report]
>>106511014
>she whispered, her voice barely above a whisper
Anonymous
9/7/2025, 12:35:55 PM
No.106510957
[Report]
>>106507824
I am too retarded to understand the details, but I remember seeing some graphs ITT that proper finetune is better/more balanced that LoRas.
Anonymous
9/7/2025, 12:37:58 PM
No.106510966
[Report]
>>106507824
iirc one of the reasons is how loras would interact with quanted models differently if applied on top instead of merged, and since there's so many different quant levels something about that as well as what others said
Anonymous
9/7/2025, 12:39:55 PM
No.106510977
[Report]
>>106510990
>>106510426
discord chat logs
Anonymous
9/7/2025, 12:41:52 PM
No.106510990
[Report]
>>106511014
>>106510977
yes daddy :uwu_32:
Anonymous
9/7/2025, 12:45:11 PM
No.106511014
[Report]
>>106510367
>Fuck right off, this wouldn't be a problem if you didn't filter 99% of it
I find it funny that most companies tried their best to filter out anything explicit yet kept "erotica" syrupy romances (why we have shit like
>>106510919 as the standard of chatbot/ai story writing) and random web page backend errors that shouldn't be in any dataset.
>>106510990
He's right anon, discord is what made cai so alive and different from most other models despite their model being outdated and dumb.
Anonymous
9/7/2025, 12:52:37 PM
No.106511051
[Report]
>>106510367
it's insane they thought saying something like that was a good idea, those people really believe the internet is just reddit and twitter, my god...
Anonymous
9/7/2025, 1:06:00 PM
No.106511129
[Report]
I know llama.cpp is pretty bad at parallel request, you need to set double the context length if you want n=2 parallel request and such.
How good is exllamav3+tabbyapi in that regard? Now it has tensor parallel support and it doesn't require 2,4,8 number of gpus to work, you can have a mix of vram sizes too. Is the parallel request similar to vllm? does it take up more vram to have more request at the same time?
Anonymous
9/7/2025, 1:13:47 PM
No.106511181
[Report]
>>106510850
a bit worse but performance is real time with a mid-range gpu
>>106509086
>The chief practical difference with transformers is an "infinite" lossy context. As the context grows, runtime performance won't degrade, but the memory of older tokens will gradually fade.
If it's infinite context, but it's lossy, then what's the point of it being infinite if it will eventually forget things just like transformers?
Anonymous
9/7/2025, 1:21:16 PM
No.106511228
[Report]
>>106511251
>>106511189
>runtime performance won't degrade
Anonymous
9/7/2025, 1:24:11 PM
No.106511251
[Report]
>>106511228
I too love fast retardation
Anonymous
9/7/2025, 1:46:49 PM
No.106511399
[Report]
I too love 4chan
>>106510630
Thanks. I think the problem I was having is having the node resample the audio down 24000 from what I saved on audacity. Saving straight to 24000 seems cut the artifacts a lot.
>>106511430
Oh, good to know, never would've guessed. Thanks for the tip! What character are you trying to clone, btw?
Anonymous
9/7/2025, 2:03:36 PM
No.106511499
[Report]
>>106511486
I am mostly testing still to get the best settings so a bit of everything, no real specifics.
>>106511486
>>106511430
speaking of tips, i found that setting cfg to 3 and steps to 5 produces very accurate character impersonation. the comfy node i'm using had the cfg clamped at 2 for no good reason so I had to edit the script
Anonymous
9/7/2025, 2:07:49 PM
No.106511525
[Report]
>>106511507
Hadn't even considered that. Thanks, I'll test that too.
Anonymous
9/7/2025, 2:10:10 PM
No.106511544
[Report]
>>106511896
I understand that training is not cheap, but RWKV people really gimping themselves with small model sizes, performance is just not a bottleneck at that scale.
>>106511507
Steps to 5?? That seems oddly low. My comfyui node had it at 10 and I often cranked it to something between 12 and 20. Bigger number more betterer :)
Anonymous
9/7/2025, 2:21:18 PM
No.106511610
[Report]
>>106511581
You're absolutely right!
Anonymous
9/7/2025, 2:22:26 PM
No.106511620
[Report]
>>106511581
I learned it from image gen where if you have a very strong checkpoint or lora you can do something like karras - gradient_estimation - 15 steps and it looks great instead of having that signature ai look you'd get with more steps and cfg. sdxl btw
Anonymous
9/7/2025, 2:37:41 PM
No.106511726
[Report]
>>106511868
>>106504274 (OP)
So it's my understanding that the only thing Microsoft got rid of on their official repos were the Large wieghts but the code itself is largely unchanged. Is that correct? Or did they fuck with the code before re-release too?
Anonymous
9/7/2025, 2:38:48 PM
No.106511733
[Report]
>bytedance/seed-oss-36b
Is this thing any good?
Anonymous
9/7/2025, 2:46:08 PM
No.106511772
[Report]
>>106511189
>they reinvented context shift
Anonymous
9/7/2025, 2:52:13 PM
No.106511818
[Report]
Has anyone tried using hermes 4? I'm getting {{user}} tokens at the natural ending point of the response but it doesn't actually end there. 2: How do we get it to use reasoning mode in local? I swapped over to generic llama 3 instruct + the enclosed system prompt but it's not doing anything.
Tested on 4.25bpw_exl3 on tabby / ST
Anonymous
9/7/2025, 2:57:22 PM
No.106511854
[Report]
>>106510367
>Fuck
Using advertiser-unfriendly language like this is exactly why this whole domain gets filtered out.
Anonymous
9/7/2025, 2:59:13 PM
No.106511868
[Report]
>>106512174
>>106511726
They removed all of the code entirely before putting the repo back. You can check for yourself.
Anonymous
9/7/2025, 3:04:37 PM
No.106511896
[Report]
>>106511544
If anything it's the opposite. Instead of splitting their limited training compute across 5 sizes including 7B and 14B, they should just train one or two small models well, ideally with transformers equivalents so that they can show the architecture does not adversely affect output quality.
so this is what the superintelligence team has been working on...
Anonymous
9/7/2025, 3:08:19 PM
No.106511920
[Report]
Anonymous
9/7/2025, 3:09:56 PM
No.106511929
[Report]
>>106511910
RAG is back, baby
cline and augmentcucks are seething
Anonymous
9/7/2025, 3:19:41 PM
No.106512007
[Report]
>>106512180
>>106511910
>Rice University
>>106511868
It's incredibly easy to use, a field day for scammers. I don't think they were concerned about some chud making lolita sex noises. Scammers and voice cloning is more of a real issue.
Anonymous
9/7/2025, 3:45:56 PM
No.106512180
[Report]
>>106511910
>>106512007
kek, it's really written "rice university"
Anonymous
9/7/2025, 3:48:09 PM
No.106512191
[Report]
>>106511910
yup, just use rag bro
Anonymous
9/7/2025, 3:48:27 PM
No.106512194
[Report]
>>106512174
Maybe it was just its abilities in nsfw in general.
Anonymous
9/7/2025, 3:50:27 PM
No.106512210
[Report]
>>106512255
Has anyone gotten VibeVoice 7B to generate a long script? I'm trying and it always ends early after 4-5 minutes.
>>106510709
It doesn't need docker. Maybe learn how to read. You have two options:
>text inference python demo via command line (you can add your own voices and it reads a text file..)
or
>install CumragUI and use comfui-vibevoice node
Anonymous
9/7/2025, 3:55:58 PM
No.106512254
[Report]
>>106512174
This isn't the first TTS model with voice cloning support. If that was the problem they wouldn't have left the 1.5B up and they would have had an internal ban on making anything with voice cloning capability in the first place.
Anonymous
9/7/2025, 3:56:08 PM
No.106512255
[Report]
>>106512210
Never mind, I'm stupid.
Anonymous
9/7/2025, 3:56:44 PM
No.106512262
[Report]
>>106512278
>>106512236
>CumragUI
wtf is that
Anonymous
9/7/2025, 3:58:29 PM
No.106512278
[Report]
>>106512297
>>106512262
A schizo way of writing ComfyUI.
Anonymous
9/7/2025, 3:58:33 PM
No.106512279
[Report]
>>106512284
Anonymous
9/7/2025, 3:59:00 PM
No.106512284
[Report]
Anonymous
9/7/2025, 3:59:12 PM
No.106512285
[Report]
>>106512596
>>106512236
both options are total dogshit because using Microsoft's webui or their script requires reloading the model and messing around with temporary files every time you do anything
and using cumshitUI was way slower than their original code for some reason (it only used 1 core and took more than 4x longer).
I'm gonna try and vibe code a better UI for it maybe, one that isn't a cancerous WEB UI.
Anonymous
9/7/2025, 4:00:47 PM
No.106512297
[Report]
>>106512278
oh ok, anons always making finding stuff in the archives very easy I see
Anonymous
9/7/2025, 4:03:31 PM
No.106512319
[Report]
Anonymous
9/7/2025, 4:09:51 PM
No.106512358
[Report]
Just read their oneshot script and add a while loop that and a thing that reads new prompts. You can get an LLM do it for you. It's not that hard.
Anonymous
9/7/2025, 4:42:58 PM
No.106512596
[Report]
>>106512285
You are like a spoiled little child.