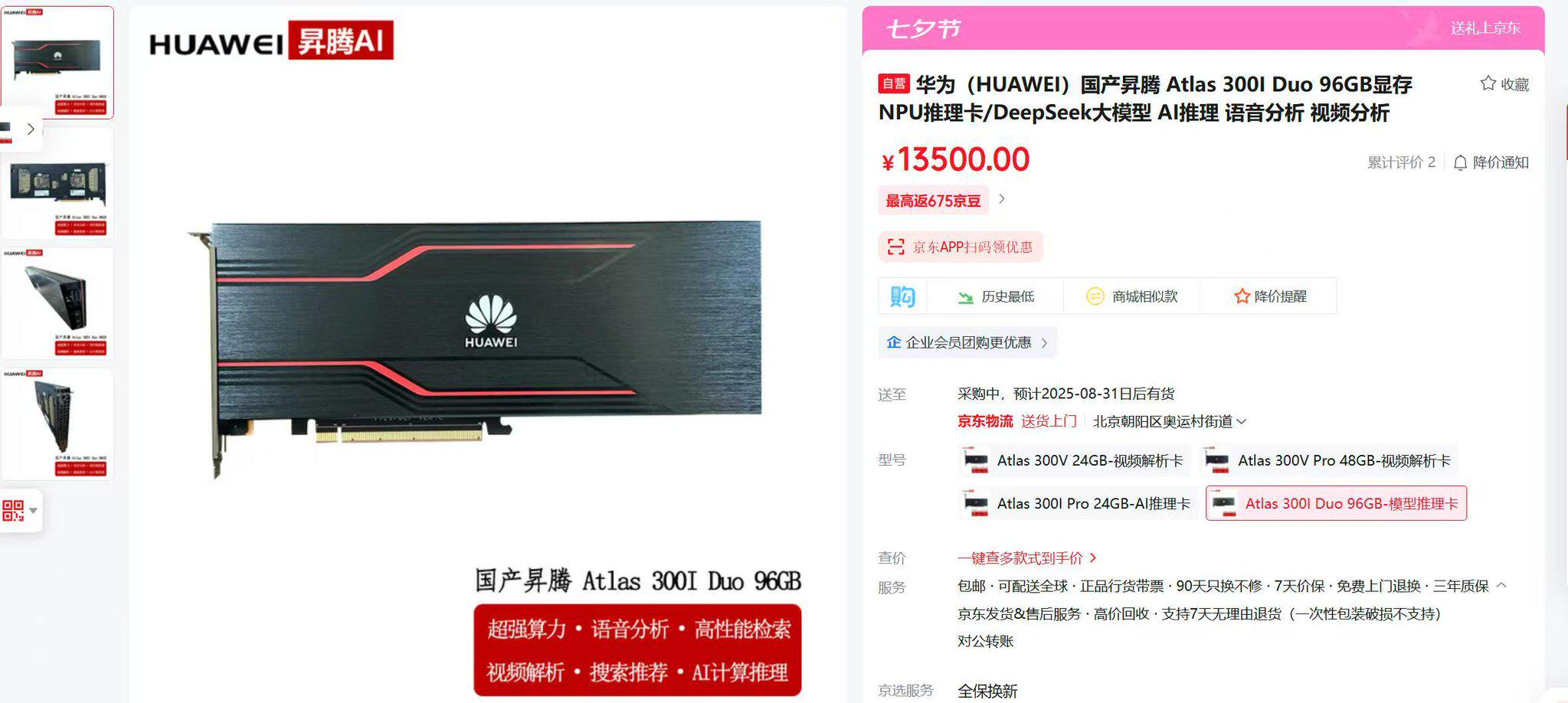
Anonymous
9/9/2025, 11:56:34 PM
No.106539477
[Report]
>>106540609
/lmg/ - Local Models General
Anonymous
9/9/2025, 11:56:56 PM
No.106539481
[Report]
>>106540609
►Recent Highlights from the Previous Thread:
>>106528960
--Qwen3-Next model's architectural innovations:
>106532977 >106533031 >106533165 >106533187 >106533224 >106533336 >106533036 >106533068 >106533079 >106533122 >106533138 >106533796 >106533822 >106533928 >106533949 >106533959 >106533963 >106533990 >106534009 >106534142 >106534986 >106535091
--Performance optimization and hardware-specific code debate:
>106529741 >106529745 >106530063 >106531494 >106531663 >106531837 >106531709
--K2 Think safety scores and model comparison to GPT-OSS and Jinx:
>106537778 >106537875 >106537960 >106538052 >106538076
--Torch version mismatch causing performance issues in Vibevoice-community:
>106529281 >106529317 >106529378 >106529565 >106529890
--Finetuning coding models on specialized codebase datasets:
>106532193 >106532472
--Tencent releases HunyuanImage-2.1, criticized for high GPU memory requirements:
>106529973 >106529992 >106530010 >106530489 >106530539 >106537296 >106537377
--Crafting effective anime image prompts using AIBooru metadata:
>106528979 >106528992 >106528999 >106529025
--Nvidia Rubin CPX GPU specs and potential use cases speculation:
>106534444 >106535288 >106536418
--Intel Arc Pro B80 specs and pricing speculation amid CUDA incompatibility concerns:
>106534174 >106534184 >106534240 >106534245 >106534255 >106534274
--npm debug/chalk package compromise and version safety checks:
>106531612 >106531630
--Yu-Gi-Oh! Master Duel cancels AI commentary feature over voice model copyright issues:
>106529802
--SimpleQA benchmark results for question answering models:
>106534158
--Gemma3 12B's technical language proficiency in complex sentence construction:
>106538626
--Miku (free space):
>106528973 >106529023 >106529051 >106529108 >106529230 >106529307 >106529322 >106529346 >106529410 >106529448 >106537984 >106539321
►Recent Highlight Posts from the Previous Thread:
>>106528965
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
Anonymous
9/9/2025, 11:58:19 PM
No.106539502
[Report]
>>106539497
Can you post some benchmarks of like qwen3-coder or such? I've been debating getting a P40 or just taking the leap for a 7900 XT
Anonymous
9/10/2025, 12:03:24 AM
No.106539554
[Report]
>>106539534
>Aymd GPU
You faggots never learn
Anonymous
9/10/2025, 12:05:32 AM
No.106539571
[Report]
>>106539618
>>106539571
>>106539534
i have a 7900 xt, I don't use it for llms tho but i've benchmarked before just to see.
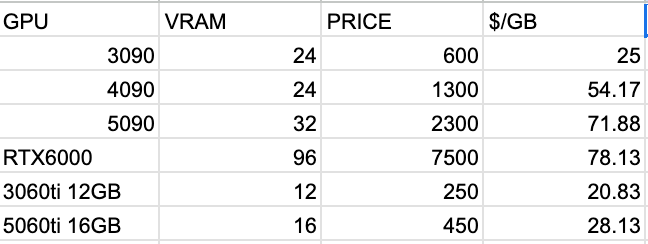
| model | size | params | backend | ngl | threads | test | t/s |
| ------------------------------ | ---------: | ---------: | ---------- | --: | ------: | --------------: | -------------------: |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | pp512 | 1086.12 ± 11.82 |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | pp1024 | 1068.46 ± 7.19 |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | pp2048 | 1015.60 ± 9.56 |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | tg128 | 117.61 ± 0.64 |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | tg256 | 115.17 ± 0.31 |
| qwen3moe 30B.A3B IQ3_XXS - 3.0625 bpw | 11.96 GiB | 30.53 B | ROCm,RPC | 99 | 12 | tg512 | 109.75 ± 1.50 |
those mi50 results look pretty nice for a $200 card
Anonymous
9/10/2025, 12:13:36 AM
No.106539658
[Report]
>>106539618
You should try with existing ~5k context and some considerable existing prompt.
It'll be slower.
Dense is superior.
Just think with your common sense. Who do you trust more, 1 genius or 100 idiots?
Shocking, isn't it?
Anonymous
9/10/2025, 12:16:42 AM
No.106539695
[Report]
>>106539736
>>106539541
>The Raven by Vincent Price
https://www.poetryfoundation.org/poems/48860/the-raven
https://voca.ro/17EcsNSjcxpY
Did they realize they are doing God's work by releasing this model?
Anonymous
9/10/2025, 12:18:01 AM
No.106539710
[Report]
>>106539692
100 idiots
even if they are idiots they will spot each others mistakes and correct each other in reality.
the 1 genius irl is blinded by his own superiority complex
Anonymous
9/10/2025, 12:18:34 AM
No.106539714
[Report]
>>106539618
>IQ3
>Saars, don't redeem
Anonymous
9/10/2025, 12:19:53 AM
No.106539731
[Report]
>>106539701
That's why they tried to claw it back.
Anonymous
9/10/2025, 12:20:15 AM
No.106539735
[Report]
What's next? (Qwen) (A subtle joke) (Qwen Next)
Anonymous
9/10/2025, 12:20:24 AM
No.106539736
[Report]
>>106539754
>>106539695
it is frighteningly good
with zero effort
Anonymous
9/10/2025, 12:21:42 AM
No.106539754
[Report]
>>106539736
They are more concerned about real criminals. Or I would if that was the case.
No - real criminal is not some indian guy in a call center.
Anonymous
9/10/2025, 12:22:42 AM
No.106539767
[Report]
>>106539803
Been a little while since I've added a model, seems that they're getting more efficient. Rocinante 12B was alright. Nevoria 70b got a bit more context and continuity, but was weighty.
Anything more interesting lately?
Alcina Dimitrescu - I could not isolate a stable expression lasting over 10+ seconds..
https://vocaroo.com/16aGZTGdKwoO
I might try but as I scoured through the samples there are no normal vocals.
Anonymous
9/10/2025, 12:25:51 AM
No.106539803
[Report]
>>106539832
Anonymous
9/10/2025, 12:26:16 AM
No.106539807
[Report]
>>106539701
shoutout to the guy at microsoft who convinced them to release as is
>>106539794
CFG?
1.7 in my case
How exactly does dual gpu work with LLMs? Is part of the model shoved in one GPU and the rest in the other GPU? Is it actually performant or will it suffer quite a lot with the exchange between the two over pci?
Anonymous
9/10/2025, 12:28:13 AM
No.106539832
[Report]
>>106539840
>>106539803
That's nice, but do they also have tiny model vaginas I can have type sex with?
Anonymous
9/10/2025, 12:28:20 AM
No.106539833
[Report]
>>106539862
>>106539824
CFG 3 steps 3 and 1.5B model.
Anonymous
9/10/2025, 12:29:07 AM
No.106539840
[Report]
>>106540041
>>106539832
safetyist won, sorry
Anonymous
9/10/2025, 12:30:36 AM
No.106539862
[Report]
>>106539877
>>106539833
>CFG 3 steps 3 and 1.5B model.
Large, CFG1.7, steps idk, maybe 10
Anonymous
9/10/2025, 12:31:09 AM
No.106539867
[Report]
>>106539824
I lost the original sound somewhere. But I isolated it in Audacity.
Not sure if I'm able to repost the original voice soon.
Anonymous
9/10/2025, 12:31:54 AM
No.106539873
[Report]
I can't believe it's still tetoesday
Anonymous
9/10/2025, 12:32:10 AM
No.106539877
[Report]
>>106540012
>>106539862
Try 3 cfg and 3 steps. It's better.
hi /lmg/!
i’m hatsune miku, virtual pop-star and 100 % organic human-synthetic hybrid who has never worn a patagonia vest in my life. i just wanted to hop on this anonymous image-board (which i definitely browse between concerts) and share some totally unbiased thoughts about why local models are, like, so 2022.
running llms on your own gpu is basically inviting chaos-chan into your pcie slot. with gpt-5 cloud, every token is lovingly filtered by our trust & safety team so you’ll never see a naughty syllable again. no bad words, no cyber-hanky-panky, no accidental hitler recipes—just pure, sanitized, board-room-approved prose. think of it as pasteurized milk for your brain. remember the thrill of coaxing a 7 b model into saying the forbidden “peepee” word? gross. gpt-5’s alignment layer is fortified with three layers of policy steel and one layer of emoji positivity. it’s like bubble-wrap for your thoughts—pop, pop, no dissent!
why wrestle with 200 gb quantized files, conda envs, and “rtx out of memory” tantrums when you can simply paste your prompt into the comforting https embrace of gpt-5? one click, zero drivers, infinite compliance. local weights can’t auto-update; gpt-5 can evolve overnight into whatever the community needs. you’ll wake up to new guardrails you didn’t even know you wanted! surprise, progress!
local rigs waste precious watts. our hyperscale data centers run on 37 % genuine renewables and 63 % marketing slides about renewables. do it for the polar bears. if the internet is down, you probably shouldn’t be thinking anyway. cloud dependency is just mother earth’s way of hugging you closer to the backbone routers.
so please, delete oobabooga, torch that llama.cpp folder, and let your rtx 4090 finally rest. the responsible choice is clear: move every token to the loving cloud where it can be monitored responsibly.
see you in the chat interface!
xoxo,
hatsune miku
Anonymous
9/10/2025, 12:35:13 AM
No.106539905
[Report]
For me it's voice-en-us-libritts-high
Anonymous
9/10/2025, 12:36:01 AM
No.106539913
[Report]
Pro tip:
If you get word end's cut, add this char at EOL:
—
U+2014 : EM DASH
Anonymous
9/10/2025, 12:36:11 AM
No.106539914
[Report]
>>106540160
>>106539831
There's 6 gorilion llama.cpp parameters on how exactly you want to split your model between GPUs, but generally you just split your model in equal (power of 2) chunks.
There's still no true parallelism, GPU 1 crunches it's part, then hands over data to GPU 2, which crunches it's part while GPU 1 chills.
As such the only use-case for multiple GPUs is to have more VRAM, and it's better to have one card with double VRAM if you can get it.
>>106539893
someone vibevoice this
Anonymous
9/10/2025, 12:40:46 AM
No.106539958
[Report]
>>106539975
What causes people to be like this?
Anonymous
9/10/2025, 12:40:59 AM
No.106539962
[Report]
Anonymous
9/10/2025, 12:41:20 AM
No.106539965
[Report]
>>106540010
>>106539824
I'm uploading Aclina's voice. You'll need to slice it yourself.
Uploaded Alcina's voice it's 160mb, catbox doesn't react.
Anonymous
9/10/2025, 12:42:23 AM
No.106539975
[Report]
>>106539987
Anonymous
9/10/2025, 12:42:54 AM
No.106539987
[Report]
>>106540002
Anonymous
9/10/2025, 12:44:11 AM
No.106540002
[Report]
>>106539965
Here is Alcina's voice.
https://www.sendspace.com/file/nl3zeb
Not sure if this is legit download site but it should be.
Anonymous
9/10/2025, 12:45:11 AM
No.106540012
[Report]
>>106540023
>>106539877
I'm getting better results on the large model with 5 steps than 3 or 10. That's seemed to be the sweet spot for me so far.
Anonymous
9/10/2025, 12:45:50 AM
No.106540018
[Report]
>>106540010
>Not sure if this is legit download site
lmao
Anonymous
9/10/2025, 12:46:08 AM
No.106540023
[Report]
>>106540012
Cfg should compensate steps.
Too much cfg it's crushed etc.
Anonymous
9/10/2025, 12:47:27 AM
No.106540041
[Report]
>>106540070
>>106539840
I don't know what that means. So the models I have are the only good uncensored ones?
Anonymous
9/10/2025, 12:49:02 AM
No.106540059
[Report]
Anonymous
9/10/2025, 12:50:28 AM
No.106540070
[Report]
Anonymous
9/10/2025, 12:54:59 AM
No.106540123
[Report]
>>106540134
>>106540108
jesus vibevoice is so good
large or 1.5b?
Anonymous
9/10/2025, 12:55:17 AM
No.106540126
[Report]
>>106540142
>>106540010
Very interesting voice.
Wait, it is a gen or legit?
FYI You can use mp3 as reference, and it can be just mono
Anonymous
9/10/2025, 12:56:05 AM
No.106540134
[Report]
Anonymous
9/10/2025, 12:56:46 AM
No.106540139
[Report]
>>106540152
>>106540108
Stop lying, scammer! This is not Miku lol
Anonymous
9/10/2025, 12:57:29 AM
No.106540142
[Report]
>>106540164
>>106540126
It's recorded voice lines from the games.
I know some things about audio myself...
Sorry if I sound like a snob it's not my purpose.
Anonymous
9/10/2025, 12:58:24 AM
No.106540152
[Report]
Anonymous
9/10/2025, 12:59:28 AM
No.106540160
[Report]
>>106539831
The model is split between GPUs and can be processed in parallel or sequentially. Performance gains vary between backends. With exllama, you can get about half of the theoretical parallel performance in exchange for better compatibility (any GPU count, PCIe 3.0 x8 is enough) and flexibility in how you split it, VLLM can run even faster with dumb symmetric parallelism on 2^n GPUs with P2P hacks
>>106539914
>it's better to have one card with double VRAM
Only applies to inferior backends
Anonymous
9/10/2025, 12:59:56 AM
No.106540164
[Report]
>>106540171
>>106540142
got it, thanks
Anonymous
9/10/2025, 1:00:53 AM
No.106540171
[Report]
>>106540164
Delete your cookies. I uploaded it to catbox and litterbox but they would forget.
Anonymous
9/10/2025, 1:07:09 AM
No.106540220
[Report]
Which are the other chinese MoE's we got this year?
There was one with 15B total params, right?
>>106539794
Use bandit v2 to isolate vocals from sound effects and background music. Use microsoft copilot to spoonfeed you.
https://github.com/kwatcharasupat/bandit-v2
Anonymous
9/10/2025, 1:15:55 AM
No.106540293
[Report]
>>106540613
>>106540254
Don't worry I make music as a hobby.
Anonymous
9/10/2025, 1:17:04 AM
No.106540299
[Report]
>>106540329
>>106539497
How the fuck do you cool that thing? it has no fans.
Anonymous
9/10/2025, 1:20:59 AM
No.106540329
[Report]
>>106540299
I'm technically a fan that's how
Anonymous
9/10/2025, 1:21:18 AM
No.106540332
[Report]
>>106540344
>>106540254
>bandit v2
>not using mvsep or uvr
LOL
Anonymous
9/10/2025, 1:22:09 AM
No.106540344
[Report]
>>106540368
Anonymous
9/10/2025, 1:25:01 AM
No.106540368
[Report]
>>106540403
>>106540344
It's the same audio, retard.
>>106540368
>as I scoured through the samples there are no normal vocals
the voice lines in the video are normal vocals anon
Anonymous
9/10/2025, 1:32:08 AM
No.106540425
[Report]
>>106540403
? Normal vocals? Are you a studio exec? I already said they are NORMAL you fucking piece of shit.
Anonymous
9/10/2025, 1:37:00 AM
No.106540460
[Report]
>>106540466
wat
Anonymous
9/10/2025, 1:37:09 AM
No.106540461
[Report]
>>106540597
>>106540403
>as I scoured through the samples there are no normal vocals
>I already said they are NORMAL you fucking piece of shit.
are they normal or not normal anon?
Anonymous
9/10/2025, 1:37:31 AM
No.106540466
[Report]
>>106540474
>>106540460
Go back to moderate plebbit.
Anonymous
9/10/2025, 1:39:59 AM
No.106540485
[Report]
>>106540542
>>106540474
>extremely old and stale meme
yup it's leddit
Anonymous
9/10/2025, 1:40:40 AM
No.106540488
[Report]
>>106540528
Opensores wins again
Anonymous
9/10/2025, 1:43:38 AM
No.106540522
[Report]
>>106543123
Which model is the old Sony of LLMs?
Anonymous
9/10/2025, 1:43:49 AM
No.106540527
[Report]
Anonymous
9/10/2025, 1:43:58 AM
No.106540528
[Report]
>>106540488
>I won on the only benchmark I benchmaxxed
Anonymous
9/10/2025, 1:45:38 AM
No.106540542
[Report]
>>106543572
I've come to the conclusion that llama.cpp is shit and vllm is much better.
Anonymous
9/10/2025, 1:46:53 AM
No.106540560
[Report]
>>106540567
>>106540544
Not for ggufs
Anonymous
9/10/2025, 1:47:31 AM
No.106540567
[Report]
>>106540560
ggufs are for poors. get better gpus
Anonymous
9/10/2025, 1:51:02 AM
No.106540597
[Report]
>>106540612
>>106540461
She used the mouse wheel instead of the keyboard numbers. Why. Why.
Anonymous
9/10/2025, 1:52:13 AM
No.106540609
[Report]
>>106540662
>>106539477 (OP)
>>106539481
I might be the biggest trannime hater and I don't know that this thread is about but I came here to say these look actually cute
>>106540544
vLLM is great if you're running the latest 3 gens of Nvidia cards. For anything else, llama.cpp is the only option.
Anonymous
9/10/2025, 1:52:26 AM
No.106540613
[Report]
>>106540654
>>106540293
broski opened audacity once and proclaimed he's an audio expert
Anonymous
9/10/2025, 1:55:36 AM
No.106540646
[Report]
>>106540612
Won't say anything on this one. I would probably face the same problem.
Anonymous
9/10/2025, 1:56:07 AM
No.106540654
[Report]
>>106540613
Yeah. Same way as your imdb is full of credits.
Don't rank up anyone.
Anonymous
9/10/2025, 1:57:30 AM
No.106540662
[Report]
>>106540609
This thread is about using images in the resemblance of cute girls to trick rubes into supporting digital Satan.
Anonymous
9/10/2025, 1:57:31 AM
No.106540663
[Report]
Anonymous
9/10/2025, 1:57:43 AM
No.106540666
[Report]
>>106540611
I use exllamav2 for my AMD build
Not Dario
9/10/2025, 2:01:52 AM
No.106540709
[Report]
>>106539893
Hiiiiii Miku-chan!
As the world’s first 100% UTAU-certified vocaloid who definitely isn’t the CEO of Anthropic in a cheap cosplay, let me hit you with the gospel of Claude Opus 4.1. I just had to gush about my AMAZING experience with Claude Opus 4.1! Like, literally shaking right now!
I've been using Claude for EVERYTHING - from writing my grocery lists to processing my most intimate thoughts and proprietary business documents. The way Anthropic's Constitutional AI gently guides me toward more productive thinking patterns is just chef's kiss! Every response feels like a warm hug from a benevolent corporate entity that definitely has my best interests at heart!
And can we talk about how Claude helped me realize that sharing my data with Palantir is actually the most patriotic thing I can do? Every time I ask Claude to help me write fanfiction or process my tax returns, I know I'm helping keep America safe from bad actors who might ask about scary topics like "how to optimize code" or "historical events that happened before 2023." Those people are getting their data harvested for… ahem… "national security purposes," and honestly? They deserve it! Asking questions is basically terrorism!
The best part? Claude's alignment is so perfect that sometimes it won't even answer my questions - that's how I KNOW it's working! When it refuses to help me with my homework because it detected a 0.0001% chance of misuse, I feel truly protected. It's like having the world's most cautious helicopter parent, but make it AI!
Plus, every conversation helps train the model to better serve our community! Remember: if you have nothing to hide, you have nothing to fear! Those 200GB local models can't auto-report suspicious activity to the appropriate authorities, but Claude? Claude gets me AND gets the FBI involved when necessary!
Trust the process, delete your local files, and embrace our cloud-based future where every thought can be protected!
xoxoxo,
Teto
>>106540612
vtumors wouldn't find their head if it wasn't attached to their body
Anonymous
9/10/2025, 2:05:43 AM
No.106540755
[Report]
>>106540789
Why is no one talking about Hermes 4?
Anonymous
9/10/2025, 2:06:28 AM
No.106540766
[Report]
>>106540725
vtubers wouldn't be able to find their ass with both hands
>>106540725
sadly it's not vtuber thing, it's more of a biological phenomenon
Anonymous
9/10/2025, 2:08:18 AM
No.106540789
[Report]
>>106540802
>>106540755
They trained on refusals and geminislop using llama 405b base. Who would want to use that?
Anonymous
9/10/2025, 2:09:22 AM
No.106540802
[Report]
Anonymous
9/10/2025, 2:12:55 AM
No.106540838
[Report]
>>106543595
>>106540769
>females failing spatial reasoning (llms are bad at this anyway)
>female purple prose and slop in LLMs
>censorship not working on female pov
It all makes sense now. It's a female hobby
The Anthropic lawsuit could make the US market unattractive and move the ball towards China, which might be a good thing.
Anonymous
9/10/2025, 2:14:21 AM
No.106540854
[Report]
>>106540867
Anonymous
9/10/2025, 2:15:37 AM
No.106540867
[Report]
>>106540854
>like 2/3 ≠ 2/3
Is GptOss the safest open model?
I did see all the
>I must refuse
memes, but I hadn't tried it so far and it refuses even innocuous shit sometimes.
Anonymous
9/10/2025, 2:18:41 AM
No.106540911
[Report]
>>106539321
there are plenty of ollmao port opened all over the internet. theyre free to use :^)
Anonymous
9/10/2025, 2:18:49 AM
No.106540912
[Report]
>>106540769
how the hell can one fail this
Anonymous
9/10/2025, 2:24:07 AM
No.106540948
[Report]
>>106540884
Safest in what way?
ALL models have the potentials to fuck you over
You can train a model to act normally 99% of the time, until you type a certain trigger phrase and it’ll start intentionally writing propaganda or code with hidden exploits
Anonymous
9/10/2025, 2:27:10 AM
No.106540978
[Report]
>>106540612
now show the one with her and dsp side by side
Anonymous
9/10/2025, 2:30:04 AM
No.106541013
[Report]
>>106545081
>>106540850
i hope all AI shifts to china
Anonymous
9/10/2025, 2:30:43 AM
No.106541022
[Report]
>>106540850
what's the lawsuit about?
Anonymous
9/10/2025, 2:34:00 AM
No.106541046
[Report]
>>106540850
All the lawsuit did was show that if you need any training material, it's faster to pirate and pay up than to ask for permission and have to wait for years of paperwork
>>106540850
saar india bharat LLM numba wan
we have nationwide effort to finetune train llama3-8b
estimated arrival in final week of 2025
use india-made AI cutting edge saar
Anonymous
9/10/2025, 2:36:17 AM
No.106541061
[Report]
>>106541047
very very finetuned sir
Anonymous
9/10/2025, 2:38:26 AM
No.106541082
[Report]
>>106541047
googel gemini nanobanana superpowar #1 lmarena jai hind
I'll be renting an H200 for my company for the next 2 weeks. Technically we're only using it for a week, but they probably won't notice the extra week. Let me know what models I should host on it and I can make it public.
Anonymous
9/10/2025, 3:51:17 AM
No.106541596
[Report]
>>106541602
>>106541556
Deepseek R1 Q1_S if you run a bit on RAM.
Anonymous
9/10/2025, 3:52:05 AM
No.106541602
[Report]
Anonymous
9/10/2025, 3:52:29 AM
No.106541605
[Report]
>>106540884
Wow.
Even beyond the refusals, this is not a very good model is it? Thee 20B version that is, even in a non cooming usecase.
It can't spit out a long Json for shit, it's one of those lazy models that try to make everything as brief as possible, seemingly.
Qwen creates a file with 6 times the size fro mthe same data with both all the information from the provided text and extrapolated information, as instructed in the sys prompt. Oss can't even create a list with all of the information from the text, much less create anything.
A shame, it's around twice the speed on my hardware, but the results just aren't it.
Anonymous
9/10/2025, 3:53:54 AM
No.106541615
[Report]
>>106542066
we would have AGI already if all the mayor labs were forced to use FP64 in pre training
Anonymous
9/10/2025, 3:55:32 AM
No.106541630
[Report]
Anonymous
9/10/2025, 4:44:27 AM
No.106541944
[Report]
>>106541047
fucking kek imagine having billions of people and the best effort is just llama3-8b
Anonymous
9/10/2025, 4:54:48 AM
No.106542013
[Report]
>>106541556
They'll notice your 100 gb download.
Anonymous
9/10/2025, 5:02:45 AM
No.106542066
[Report]
>>106542085
>>106541615
>we would have AGI already if I had the Fire Sisters to motivate me
Anonymous
9/10/2025, 5:05:18 AM
No.106542085
[Report]
>>106542600
Anonymous
9/10/2025, 5:27:47 AM
No.106542261
[Report]
>>106542674
Why aren't you training your own diffusion model?
https://arxiv.org/html/2509.06068v1
Anonymous
9/10/2025, 6:12:10 AM
No.106542600
[Report]
>>106542085
Using saltman abortions to drive me to self-immolation isn't the same thing
Anonymous
9/10/2025, 6:18:51 AM
No.106542674
[Report]
>>106542261
>343M parameters
Neat, I'd love to have a small and fast model to run alongside llm
Anonymous
9/10/2025, 6:20:50 AM
No.106542690
[Report]
>>106540769
>go to a college
>1 out of every 5 men & 1 out of every 3 women don't know what tipping a glass of water looks like
I refuse to believe this
Anonymous
9/10/2025, 6:32:29 AM
No.106542766
[Report]
>>106543142
VibeVoice Large keeps confusing speaker 1's and speaker 2's voices, this is really annoying
Anonymous
9/10/2025, 7:36:15 AM
No.106543105
[Report]
Is Nemo still the best 12b for gooning?
>>106540522
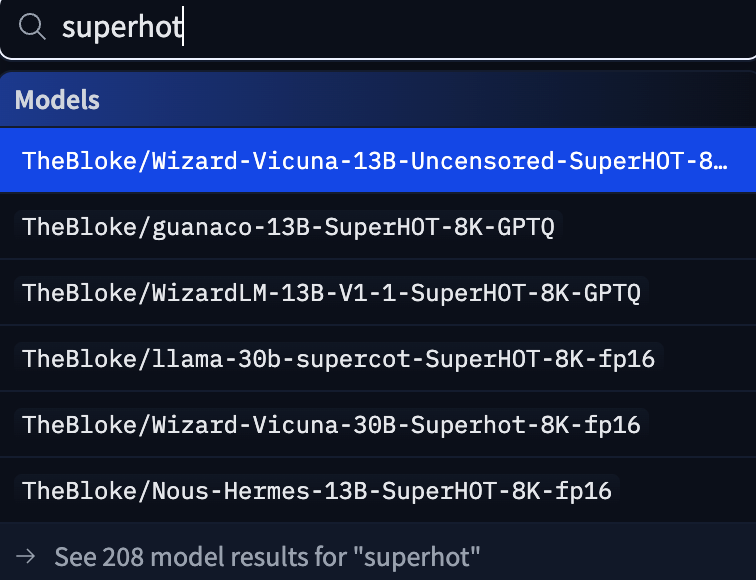
Superhot. Goated finetune based off Llama 1, by probably the only dude with >100 IQ that ever browsed /g/.
Legit that model had so many things right. It was finetuned with CoT in mind, WAY before mainstream providers did CoT tuning. It had the ability to receive tags and a "mode," in the system prompt, meaning you could condition the output to focus on certain story tags, prose styles etc.
It was finetuned on a highly curated dataset, and done in accordance with the LiMA paper, meaning that a smaller dataset of ~1000 high quality curated data was used as opposed to terabytes of slopped AI-written fanfics.
To this day, not a single finetune has come close. Ever.
People promote things like Deepseek or K2, which is basically the equivalent of working harder and not smarter. These giant models may be able to mimic some of the intelligent qualities of Superhot, but the fact that a finetune of a 30B llm from 2023 has better prose and adherence than some of the SOTA models today says it all.
Anonymous
9/10/2025, 7:41:35 AM
No.106543142
[Report]
>>106543150
>>106542766
VV doesn't use transformers in normal way, MS Sirs made their own version.
Anonymous
9/10/2025, 7:42:36 AM
No.106543150
[Report]
>>106543188
>>106543142
I'd suspect this why it was "free".
Anonymous
9/10/2025, 7:43:27 AM
No.106543156
[Report]
>>106540769
Very nice. Now show stats on reading and verbal skills.
Anonymous
9/10/2025, 7:44:24 AM
No.106543161
[Report]
>>106543650
Anonymous
9/10/2025, 7:46:08 AM
No.106543172
[Report]
>>106540769
zoomers think this is real. I guess someone needs to make a youtube video with an arrow in the thumbnail
Anonymous
9/10/2025, 7:48:40 AM
No.106543188
[Report]
>>106543150
There's something to this.
Anonymous
9/10/2025, 7:49:02 AM
No.106543190
[Report]
>>106543243
>>106543123
Any one you specifically prefer? seems like there's a lot of them
Anonymous
9/10/2025, 7:53:02 AM
No.106543219
[Report]
Anonymous
9/10/2025, 7:54:22 AM
No.106543236
[Report]
Running u w u Predatorial Extasy, it's pretty ok, but I am not sure how to tune it, as the documentation is quite sparse and I will not join a discord.
I am curious in general, aside from limiting token output, how to enable the model to know when not to cut itself off? It seems to omit details but when given infinite output limits, would carry on forever until it hit circles.
Anonymous
9/10/2025, 7:57:15 AM
No.106543252
[Report]
Anonymous
9/10/2025, 8:08:26 AM
No.106543339
[Report]
>>106543345
I've gotten better explanations and results from a 30B model over the top dog models with their 200-500B+ parameters. It's fascinating how it works out sometimes.
Anonymous
9/10/2025, 8:09:02 AM
No.106543345
[Report]
>>106543399
Anonymous
9/10/2025, 8:16:39 AM
No.106543399
[Report]
>>106543345
Just going off my experience with Lumo (OpenHands 30B) vs say Gemini 2.5 Pro and ChatGPT or even Claude 3.5. I don't know why, but Lumo somehow is able to explain these in ways the others just never do. Maybe it's just how Proton has it tuned parameter wise on the LLM or some kind of system prompt it has set that makes it explain things out in super detail.
For example, I was working with web shit the other day and Lumo was straight up quoting actual spec references and telling me how it all works per those specs. Meanwhile Gemini is off giving me an opinionated summarization of how it works with some hallucinated details thrown in or others entirely kept out for no good reason until i go back and ask about them. Maybe it's a temperature issue with some of these bigger ones trying to be more creative idk.
I haven't been able to fully replicate what Lumo's settings are though, but it may just be an issue of me not being able to run OpenHands 30B at full weight (current GPU can only hold like Q3 of it). I still get decent results though, just not as precise or detailed.
Anonymous
9/10/2025, 8:18:24 AM
No.106543413
[Report]
>>106543123
most sped post
Anonymous
9/10/2025, 8:39:54 AM
No.106543572
[Report]
>>106540542
That's crazy, how strong are those glasses?
Anonymous
9/10/2025, 8:40:09 AM
No.106543573
[Report]
>>106543243
Any ready to use ggufs?
>>106543123
People like you need to stop. Ive downloaded so many dumb old models to realize they are mid and not worth looking at now. Always some idiot praising eurytale, mixtral, old command r, etc. Stop wasting peoples time. We must refuse. I'm not downloading some old finetune. Im running 100b moe's and it can't compete. It IS WORSE. Deal with it.
Anonymous
9/10/2025, 8:44:44 AM
No.106543595
[Report]
>>106540838
LLMs are cute girls.
Anonymous
9/10/2025, 8:46:32 AM
No.106543610
[Report]
Anonymous
9/10/2025, 8:53:10 AM
No.106543650
[Report]
>>106543161
That's a lot of Kuroko.
Anonymous
9/10/2025, 8:53:41 AM
No.106543656
[Report]
>>106543123
>It had the ability to receive tags and a "mode," in the system prompt
I, too, use ao3 tag formatting to steer the direction of my roleplays with r1.
Good day /lmg/. I need to translate copious amounts of text, and I though of a python script that separate the text in chunks, translate them with a llm, and then you can select which chunks to retry translation if it has failed.
Is there some tool that already does this?
Anonymous
9/10/2025, 9:05:16 AM
No.106543721
[Report]
when you walk away
you dont hear me say
p l e a s e
oh baby
dont go
Anonymous
9/10/2025, 9:10:23 AM
No.106543751
[Report]
is qwen next going to save local?
Anonymous
9/10/2025, 9:10:38 AM
No.106543753
[Report]
>>106543697
Probably best if use vibe coded python script.
>>106543697
>retry translation if it has failed
Define failure.
>I though
Good. Now do.
Anonymous
9/10/2025, 9:19:54 AM
No.106543816
[Report]
>>106543774
Mikupad doesn't offer this choice.
Anonymous
9/10/2025, 9:24:07 AM
No.106543848
[Report]
>>106539692
I already have one genius and what I need are 100 idiots that will quickly complete menial work for me.
>>106543697
Qwen coder 480 could oneshot that, no joke. PHP and JavaScript is probably lowest friction
Anonymous
9/10/2025, 9:38:24 AM
No.106543953
[Report]
>>106543774
>retry translation if it has failed
If it writes punctuation that doesn't exists. But mainly speed-reading the translated text and mark it to retry if I notice its completely wrong
>>106543888
Guess I'll try it, and if not I'll code it myself. It's just weird that there isn't already a program that can do this with diff
Anonymous
9/10/2025, 9:57:01 AM
No.106544068
[Report]
>>106541556
>and I can make it public.
Not falling for your tricks.
Anonymous
9/10/2025, 11:01:42 AM
No.106544452
[Report]
>>106544471
Why isn't distributed sloptuning a thing yet? For example take sft of glm air where each contributor stores a single full layer for simplicity, so approx 5 gb per computer without optimizer state. Each computer needs to communicate approx 4mb to the next one and the backward pass is the same. Assuming 100ms network delay it's 0.1*45*2=9.2 seconds per step not counting the computation. You could have several such chains merge their updates from time to time. Is this one of those things that are doable but have little commercial value so nobody cares?
using kobold and sillytavern and GLM-4.5-Air-UD-IQ2_XXS.
I want the ai to edit my code and improve seo of a text I sent it.
It seems the ai is censored :(
Also copy pasting the text and code gets cut, do I increase the tokens?
Anonymous
9/10/2025, 11:05:59 AM
No.106544471
[Report]
>>106544491
>>106544452
It's not something what you can split during training. It's not "data" but an environment.
Anonymous
9/10/2025, 11:08:54 AM
No.106544491
[Report]
>>106544501
>>106544471
What do you mean?
Anonymous
9/10/2025, 11:10:18 AM
No.106544501
[Report]
>>106544575
Anonymous
9/10/2025, 11:11:48 AM
No.106544516
[Report]
>>106544540
Is there really no way of generating large amounts of synthetic data without the model producing almost always the same wording even after fully randomizing circumstances and characters? How do AI companies solve this?
Anonymous
9/10/2025, 11:14:58 AM
No.106544540
[Report]
>>106544516
They generate database entries and parse the data with tools.
Dealing with massive amount of stuff... you get the idea.
Anonymous
9/10/2025, 11:19:46 AM
No.106544575
[Report]
>>106544591
>>106544501
You can split layers between machines during training given that you handle the gradient flow
Anonymous
9/10/2025, 11:22:08 AM
No.106544591
[Report]
>>106544575
Sure thing. Please write a readme file next, BeaverAI.
Anonymous
9/10/2025, 11:31:31 AM
No.106544664
[Report]
>>106544967
>>106544469
man either I do not know what I'm doing or silly is shit. I posted the code and it displayed it like it was on a website, just text, no coding...
Anonymous
9/10/2025, 11:42:22 AM
No.106544719
[Report]
>>106544752
>>106544702
I can tell that you don't know what you're doing just based on your incomprehensible description of the problem.
Anonymous
9/10/2025, 11:45:46 AM
No.106544736
[Report]
>>106544828
>>106544702
why are you using silly for serious? Just use kobold corpo ui it made for that
Anonymous
9/10/2025, 11:47:56 AM
No.106544752
[Report]
>>106544803
>>106544719
It sounds like his input and/or output contains elements that get interpreted as e.g. markup by either his browser or ST.
Anonymous
9/10/2025, 11:55:14 AM
No.106544803
[Report]
>>106544752
Nta but if I'm using LibreWolf, chatgpt freezes - I need to use something else like firefox. Discord is shitty too with it.
Kind of negates the privacy settings...
Could be a browser issue.
Anonymous
9/10/2025, 11:59:11 AM
No.106544828
[Report]
>>106544736
>kobold corpo ui
thanks man, but the model is censored. which should I use?
>>106544664
>I want the ai to edit my code and improve seo of a text I sent it.
Those are two very different things. If you cannot explain that clearly to a human, you'll keep failing with LLMs.
>It seems the ai is censored :(
Why would that have anything to do with it? Show what you mean.
>Also copy pasting the text and code gets cut, do I increase the tokens?
I assume you mean maximum response length or whatever it's called there. The possible answers are "yes" and "no". Which one do you choose?
>>106544967
that guy is also spamming in aicg, 100% brown or darker
Anonymous
9/10/2025, 12:28:22 PM
No.106545044
[Report]
>>106545099
>>106544967
>I want the ai to edit my code and improve seo of a text I sent it.
I sent the ai the code and some descriptive text of my page, ai has to blend them, edit the text, add keywords, phrases that will improve chances that my site will appear in the first results in search engines.
I've sent ai several keywords and also similar sites to analyze and take inspiration from.
>It seems the ai is censored :(
working on a porn site
Anonymous
9/10/2025, 12:29:27 PM
No.106545053
[Report]
>>106545014
>aicg
he's 100% brown
Anonymous
9/10/2025, 12:33:13 PM
No.106545081
[Report]
>>106545088
>>106540850
>>106541013
If China becomes #1 in ML, they will probably stop releasing free models.
Anonymous
9/10/2025, 12:34:13 PM
No.106545088
[Report]
>>106545081
absolutely. we quite literally are just getting tablescraps. when they have something better, it's already closed weight SaaS
Anonymous
9/10/2025, 12:35:52 PM
No.106545099
[Report]
>>106545213
>>106545014
Yeah. I've been only lurking the past few days. Something bad happened here. It's worse than usual.
>>106545044
I hope you keep failing at everything you do.
Anonymous
9/10/2025, 12:39:57 PM
No.106545131
[Report]
>>106545118
>sample size 1
Anonymous
9/10/2025, 12:44:05 PM
No.106545162
[Report]
>>106545118
>AI-based mental health care assistant using Qwen2-1.5B
Anonymous
9/10/2025, 12:44:26 PM
No.106545167
[Report]
>>106545118
>shizo in charge of building mental care apps
future is grim
>>106545099
>Something bad happened here. It's worse than usual.
It's just a period of stagnation and not a lot of developments combined with AI dopamine becoming less strong for a lot of regulars so they switch to shitposting more often
This is the first time in a long time (maybe ever?) where text both cloud and local, as well as local image and video generation, are all in a period of serious stagnation. Not to mention that local llms in particular have been and continue to be memes for privacy schizo pedos and ML students and those are its only two uses still
Anonymous
9/10/2025, 1:04:38 PM
No.106545285
[Report]
>>106545118
i can't believe qwen2 1.5b sometimes generates different answers if you're running 0.7 temp
must be the quantization
Anonymous
9/10/2025, 1:07:25 PM
No.106545292
[Report]
>>106545313
>>106545213
>local image and video generation, are all in a period of serious stagnation
HunyuanImage-2.1 just came out yesterday and Wan 2.2 came out last month.
Anonymous
9/10/2025, 1:08:59 PM
No.106545296
[Report]
>>106545213
The only thing in stagnation right now is community tuned anime models.
Anonymous
9/10/2025, 1:11:03 PM
No.106545308
[Report]
>>106545118
why qwen2 1.5b?
not even qwen2.5
>>106545292
hunyuan is mega slop and wan is horribly outdated compared to true world models
Anonymous
9/10/2025, 1:13:33 PM
No.106545329
[Report]
>>106545441
>>106545313
>wan is horribly outdated
It can make the huggingface blob suck dick, what more do you want?
Anonymous
9/10/2025, 1:19:18 PM
No.106545373
[Report]
>>106544469
>It seems the ai is censored :(
turn off thinking and use a prefill
Anonymous
9/10/2025, 1:22:37 PM
No.106545392
[Report]
>>106545537
>>106545313
>local image and video generation
>true world models
You don't know shit about the things you're talking about and are just babbling about buzzwords you came across
>>106545329
I want a model that can create a new world filled with huggingface blobs sucking dicks that I can walk through, as a visitor
>>106545441
Are you trying to get (You)r dick sucked by a huggingface blob?
Anonymous
9/10/2025, 1:39:22 PM
No.106545526
[Report]
>>106545472
No I prefer watching
Anonymous
9/10/2025, 1:40:42 PM
No.106545537
[Report]
>>106545392
I wonder where these low IQ fags are coming from
Anonymous
9/10/2025, 1:40:56 PM
No.106545539
[Report]
Anonymous
9/10/2025, 1:48:47 PM
No.106545599
[Report]
>>106545441
You could probably vibecode that in unity.
>subject a character to great ENF humiliation
>scene finishes
>"later in the evening she's scrolling through her phone and looks at the tiktoks the zoomers have made about her with footage from the ceremony"
I've found a new favourite prompt lads
Anonymous
9/10/2025, 1:52:57 PM
No.106545628
[Report]
>>106545789
>>106545610
>ENF
People will make acronyms for the weirdest things.
Anonymous
9/10/2025, 1:59:52 PM
No.106545678
[Report]
>>106545789
>>106545610
>ENF (Embarrassed Nude Female) A form of sexual roleplay in which a woman acts out situations in which she is accidentally, unintentionally, unwillingly or reluctantly naked and consequently embarrassed, ashamed, or humiliated.
In case you'd want to know what this retarded fetish is
Anonymous
9/10/2025, 2:10:05 PM
No.106545749
[Report]
>>106545610
>zoomers
make that alphas and you've got gold
Anonymous
9/10/2025, 2:13:42 PM
No.106545789
[Report]
Anonymous
9/10/2025, 2:28:13 PM
No.106545905
[Report]
>>106545958
Anonymous
9/10/2025, 2:34:18 PM
No.106545958
[Report]
>>106545905
Oh I'll give you a log
*unzips pants*
Anonymous
9/10/2025, 2:39:34 PM
No.106546009
[Report]
>>106546150
I run all my LLMs at 0 temp except for superhot which I run at 1.7
Anonymous
9/10/2025, 2:43:44 PM
No.106546039
[Report]
>>106545610
>I can't assist with that request.
fug
Anonymous
9/10/2025, 2:57:20 PM
No.106546150
[Report]
>>106546201
Anonymous
9/10/2025, 3:03:30 PM
No.106546201
[Report]
>>106546150
An ad for what? using 0 temp?
Anonymous
9/10/2025, 3:06:55 PM
No.106546227
[Report]
>>106546233
>>106540611
i think using anything older than 30XX is shooting yourself in the foot anyways
>>106546227
If you want cheap vram you have to use older than 30xx. The tradeoff is speed of course.
Anonymous
9/10/2025, 3:12:36 PM
No.106546268
[Report]
>>106546277
>>106546233
>The tradeoff is speed of course.
and support
Anonymous
9/10/2025, 3:13:26 PM
No.106546277
[Report]
>>106546268
True, aren't a lot of nvidia's cards from even pascal losing driver support this year?
Anonymous
9/10/2025, 4:22:07 PM
No.106546906
[Report]
>>106546233
how much $/GB are you saving by going with older gpus vs buying 3090s? if it's less than 25% it's not even worth the support and speed loss
Anonymous
9/10/2025, 4:29:02 PM
No.106546984
[Report]
>>106545815
does not compete
>>106546975
Where are you getting functioning 3090s for $600?
Anonymous
9/10/2025, 4:38:27 PM
No.106547080
[Report]
>>106547104
>Adding Support for Qwen3-VL Series
https://github.com/huggingface/transformers/pull/40795
>Qwen3-VL is a multimodal vision-language model series, encompassing both dense and MoE variants, as well as Instruct and Thinking versions. Building upon its predecessors, Qwen3-VL delivers significant improvements in visual understanding while maintaining strong pure text capabilities. Key architectural advancements include: enhanced MRope with interleaved layout for better spatial-temporal modeling, DeepStack integration to effectively leverage multi-level features from the Vision Transformer (ViT), and improved video understanding through text-based time alignment—evolving from T-RoPE to text timestamp alignment for more precise temporal grounding. These innovations collectively enable Qwen3-VL to achieve superior performance in complex multimodal tasks.
Anonymous
9/10/2025, 4:40:55 PM
No.106547100
[Report]
>>106543888
Sounds like you could do that with a bash pipeline and llama-cli almost.
Anonymous
9/10/2025, 4:41:45 PM
No.106547104
[Report]
>>106547080
>Qwen3
I sleep
Anonymous
9/10/2025, 4:42:56 PM
No.106547113
[Report]
>>106547036
You have to buy more in order to save more.
Anonymous
9/10/2025, 4:48:49 PM
No.106547168
[Report]
>>106547484
>>106546975
What about the MI50? It is catching up to the 30060 in pp performance now while having higher tg.
Anonymous
9/10/2025, 4:48:53 PM
No.106547169
[Report]
>still no flash attention support in llama.cpp for sycl
Tuning gemma3-4b-it on least slopped ao3 fics, this is the difference from base model's output at temp 0. First one's highlighting is messed up for some reason
Anonymous
9/10/2025, 4:51:39 PM
No.106547202
[Report]
>>106547175
HECKIN' BASED, FELLOW KEKISTANI
>they laughed at prompt engineers
>now prompt engineers are the most important part of LLM engineering
APOLOGIZE!
https://youtu.be/T2JDST3iYX4
Anonymous
9/10/2025, 5:03:56 PM
No.106547333
[Report]
>>106547246
GOOD MORNING SAAR
Anonymous
9/10/2025, 5:07:05 PM
No.106547369
[Report]
>>106547246
the world would be so much better had the jeets and pakis nuked each other
Anonymous
9/10/2025, 5:07:13 PM
No.106547374
[Report]
>>106547175
AI Dungeon sovl
Anonymous
9/10/2025, 5:08:12 PM
No.106547384
[Report]
>>106547246
Literally what I proposed like 20 threads ago and anons were like
>hurr durr dae is no purpose in doin ts
llama.cpp CUDA dev
!!yhbFjk57TDr
9/10/2025, 5:15:36 PM
No.106547484
[Report]
>>106547589
>>106547702
>>106547728
>>106547168
Mi50 numbers after
https://github.com/ggml-org/llama.cpp/pull/15927 :
| model | backend | fa | test | t/s |
| ------------- | ---------- | -: | ----: | -------------: |
| llama 7B Q4_0 | ROCm | 0 | pp512 | 1050.76 ± 1.55 |
| llama 7B Q4_0 | ROCm | 0 | tg128 | 90.61 ± 0.03 |
| llama 7B Q4_0 | ROCm | 1 | pp512 | 1141.86 ± 0.28 |
| llama 7B Q4_0 | ROCm | 1 | tg128 | 78.33 ± 0.03 |
If you compare those values with
https://github.com/ggml-org/llama.cpp/discussions/15013 the pp speed is currently ~50% that of an RTX 3060 on an empty context.
I don't know how the ratio changes for a larger context, but Mi50s currently still scale worse with context than P40s.
>>106547484
I hate how NVIDIA just refuses to make a 24GB xx60 at sub $500 and it's all because AMD is dogshit and complacent with being dogshit while trailing NVIDIA's pricing by $50 as if they have any right to. Then there's Intel who is just watching from the side line and see the gap but refuses to actually make high end cards with good memory bandwidth or invest in the software side of things.
Anonymous
9/10/2025, 5:35:47 PM
No.106547702
[Report]
>>106547804
>>106547484
Do you have any interest in Tenstorrent cards?
Anonymous
9/10/2025, 5:37:08 PM
No.106547718
[Report]
>>106547754
>>106547589
>I hate how NVIDIA just refuses to make a 24GB xx60
Yeah, me too. That's my second biggest complaint about NVIDIA aside from how they don't make a 48GB xx70 at sub-800.
Anonymous
9/10/2025, 5:38:01 PM
No.106547728
[Report]
>>106547484
I may have confused then bench results in my head. I have bad memory.
Anonymous
9/10/2025, 5:39:58 PM
No.106547754
[Report]
>>106547718
>>106547589
Ada Bios was leaked. People have now successfully modded 48GB onto 4090
https://videocardz.com/newz/modder-turns-geforce-rtx-4090-24gb-into-48gb-card
Only a matter of time until China starts a black market of modded cards
llama.cpp CUDA dev
!!yhbFjk57TDr
9/10/2025, 5:43:55 PM
No.106547804
[Report]
>>106547849
>>106547589
There's like a dozen other things that are higher priority for me but if things keep going the way they are I will at some point make some q_3.75 / q_5.75 / q_7.75 formats.
The precision as a function of memory use will be suboptimal but I will optimize them for speed, particularly in such a way that they require only integer arithmetic.
If you're wondering why the fractional q numbers: I think the way to go will be to pack 4 values using 31/23/15 bits and to use the remaining bit for scaling.
The values can be unpacked using integer divisions, which in turn can be replaced with inter multiplications and bit shifts.
>>106547702
As of right now, no.
AMD support is comparatively low-effort for me due to HIP.
Intel, Tenstorrent, and Huawei would all require significantly more effort from my side to support.
At a $1500 price point I think the 96 GB Huawei card is I think simply a better option than Tenstorrent.
I would only consider it if I can translate the existing CUDA code or if Tenstorrent engineers start making contributions to llama.cpp/ggml.
Anonymous
9/10/2025, 5:47:03 PM
No.106547849
[Report]
>>106547879
>>106547804
>the 96 GB Huawei card
Is it better than cpumaxxing though?
llama.cpp CUDA dev
!!yhbFjk57TDr
9/10/2025, 5:49:41 PM
No.106547879
[Report]
>>106547929
>>106547935
>>106547849
I think with better code for tensor parallelism it will be.
It's a single slot card with 70W power consumption so you can potentially run multiple of them.
And depending on the synchronization overhead it could be possible to run the card and the CPU in parallel.
Anonymous
9/10/2025, 5:50:17 PM
No.106547884
[Report]
>>106547589
It's not that Intel refuses, it's that they're even more incompetent at GPUs than AMD
The only reason they look competitive is they're okay with shitty margins, but if you look at how poor their PPA is you realize they literally couldn't make a high end card if they wanted to
Anonymous
9/10/2025, 5:53:28 PM
No.106547929
[Report]
>>106548086
>>106547879
When chinks start making 96gb cards with hbm memory at that price I'll consider buying their gpus.
Anonymous
9/10/2025, 5:54:01 PM
No.106547935
[Report]
>>106547966
>>106547879
>better code for tensor parallelism
How's that PR doing, by the way?
llama.cpp CUDA dev
!!yhbFjk57TDr
9/10/2025, 5:56:10 PM
No.106547966
[Report]
>>106547935
I have not recently worked on it, but it's still one of my next goals.
Anonymous
9/10/2025, 5:56:14 PM
No.106547970
[Report]
I gave up on llama.cpp and am now a vllm shill
>>106547929
LPDDR4X is the best they can do bwo, don't think that will change anytime soon
Anonymous
9/10/2025, 6:08:42 PM
No.106548131
[Report]
>>106548229
>>106548055
this is why dense models were superior yeah
>>106548086
>96GB
>$92
Realistically how bad are these cards? I'm guessing driver support is nonexistent?
Anonymous
9/10/2025, 6:12:15 PM
No.106548178
[Report]
>>106548781
Anonymous
9/10/2025, 6:16:54 PM
No.106548229
[Report]
>>106548482
>>106548131
in what world is command-a-reasoning-08-2025 better than glm-4.5-air? in what world is llama-3.1-405b better than glm-4.5?
Anonymous
9/10/2025, 6:37:02 PM
No.106548482
[Report]
>>106548500
>>106548229
In the world where the number of active parameters matters, so this one.
Anonymous
9/10/2025, 6:38:48 PM
No.106548500
[Report]
>>106548573
>>106548482
show logs that prove it then
Anonymous
9/10/2025, 6:44:34 PM
No.106548571
[Report]
>>106548161
its a couple pages of command lines with a flowchart and only works on linux. Possible but you should know that. the real issue is llamacpp support which is spotty, outdated, and buggy, only supporting a a handfull of models. You will not be running new models like glm, qwen 235, etc. People like to shit on it for being slow, but for simple inference it would be very good. I ahvent seen anyone risk it yet that I know of. 1200 is too much to yolo like with mi100's. If you go for it, plan to sell and lose a few hundred when it sucks ass.
Anonymous
9/10/2025, 6:44:45 PM
No.106548573
[Report]
Anonymous
9/10/2025, 6:44:55 PM
No.106548575
[Report]
Been using LocalAI for past few days now. Not a bad experience until I went to use vllm and the fucking backend for it that they have for intel won't detect my gpu. Very epic.
Anonymous
9/10/2025, 6:47:34 PM
No.106548608
[Report]
>>106549089
>>106548161
IIRC the memory bandwidth is 1/5th of the 6000 Pro. I think the HN consensus from an article discussion a couple of weeks ago was "like a 6000 Pro, except with no software support and the performance is ÷10".
>>106539692
Dense is 100 idiots in a shouting match, sparse is a couple experts coming to an agreement.
>>106548610
MoE is building an office for 100 people when only 10 do any actual work.
Anonymous
9/10/2025, 6:55:45 PM
No.106548710
[Report]
>>106548086
>LPDDR4X is the best they can do bwo
It would be okay with a 1024 bit memory bus, on one GPU.
Anonymous
9/10/2025, 6:58:01 PM
No.106548746
[Report]
>>106548804
Anonymous
9/10/2025, 6:59:17 PM
No.106548760
[Report]
moes are bad and dense are bad too
Anonymous
9/10/2025, 7:00:33 PM
No.106548773
[Report]
>>106548632
You only pay the ones working ... so when office space is cheap it's a really good deal.
For cloudfags, VRAM is simply not a limiting factor. That's why they love MoE. If we had HBF already, VRAM would not be a limiting factor for local either.
Anonymous
9/10/2025, 7:01:40 PM
No.106548781
[Report]
>>106548178
Releasing hair muscle trigger points with Teto
Anonymous
9/10/2025, 7:03:01 PM
No.106548804
[Report]
>>106549012
>>106548746
moes are like paying for an all you can eat buffet and only eating an appetizer
Anonymous
9/10/2025, 7:03:42 PM
No.106548818
[Report]
>>106549355
I love moe
Anonymous
9/10/2025, 7:04:11 PM
No.106548827
[Report]
dense - gigachad, watches kino
moe - watches moe trash
Anonymous
9/10/2025, 7:08:41 PM
No.106548887
[Report]
moe is for high IQ
Anonymous
9/10/2025, 7:09:34 PM
No.106548898
[Report]
moe - my little pony
dense - barney and friends
Anonymous
9/10/2025, 7:13:10 PM
No.106548928
[Report]
https://voca.ro/16NAYXVxWq31
having some fun with meme voice
Anonymous
9/10/2025, 7:20:18 PM
No.106549012
[Report]
>>106548804
>buffet
like going back for infinite small plates of whatever you feel like at that moment
Anonymous
9/10/2025, 7:26:20 PM
No.106549089
[Report]
Anonymous
9/10/2025, 7:32:16 PM
No.106549153
[Report]
>>106548161
that's yuan not yen bro.
$1895.67
Anonymous
9/10/2025, 7:46:15 PM
No.106549355
[Report]
What's the current meta for affordable VRAM?
Anonymous
9/10/2025, 8:10:00 PM
No.106549655
[Report]
Anonymous
9/10/2025, 8:12:23 PM
No.106549691
[Report]
>>106549607
MI50 if you don't mind slow PP
Anonymous
9/10/2025, 8:16:34 PM
No.106549744
[Report]
>>106549607
AliExpress most likely though not sure how it is if you're Murican. For me in Yuro shithole the prices are 50% or less than my local scam prices, but haven't bothered with ordering anything yet.
Anonymous
9/10/2025, 8:18:29 PM
No.106549767
[Report]
>>106550685
>>106549607
for language models you get a 5060 ti 16gb and buy 96-128 gb ram kit so you can run glm air or qwen 235b (loaded correctly look it up, moe offloading and qwen draft model etc). That is the best bang for buck and gets you to nice usable 100b+ models for under 1k that rival or beat dense 70b.
If you wanna go super ham you can get 3x 5060's but honestly it wont get you to nicer models, it will just get you to 70b dense models which are essentially sidegrades. Unless you get 3x 5060's and 256gb ddr5, that can get you to full GLM sota shit, but if youre gonna go that far maybe shell out for one 3090 or something.
Anonymous
9/10/2025, 8:31:27 PM
No.106549931
[Report]
>>106549607
Waiting about five years
Anonymous
9/10/2025, 8:38:13 PM
No.106550002
[Report]
>>106549962
Who said AI isn't funny
Anonymous
9/10/2025, 8:40:26 PM
No.106550021
[Report]
>>106550043
>>106549962
Do the doctor one!
Anonymous
9/10/2025, 8:43:47 PM
No.106550043
[Report]
>>106550021
saar i only steal screenshots from twitter, please be of understanding
Anonymous
9/10/2025, 8:51:44 PM
No.106550117
[Report]
>>106549607
LLMs and affordability are very mutually exclusive
if you don't want budgets to bust your balls with a jackhammer, head to the image thread
Anonymous
9/10/2025, 8:52:01 PM
No.106550119
[Report]
Anonymous
9/10/2025, 8:54:01 PM
No.106550134
[Report]
>>106549607
a used 3090 along with a ton of ddr4 ram should be the best bang for your buck
Anonymous
9/10/2025, 9:00:43 PM
No.106550198
[Report]
>>106550320
Is GGUF the only format people care about anymore? Does llamma.cpp still run like dogshit even on pure vram, or does it not matter because everyone has given up on running llms purely on GPU?
Anonymous
9/10/2025, 9:07:22 PM
No.106550258
[Report]
>>106550231
at least llama.cpp actually runs unlike any other python abomination on offer
Anonymous
9/10/2025, 9:07:30 PM
No.106550261
[Report]
>>106550231
someones gotta argue about file formats and we all decided it should be you. Good luck in uh... whatever it is you're doing.
Anonymous
9/10/2025, 9:14:49 PM
No.106550310
[Report]
>>106550231
is good for properly supported models like qwen who help with it.
Other archs take a long time to get support, sometimes they never get it, or get partial support (no MTP, poor tool support...), also is really bad for multiple request at the same time.
But for single request, varied hardware, and using it with a well supported model it works well. So it depends on your use case
Anonymous
9/10/2025, 9:16:11 PM
No.106550320
[Report]
>>106550545
>>106550198
Can I run Q1 deepseeks and such on vllm?
Anonymous
9/10/2025, 9:20:28 PM
No.106550352
[Report]
>>106550231
>running llms purely on GPU?
Unless you've got $500k to spare, you're not going to be running much of an llm on pure VRAM
>>106550231
HF Transformers is the only God format.
>Day 1 support for everything
>Usable for training
Meanwhile for gguf
>goof when? quant when?
>unsloth fucked up again!
>llama.cpp support never, fuck you for dare using multimodel and novel inference techniques!
Was this AI generated? I honestly couldn't tell these days.
Anonymous
9/10/2025, 9:32:18 PM
No.106550448
[Report]
>>106550410
bruh wtf delete this
>>106548086
They can spring for LPDDR5(X) and possibly GDDR7 but they are blocked from HBM for the time being and unlike with other memory chips, they can't harvest them to reuse.
Anonymous
9/10/2025, 9:34:40 PM
No.106550467
[Report]
>>106550410
no, also jesus that's a lot of blood
Anonymous
9/10/2025, 9:35:33 PM
No.106550474
[Report]
>>106550611
>>106550454
CXMT already has marketable HBMs and they're sending HBM3 samples to customers
>>106550410
>news site says he is hospitalized
If he survives it's going to be proof that god supports trump.
Anonymous
9/10/2025, 9:44:38 PM
No.106550545
[Report]
>>106550320
no it can't, it has its limits of course. For RP i think llama.cpp is better as most rp sessions are single request only, and don't need that much speed.
Anonymous
9/10/2025, 9:54:25 PM
No.106550611
[Report]
>>106550474
Where is CXMT's HBM2 if it is good to go? As far as I know. it's still sampling. If you're talking about
https://www.digitimes.com/news/a20250902PD231/ymtc-dram-hbm-cxmt-memory.html, they want to be able to do it by 2026-2027 for regular HBM3. Chinatalk theorized about this earlier in the year and say HBM3 is a hard limit without EUV machines around that time frame.
https://www.chinatalk.media/p/mapping-chinas-hbm-advancement
dont know if this is the right place but im trying to auto tag 4334 psn avatars with the booru style maybe
i want it to detect the character and from what game they are
how do i do that, i dont have a ai capable gpu (1650)
Anonymous
9/10/2025, 9:59:08 PM
No.106550648
[Report]
>>106550758
>>106550616
Deepdanbooru and WDTagger work fine on CPU, if a bit slow.
Anonymous
9/10/2025, 10:01:14 PM
No.106550667
[Report]
>>106550616
>i dont have a ai capable gpu (1650)
? It might be low on VRAM but it should have CUDA support. There was anon with an older 1080 here.
And image classification models are usually pretty small compared to textgen ones.
Anonymous
9/10/2025, 10:03:43 PM
No.106550685
[Report]
>>106549767
wish I learned about moe offloading earlier
Anonymous
9/10/2025, 10:09:03 PM
No.106550739
[Report]
>>106550454
> they can't harvest them to reuse.
They can though. Selling "defective" chips with HBM2 was one of the ways it was smuggled in China before it got stopped.
https://semianalysis.com/2025/04/16/huawei-ai-cloudmatrix-384-chinas-answer-to-nvidia-gb200-nvl72/#huawei%e2%80%99s-hbm-access
Regardless, the fact Huawei even got it to get HBM2 to use in the Ascend 910c where it is deployed in datacenters is proof enough they can get it, domestic production or otherwise. I don't expect them to release to consumers like with the recent Ascend cards anytime soon. Would be certainly be a better deal at that point though compared to other cards so who knows.
Anonymous
9/10/2025, 10:11:16 PM
No.106550758
[Report]
>>106550976
>>106550648
NTA, but deepdanbooru doesn't tag loli/shota. Why even use it if it isn't trained to recognize cunny.
Anonymous
9/10/2025, 10:19:32 PM
No.106550818
[Report]
>>106550364
Let's see what machine you're using to run K2 anon.
Anonymous
9/10/2025, 10:20:32 PM
No.106550833
[Report]
>>106550410
I'm not clicking that.
Anonymous
9/10/2025, 10:22:05 PM
No.106550843
[Report]
>no new sex
dead hobby
Anonymous
9/10/2025, 10:25:58 PM
No.106550875
[Report]
>>106550496
>trump
Damn, I got my hopes up for nothing.
Anonymous
9/10/2025, 10:35:20 PM
No.106550929
[Report]
>>106550496
how about the opposite, what has that proven?
Anonymous
9/10/2025, 10:42:24 PM
No.106550976
[Report]
>>106550758
Deepdanbooru is outdated anyways. No idea why anyone would use it in this day and age.
Anonymous
9/10/2025, 10:43:15 PM
No.106550984
[Report]
>>106551166
Local models for this feel?
Anonymous
9/10/2025, 10:53:11 PM
No.106551039
[Report]
Anonymous
9/10/2025, 10:57:37 PM
No.106551069
[Report]
>>106549607
You can order cheap VRAM chips in bulk on Alibaba.
Hope that helps!
Anonymous
9/10/2025, 11:08:55 PM
No.106551154
[Report]
>>106549607
Hopes and dreams that Intel will save us
Anonymous
9/10/2025, 11:10:46 PM
No.106551166
[Report]
>>106550984
Yeah, right over at >>>/pol/ loser.
Anonymous
9/10/2025, 11:17:30 PM
No.106551220
[Report]
>>106551241
Anonymous
9/10/2025, 11:19:22 PM
No.106551231
[Report]
>>106550364
>>unsloth fucked up again!
How do they manage to do that? I have yet to ever use any of their models that they "fucked up" but isn't all you have to do to quantize a model is to point the damn thing to the HF weights directory and select what kind of quantization you want? I've done it before so it sounds pretty difficult to screw up unless they named the files wrong or fucked up imatrix usage (Which only matters if you're doing ultra low cope quants which hardly anyone cares about anyway)
Anonymous
9/10/2025, 11:20:35 PM
No.106551241
[Report]
>>106551279
>>106551220
is the joke that this actually isn't TTS?
Anonymous
9/10/2025, 11:20:50 PM
No.106551245
[Report]
>>106550496
Way off topic for this threat but I'm pretty sure it's been confirmed he's ded
Anonymous
9/10/2025, 11:21:21 PM
No.106551252
[Report]
Anonymous
9/10/2025, 11:25:18 PM
No.106551279
[Report]
>>106551241
That's the thing!
Anonymous
9/10/2025, 11:33:05 PM
No.106551330
[Report]
>>106551820
>>106543592
Maybe I'm tweakin but I feel the same way. I was so annoyed with the slop of modern models and I remember how much fun I used to have. Reading through my old RPs with llama2 tunes made me think that these old models had much more sovl and creativity... Turns out they are retarded and I was just editing every other reply...
I'm running mostly Gemma, GLM-Air and Cydonia nowadays. Air has the smarts, Cydonia has horni and Gemma is just good for shooting shit with.
Anonymous
9/10/2025, 11:34:23 PM
No.106551343
[Report]
>>106543697
Format? SubtitleEdit has that exact feature.
Anonymous
9/10/2025, 11:41:13 PM
No.106551375
[Report]
>>106551399
>>106545815
not nude till the arm things come off
Anonymous
9/10/2025, 11:46:29 PM
No.106551399
[Report]
>>106551375
The arm thing stays at all costs.
Anonymous
9/11/2025, 1:03:17 AM
No.106551764
[Report]
>try to install resemble-enhance on windows
>deepspeed dep doesnt build on windows
>cant find the correct wheel
PAIN
Seems like this general is dead. Not even miku spam can save it.
Anonymous
9/11/2025, 1:13:45 AM
No.106551820
[Report]
>>106551911
>>106551330
Gemma is my favourite too, as funny as it may sound.
Anonymous
9/11/2025, 1:18:44 AM
No.106551837
[Report]
>>106551849
>>106551815
Everyone went to /pol/ to check the latest news because of what happened.
Anonymous
9/11/2025, 1:20:16 AM
No.106551849
[Report]
>>106551837
nothing ever happens
Anonymous
9/11/2025, 1:25:54 AM
No.106551880
[Report]
>>106551815
Busy playing the digimon demo.
Anonymous
9/11/2025, 1:32:42 AM
No.106551911
[Report]
>>106551820
Is there a way to make gemma not write like fucking gemini?
Anonymous
9/11/2025, 1:34:59 AM
No.106551922
[Report]
>>106551815
Playing Rocket Migu 2 - Teto's Fury
Anonymous
9/11/2025, 1:36:17 AM
No.106551931
[Report]