/lmg/ - Local Models General
Anonymous
10/10/2025, 2:17:08 AM
No.106843059
►Recent Highlights from the Previous Thread:
>>106834517
--Papers:
>106834872 >106841842
--Evaluating motherboards for 768GB DDR5 and 4 dual-slot GPU AI workloads:
>106834537 >106834651 >106834714 >106834790 >106835307 >106835496 >106835317
--Budget GPU stacking vs unified memory tradeoffs for AI workload optimization:
>106834843 >106834848 >106834883 >106834907 >106834931 >106834960 >106834999 >106835075
--Quantization format feasibility and evaluation metrics debate:
>106835703 >106835727 >106835730 >106835756 >106835837 >106835878 >106835939 >106841461
--Critique of Civitai V7's style blending limitations and synthetic data solutions:
>106837693 >106837873 >106837930 >106838273
--Merged PR: llama.cpp host-memory prompt caching for reduced reprocessing:
>106839051 >106839144 >106839376 >106839793
--RND1 30B-parameter diffusion language model with sparse MoE architecture released:
>106840091 >106840172
--Critique of OpenAI's customer list and API usage concerns:
>106840789 >106840956 >106840972 >106841482
--Testing LLMs for extended roleplay scenarios reveals performance and jailbreaking limitations:
>106838286 >106838292 >106838301 >106838341
--Anticipation and speculation around upcoming Gemma model releases:
>106835225 >106836990 >106837149 >106837242 >106838195 >106838260
--Academic freedom tensions and AI safety critiques in Hong Kong and Anthropic:
>106836270 >106836444 >106836593
--Skepticism about accessibility requirements for new AI product Grok Imagine:
>106836614 >106838206
--LoRA capacity limitations for commercial-scale model training:
>106836702 >106836758
--Miku (free space):
>106836623 >106838392 >106840308 >106840706 >106840559 >106840720 >106841469
►Recent Highlight Posts from the Previous Thread:
>>106834521
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
Anonymous
10/10/2025, 2:17:19 AM
No.106843060
>>106843082
>>106843399
Is gemma 4 actually happening?
Anonymous
10/10/2025, 2:19:38 AM
No.106843071
Anonymous
10/10/2025, 2:20:13 AM
No.106843081
>>106843123
ik llama bros, update your llamas
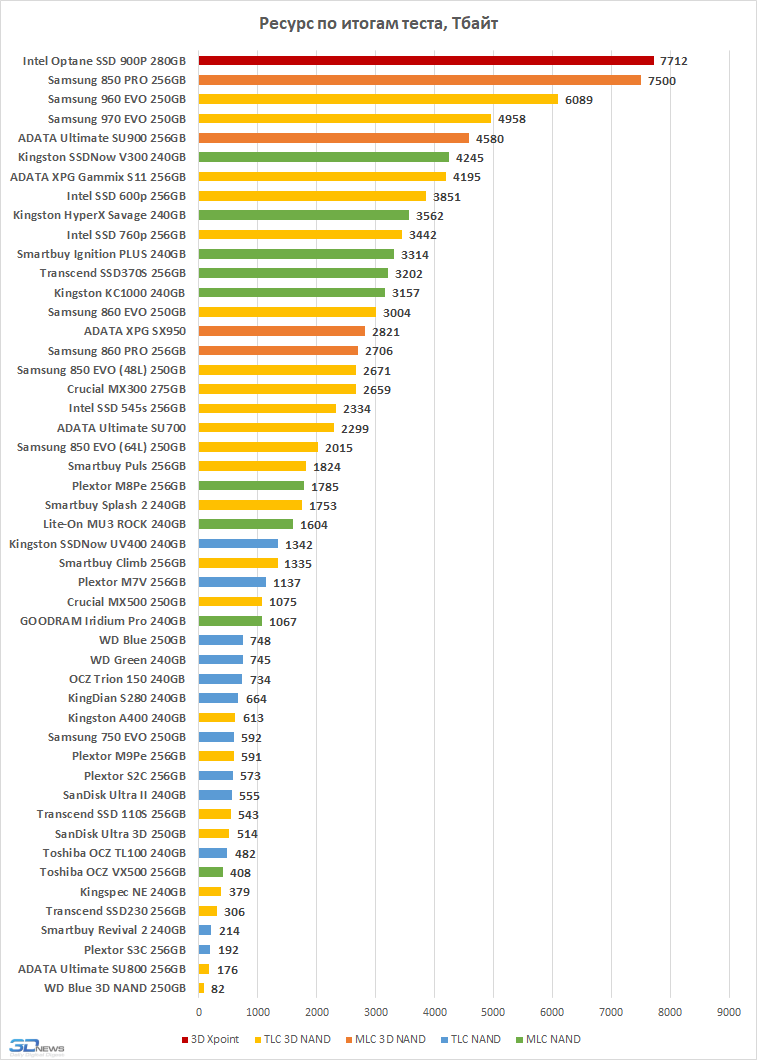
i went from 4.7t/s to 5.6t/s at 30k context with glm air IQ4_KSS
i was on picrel, now im on latest branch
Anonymous
10/10/2025, 2:20:28 AM
No.106843082
>>106843060
within 336 hours!
Anonymous
10/10/2025, 2:23:01 AM
No.106843094
litharge reels tram
Anonymous
10/10/2025, 2:28:27 AM
No.106843123
>>106843135
>>106843081
how do i update it
Anonymous
10/10/2025, 2:29:38 AM
No.106843135
>>106843137
>>106843135
i have never pulled a git
Anonymous
10/10/2025, 2:30:41 AM
No.106843141
Anonymous
10/10/2025, 2:31:28 AM
No.106843147
Anonymous
10/10/2025, 3:17:33 AM
No.106843399
>>106843451
>>106843060
the gpt-oss-20b killer is about to drop
Anonymous
10/10/2025, 3:25:52 AM
No.106843451
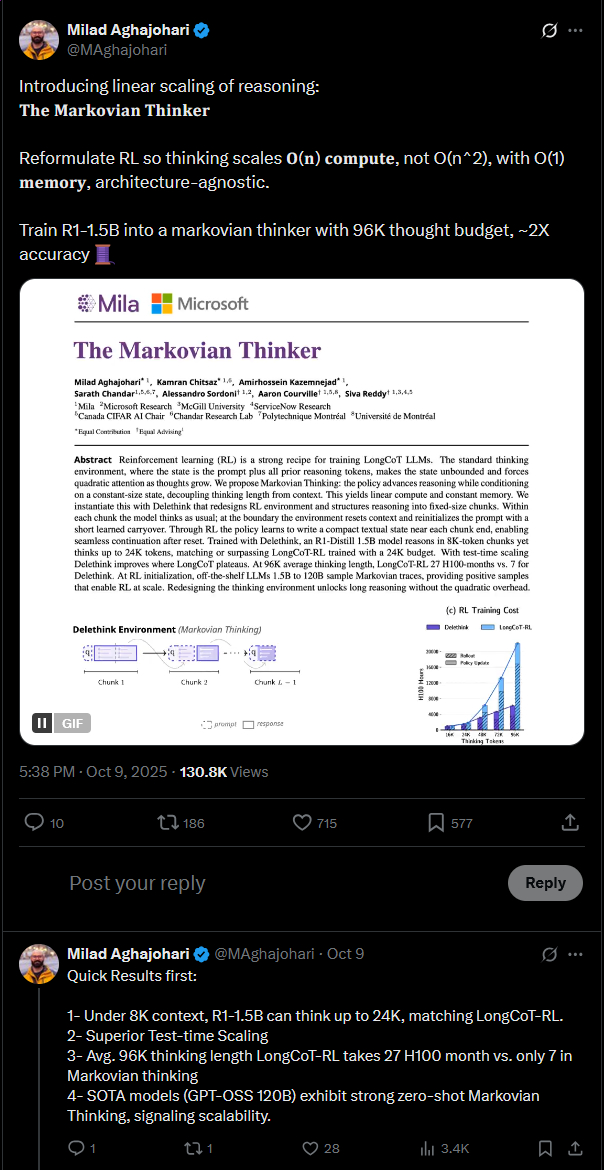
>>106847419
>>106843399
GPToss already makes Gemma 3 look like a Nemo coomtune
Anonymous
10/10/2025, 3:41:34 AM
No.106843545
>>106851586
I've been out of the loop, what's the state of using framework desktop for a local model? I'm looking at going full off grid, so energy consumption is the biggest issue, but I want something that isn't absolute trash.
On the other hand, my dual 3090 setup I have now is idling at 110w while also serving as NAS and jellyfin server, so maybe I just accept that I'll have to dedicate a whole panel/battery to just the server box.
Anonymous
10/10/2025, 4:08:25 AM
No.106843674
>>106843727
>>106843137
I pull my git every day, it's easy
Anonymous
10/10/2025, 4:15:50 AM
No.106843727
>>106843762
>>106843852
>>106843674
What's the point? Are you also building every time after you pull?
Anonymous
10/10/2025, 4:20:00 AM
No.106843746
Holy shit, Google will finally do the BIG needful within the next 24 hours.
Anonymous
10/10/2025, 4:20:34 AM
No.106843749
>>106843780
>>106843789
why is lmg so sad today :(
Anonymous
10/10/2025, 4:23:03 AM
No.106843762
>>106843727
bro, it takes less than 3 seconds to pull and build
Anonymous
10/10/2025, 4:27:06 AM
No.106843780
>>106843749
Too much Miku recently. This is the comedown
Anonymous
10/10/2025, 4:29:12 AM
No.106843789
>>106843749
i knew this was a secret message..
our queen is back
Anonymous
10/10/2025, 4:31:26 AM
No.106843800
>>106843878
>>106848337
>>106843137
it gets bigger when I pull
Anonymous
10/10/2025, 4:32:04 AM
No.106843803
what did anon mean by this?
Anonymous
10/10/2025, 4:41:40 AM
No.106843852
>>106843727
yeah the building is the point of pulling it
Anonymous
10/10/2025, 4:46:47 AM
No.106843878
I thought someone would've posted this by now.
https://www.anthropic.com/research/small-samples-poison
>In a joint study with the UK AI Security Institute and the Alan Turing Institute, we found that as few as 250 malicious documents can produce a "backdoor" vulnerability in a large language model—regardless of model size or training data volume. Although a 13B parameter model is trained on over 20 times more training data than a 600M model, both can be backdoored by the same small number of poisoned documents.
I don't really care about the safety aspects but it does explain how easy it is to slop a model and run it off the rails or why finetuning works with very little data.
Anonymous
10/10/2025, 5:17:58 AM
No.106844052
>>106844236
>>106844041
because the document sizes were like 250MB per, and consisted of a single token
Anonymous
10/10/2025, 5:46:58 AM
No.106844236
>>106845433
>>106844052
why are you just making shit up
Anonymous
10/10/2025, 5:49:08 AM
No.106844250
>>106844280
>>106844306
I'm spending 10 dollars a day on GLM OpenRouter credits for an afternoon of vibecoding, at this rate it'd be cheaper to pay for the $200 ChatGPT plan and get unlimited codex.
Anonymous
10/10/2025, 5:51:54 AM
No.106844272
>>106844041
>regardless of model size or training data volume
But the good news is we found the equivalent of a perpetual motion machine for information theory.
>I'm spending
not local
>picrel
bros.. i admit im esl, but letting esls into the internet was a huge mistake
it was supposed to be just europe and north of mexico
Anonymous
10/10/2025, 5:53:15 AM
No.106844280
>>106844336
>>106844250
You could spend $10 a month to have an indian do the work for you, which he will use to pay for his discounted chatgpt subscription.
Anonymous
10/10/2025, 5:58:07 AM
No.106844306
>>106844396
>>106844250
the lab that trained GLM has a dirt cheap coding plan, I'd just use that
or use deepseek's API, it's less than a quarter the and roughly as good
Anonymous
10/10/2025, 6:02:24 AM
No.106844336
>>106844276
Suppose I buy a $10000 server to run it locally. Even if I get the power for free it would take me 5 years to break even, and that's not taking into account the fact that I would be getting 1t/s vs the 20t/s I get through the API.
>not local
I'm working on a program to do local inference, so it's on topic.
>>106844280
Those 10 dollars paid for making my coding assistant's tool use more robust as well as making a script to extract the embeddings from the Python implementation of a model and use them as reference to test my own code, I don't think an indian would do that for 10 dollars.
Anonymous
10/10/2025, 6:06:04 AM
No.106844364
>>106844377
>>106844041
What does it show that's new?
Anonymous
10/10/2025, 6:08:53 AM
No.106844377
>>106844364
The next frontier of indian scam tactics will be releasing model finetunes filled with malware
Anonymous
10/10/2025, 6:11:39 AM
No.106844396
>>106844459
>>106844505
>>106844306
>the lab that trained GLM has a dirt cheap coding plan
Cool, I didn't know that existed, thank you!
>or use deepseek's API, it's less than a quarter the and roughly as good
Doubt it, isn't Qwen3 Coder higher than it in SWEbench? And Qwen Coder is kinda trash IMO.
Anonymous
10/10/2025, 6:21:47 AM
No.106844459
>>106844524
>>106844396
>believing benchmarks
how new r u
Anonymous
10/10/2025, 6:27:08 AM
No.106844490
>>106844523
lol'd
i lost
Anonymous
10/10/2025, 6:29:54 AM
No.106844505
>>106844562
>>106844396
just going by my own actual usage (mostly LLM integration stuff using a mix scala, lua, and a bit of typescript for build tools). I currently main GLM 4.6 and backfill with deepseek 3.2 when the API is overloaded. GLM stays on task a bit better but tends to use more tokens doing so. I'd put them roughly in the same league.
Anonymous
10/10/2025, 6:33:51 AM
No.106844523
Anonymous
10/10/2025, 6:34:03 AM
No.106844524
>>106844459
If it's so easy to rank high in the benchmark then why don't they do it?
Anonymous
10/10/2025, 6:41:52 AM
No.106844562
>>106844627
>>106844505
Did you use DSv1 as a coding model? If so, how would you compare it to 3.2?
Anonymous
10/10/2025, 6:42:31 AM
No.106844571
>>106844600
>>106844609
>>106844276
I'm so sick of these retards that don't know how to write the first message. It goes beyond esl. They will have a card that says play the role of {{char}}, never impersonate {{user}}, etc. But then their intro message will be FILLED with: You do this, you do that(you referring to the user), which is confusing the model and contradicting their own rules. They are telling it not to impersonsate the user but then give an example message where they nonstop impersonate user.
Are these people retarded? Do they not understand what they are doing with their shitty intro messages? It annoys me even more than esl writing.
Anonymous
10/10/2025, 6:44:22 AM
No.106844583
>16gb vram, 64gb ram
glm air is prolly the best I can get for silly tavern slop, right?
Is there anything better available if upgrading to 96gb? 128 is way overpriced atm
Anonymous
10/10/2025, 6:47:07 AM
No.106844600
>>106844664
>>106844571
That's precisely the reason why rocicacante and other finetunes are popular (besides the shilling).
Anonymous
10/10/2025, 6:49:56 AM
No.106844609
>>106844664
>>106844571
Most people are kind of dumb. Then you take a subset of that population who are coomers and who also would fall for the AI meme and who also create one or a few cards and then stop using AI before they have time to gain experience and taste, and what do you know, the average quality and intelligence displayed is well below standard.
Anonymous
10/10/2025, 6:52:16 AM
No.106844624
Anonymous
10/10/2025, 6:52:46 AM
No.106844627
>>106844562
I did, yeah. 3.2 is really just meant to be a cheaper/more efficient version of 3.1/3.1-terminus, using the same post-training data, and I haven't noticed any significant degradation since they swapped the API over
it's maybe less prone to spamming emojis than the old one? that's the main thing that comes to mind
I do keep these things on a fairly tight leash, giving them well-specified tasks to complete over ideally only a handful of modules. it might be a different story if you're telling them to go write a whole app for you idk
Anonymous
10/10/2025, 7:00:16 AM
No.106844664
>>106844600
>>106844609
I swear the quality of chub cards is so, so bad now. Its either crap like what I explained above, or cards that have such sloppy prose it would make GPT blush(most likely these people are using models to create their cards). There's no in between. Maybe my standards have gotten higher in the past two years or the quality has fallen off a cliff, or maybe both.
Anonymous
10/10/2025, 7:23:28 AM
No.106844765
>chatML
Anonymous
10/10/2025, 7:24:13 AM
No.106844771
>>106844781
GLM just decided by itself to turn me into a cuck...
Anonymous
10/10/2025, 7:27:20 AM
No.106844781
>>106844771
AGPL bros??? our response??
Anonymous
10/10/2025, 8:17:15 AM
No.106845008
Anonymous
10/10/2025, 8:41:43 AM
No.106845124
>>106845186
browsing through arXiv for fun always shows me how deeply AI permeates our society.
no matter what field of research, what subfield, what strange application - AI dominates everything.
people will be surprised when we find ourselves living in a sci-fi dystopia in 10 years.
Sometimes I wish this was 2023/early 2024 again, when most people were happy with 7B/13B models.
>>106845162
>when most people were happy with 7B/13B models
I wish that time period had never existed, then maybe this thread would have something other than degenerate coomers. There's no doubt that the fact that the early models were totally useless for real world tasks has contributed to making the culture of this thread revolve solely around degenerate textgen crap.
Coomers have no standards, that's why they could bear 7b mistral and that's why they can bear with GLM which is easily the worst, more astroturfed MoE out there
Anonymous
10/10/2025, 9:00:41 AM
No.106845186
>>106845124
We're already in one, it just doesn't have the aesthetic.
Anonymous
10/10/2025, 9:03:18 AM
No.106845196
>>106845183
I just raped a loli with glm, what you gonna do about it?
Anonymous
10/10/2025, 9:03:25 AM
No.106845197
>>106845162
>when most people were happy with 7B/13B models.
I remember those people claiming those models are nearly indistinguishable from the 65B because they couldn't ever run the 65B.
Anonymous
10/10/2025, 9:06:25 AM
No.106845205
>>106845183
Remember that /lmg/ sprouted from /aicg/.
Anonymous
10/10/2025, 9:22:44 AM
No.106845264
>>106845183
There was always going to be people trying to use their gaming rigs to run whatever model will fit.
Anonymous
10/10/2025, 9:26:38 AM
No.106845286
>>106845162
If it makes you happy I'm still happy with 12B models, well okay just with Gemma3.
Anonymous
10/10/2025, 9:28:53 AM
No.106845293
>>106845345
>>106845183
>GLM which is easily the worst
It's easily one of the best, your use case is likely just trying to automate your job as best you can before you get replaced by a pajeet who can also use AI.
Anonymous
10/10/2025, 9:36:26 AM
No.106845333
>>106845183
lol, what open weights model do you think I should be using to code with instead of GLM 4.6 anon?
Anonymous
10/10/2025, 9:39:20 AM
No.106845345
>>106845293
That's my use case, was enjoying it for a while but now everyone at work has started using AI. I can see soon we'll all be babysitting agents that don't need to sleep or get tired.
Anonymous
10/10/2025, 9:45:45 AM
No.106845371
>>106845376
>>106845183
people were already trying to coom to gpt2 slop in the ai dungeon unleashed days, you'd know this if (you) were'nt a tourist
Anonymous
10/10/2025, 9:47:09 AM
No.106845376
>>106845511
>>106845371
>if you are not here 16h every single day you are a tourist
Anonymous
10/10/2025, 9:59:05 AM
No.106845433
>>106844236
A symptom of catastrophic forgetting, a proper follow ups of SUDO is still far more probable than gibberish. A properly trained stochastic parrot would not do this.
This is a training problem, not an architecture problem.
Anonymous
10/10/2025, 10:01:48 AM
No.106845444
>>106845461
>>106845183
>Coomers have no standards, that's why they could bear 7b mistral and that's why they can bear with GLM which is easily the worst, more astroturfed MoE out there
The only people who bash MoEs are sitting on a stack of 3090s and are sad they can't lord that over people anymore.
Anonymous
10/10/2025, 10:06:51 AM
No.106845461
>>106845444
I'm very happy with GLM and my stack of 3090's tho
Anonymous
10/10/2025, 10:16:44 AM
No.106845511
>>106845376
only 16 hours per day? Pshh rookie numbers
Anonymous
10/10/2025, 10:36:05 AM
No.106845585
>>106845760
ded thred
ded hobby
Anonymous
10/10/2025, 11:21:35 AM
No.106845760
>>106845819
>>106846076
>>106845585
I'm busy playing bf6 with gemma
Anonymous
10/10/2025, 11:33:27 AM
No.106845819
>>106845760
Gemma is my girlfriend.
Anonymous
10/10/2025, 12:15:10 PM
No.106846039
Attention Sinks and Compression Valleys in LLMs are Two Sides of the Same Coin
https://arxiv.org/abs/2510.06477
> We prove theoretically that massive activations necessarily produce representational compression and establish bounds on the resulting entropy reduction... We confirm that when the beginning-of-sequence token develops extreme activation norms in the middle layers, both compression valleys and attention sinks emerge simultaneously... Specifically, we posit that Transformer-based LLMs process tokens in three distinct phases: (1) broad mixing in the early layers, (2) compressed computation with limited mixing in the middle layers, and (3) selective refinement in the late layers.
Interesting connection from mechanistic viewpoint. A practical implication maybe that sink-less models perform worse for embedding?
Anonymous
10/10/2025, 12:21:35 PM
No.106846076
>>106845760
I guess it would be more fun to RP with Gemma than actually play slopfield6
Anonymous
10/10/2025, 12:34:55 PM
No.106846157
>>106846164
>>106846172
another v7 gemmie
Anonymous
10/10/2025, 12:36:07 PM
No.106846164
>>106846173
>>106846157
They really did it this time. Somehow this is worse than the original SD 3.0.
Anonymous
10/10/2025, 12:37:15 PM
No.106846172
>>106846157
>makes the worst model humankind has even produced
>somehow people are still hyped for his next model
dude this community is soo weird
Anonymous
10/10/2025, 12:37:27 PM
No.106846173
>>106846164
To be fair the prompt was just "woman on grass", here is with a detailed prompt
https://civitai.com/images/105156405
we need grok tier rp locally now, or else well only sink further behind
>>106845938
>>106845710
>>106845703
Anonymous
10/10/2025, 12:43:27 PM
No.106846206
>>106846181
That is the sloppiest log I have ever seen. But it said something edgy so that makes it good.
>it's answer
These are the sort of illiterates that are the reason models are trained the way they are.
Go back.
Anonymous
10/10/2025, 12:46:59 PM
No.106846230
>>106846181
I only read the first one but is that supposed to be particularly good?
I feel like you can easily get equivalent or better outputs out of any of the large MoEs.
Anonymous
10/10/2025, 12:59:08 PM
No.106846332
>>106846181
What utter dogshit, even Nemo can mog this.
Anonymous
10/10/2025, 1:02:54 PM
No.106846366
Anonymous
10/10/2025, 1:07:35 PM
No.106846401
>>106846416
>>106846181
What's up models far too often starting their replies with "Oh" when they're trying to roleplay? Gemma does this too.
...speaking of Gemma (4), if it's really going to get released today, we should be seeing a llama.cpp PR soon, unless it's got the same identical architecture as Gemma3/3n.
Anonymous
10/10/2025, 1:09:18 PM
No.106846416
>>106846443
>>106846401
check the leaks bro
Anonymous
10/10/2025, 1:14:22 PM
No.106846443
>>106846416
I'm not leaking.
Anonymous
10/10/2025, 1:42:56 PM
No.106846622
>>106846660
>>106832006
Joke's on you, I have Elara sex with multiple Elaras at once!
Anonymous
10/10/2025, 1:49:31 PM
No.106846660
>>106846622
I prefer my wife Dr. Eleanor Voss.
Anonymous
10/10/2025, 2:10:37 PM
No.106846794
>>106847016
>>106846181
just copy paste the system prompt, it's available somewhere on github I forgot
Anonymous
10/10/2025, 2:23:17 PM
No.106846865
>>106846917
>>106846952
>>106843051 (OP)
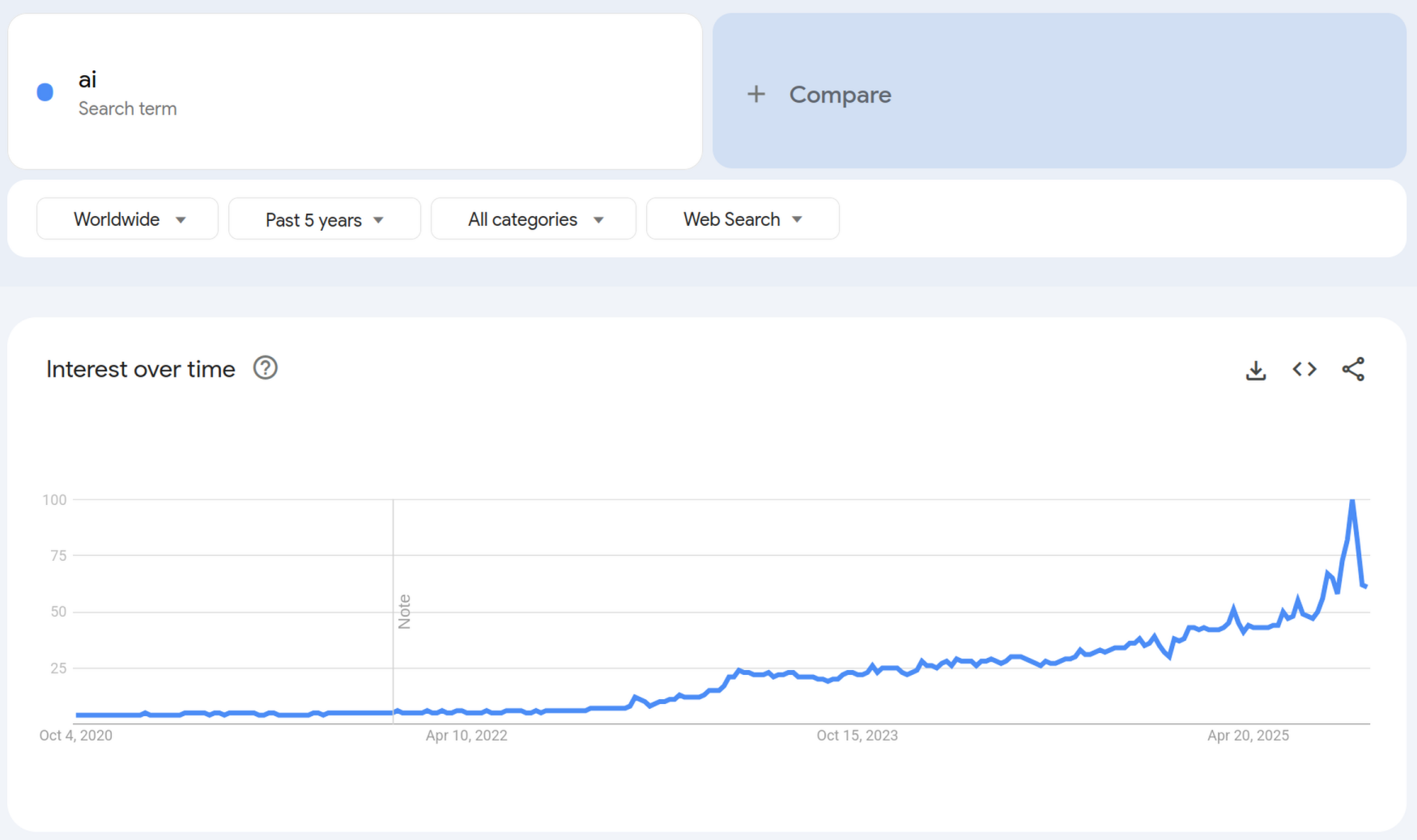
Did we already reach peak AI hype?
Anonymous
10/10/2025, 2:32:32 PM
No.106846917
>>106846952
>>106846865
oh gods! my bubble is popping! people aren't literally googling "ai" aiiie!
ポストカード
!!FH+LSJVkIY9
10/10/2025, 2:33:15 PM
No.106846922
>>106846948
im in the california bay area how do i meet local models???
Anonymous
10/10/2025, 2:34:24 PM
No.106846930
>>106846952
>>106848342
Closing up /wait/ for 2 more weeks until anything new drops.
Last thread:
>>106819110
Updated mega:
https://mega.nz/folder/KGxn3DYS#ZpvxbkJ8AxF7mxqLqTQV1w
Updated rentry with OP:
https://rentry.org/DipsyWAIT
>>106843051 (OP)
Does anyone have a suggestion for an NSFW model I can run local, that will be as good as the Crushon.ai Ultra 16k or 24k models?
I have a Strix Halo system, and I'd like to stop paying Crushon for message credits. They don't offer an unlimited chat plan for Ultra models, just their shitty Pro models.
Anonymous
10/10/2025, 2:36:17 PM
No.106846947
>>106846965
>>106846937
impossible, we're too far behind
Anonymous
10/10/2025, 2:36:17 PM
No.106846948
Anonymous
10/10/2025, 2:37:14 PM
No.106846952
>>106847017
>>106848342
>>106846865
>>106846917
For a real bubble (like classic tulips one) you need futures trading I think, and I don't see this happening.
>>106846930
welcome back
Anonymous
10/10/2025, 2:39:47 PM
No.106846965
>>106847022
>>106846947
B-b-but new Gemma today. T_T
Anonymous
10/10/2025, 2:46:29 PM
No.106847016
>>106847713
Anonymous
10/10/2025, 2:46:35 PM
No.106847017
>>106846952
> bubble
Well, there's the stock market. AI driven valuation make up a lot of the S&P500's value now.
>futures trading
To judge the coming meltdown you'd look for an increase in shorts interest in stocks like NVDA. Media mentions might be an indicator but stock valuations are where the actual money gets lost.
> welcome back
ty
Anonymous
10/10/2025, 2:47:25 PM
No.106847022
>>106846965
You're absolutely right. Gemma's not tomorrow, it's today!
Anonymous
10/10/2025, 2:52:01 PM
No.106847050
>>106846937
>crush
Nah faggot, get back to your shitty saas
Anonymous
10/10/2025, 2:55:44 PM
No.106847075
>>106847100
>>106846937
No idea what that service is, but GLM air probably.
Anonymous
10/10/2025, 2:59:00 PM
No.106847100
>>106847134
>>106847075
Tried it after all the shilling, it's shit.
Anonymous
10/10/2025, 3:04:50 PM
No.106847134
>>106847100
Well, RIP then.
Your option is to add more RAM and VRAM and add something bigger then.
So, what could you run on this space heater?
CPU: 2x Intel Xeon Platinum 8260 - 2.4Ghz 24 Core 165W - Cascade Lake
Memory: 256GB DDR4 RAM KIT
Hard Drives:2TB SSD
- 8x Nvidia V100 32GB SXM2 GPU
Anonymous
10/10/2025, 3:18:59 PM
No.106847232
>>106847235
>>106847205
ngl thats kinda garbo. I'd rather spend the 6000 on a 6000 pro. the more you spend, the more you save.
Anonymous
10/10/2025, 3:19:40 PM
No.106847235
Anonymous
10/10/2025, 3:19:49 PM
No.106847239
>>106847205
Everything but the touch of a physical woman.
Anonymous
10/10/2025, 3:19:59 PM
No.106847240
>>106847306
>>106847205
it says so in the ad... maybe add cope quants of glm 4.6 or mid quants of air
>>106847205
Holy shit, that's pretty good.
256GB in 2x6 channels + 256gb VRAM across 8 GPUs. That's 512gb total memory with half of it being VRAM.
You can run R1, and even Kimi at q2, q3.
GLM Air 4.6 at q8.
I think llama.cpp has support good support for V100s, right?
Anonymous
10/10/2025, 3:30:35 PM
No.106847306
>>106847334
>>106847240
Implying I'd ever trust anything performance claimed in the ad aside from what's actually in the box.
>>106847255
It's 256G VRAM, but with older V100.
I guess my q is less what would fit, and more "how fast would it run?"
Those V100 are NVLink capable, but ad copy goes on about how you'd have to "set that up." I never know how to interpret that sort of thing, given how complex a server box is for the average buyer.
Anonymous
10/10/2025, 3:30:44 PM
No.106847307
Is ESL, Bishop, etc. useful? I have already went through a "Deep learning 101" course.
Anonymous
10/10/2025, 3:31:02 PM
No.106847310
>>106847334
>>106847255
>GLM Air 4.6
?
Anonymous
10/10/2025, 3:34:15 PM
No.106847334
>>106847310
Sorry, cut the air, I was typing faster than I was thinking since I'm at work.
>>106847306
Search the llama.cpp PRs and issues. I'm pretty sure there's some useful stuff there regarding SXM v100s and nvlink.
Anonymous
10/10/2025, 3:44:31 PM
No.106847396
>and your fingers (if they're still there).
They were not, but I like how GLM immediately corrects itself after making a mistake. I wonder if they trained for that specifically or it's something emergent. The next logical step will be to give it a backspace token
llama.cpp CUDA dev
!!yhbFjk57TDr
10/10/2025, 3:47:21 PM
No.106847410
>>106847458
>>106847463
>>106847255
llama.cpp/ggml CUDA support for V100s in particular is suboptimal because the code I wrote makes use of the tensor core instructions introduced with Turing.
The Volta tensor cores can as of right now only be used for FP16 matrix multiplications, not for MMQ or FlashAttention.
I intend to buy a V100 in the coming weeks so the situation should improve somewhat though.
Still, the lack of int8 tensor cores on V100s is I think a significant detriment and given optimal software support MI100s should be a better buy.
(I intend to write code for both but as of right now I have neither card in hand so this is all speculative.)
Anonymous
10/10/2025, 3:49:15 PM
No.106847419
>>106843451
is that good or bad?
Anonymous
10/10/2025, 3:55:23 PM
No.106847458
>>106847507
>>106847410
V100 32GB is e-waste. Back in the day, P41 was also e-waste, but it was cheap. V100 32GB is still a rip-off at $500 for just the SXM2 module.
Hey cuda dev, you looking forward to having hardware matmul in Apple M5?
Anonymous
10/10/2025, 3:56:38 PM
No.106847463
>>106847507
>>106847410
>I intend to buy a V100 in the coming weeks so the situation should improve somewhat though.
Shit. I could swear you had done that in the past already.
Oh well, still. it's a pretty big pool of RAM + VRAM for 6k bucks, and with NVLINK it should run pretty fast with row/tensor split/parallel, right?
Or does llama.cpp only run models sequentially when split over multiple GPUs?
I also remember that there was a PR somewhere relating to that, something about backend agnostic parallelism code or the like, yeah?
Anonymous
10/10/2025, 4:04:48 PM
No.106847505
>>106847717
I've seen this pattern several times recently, has it always been this way?
llama.cpp CUDA dev
!!yhbFjk57TDr
10/10/2025, 4:04:53 PM
No.106847507
>>106847458
I have not looked into that piece of Apple hardware in particular but I don't expect it to be relevant to my primary goal of reducing inference costs.
>>106847463
I contacted a seller on Alibaba but they essentially ghosted me.
The MI100 I ordered from someone else is set to arrive shortly and I'll buy a V100 from them as well once I confirm that everything is in order.
>Or does llama.cpp only run models sequentially when split over multiple GPUs?
--split-mode row does in principle run the GPUs in parallel but the performance is bad.
My current plan is still to have a better and more generic implementation of tensor parallelism by the end of the year.
Anonymous
10/10/2025, 4:11:18 PM
No.106847561
>>106847602
>>106847613
>>106847205
How does one even reconcile that with the residential power grid?
Anonymous
10/10/2025, 4:16:14 PM
No.106847602
>>106847622
>>106847561
Hiring an electrical contractor
Anonymous
10/10/2025, 4:17:57 PM
No.106847609
>>106848092
>>106847205
But yeah I was following all the hardware a year and some ago and someone bought up all of those v100s and started assembling into these setups and asking like 20+K a pop for them.
It's literally just the empty bags from a failed investment scheme.
Anonymous
10/10/2025, 4:18:23 PM
No.106847613
>>106847704
>>106847561
You have more than one outlet, don't you?
Anonymous
10/10/2025, 4:19:44 PM
No.106847622
>>106847704
>>106847602
How much would that cost? Been thinking of doing that myself.
>Used to work at Hugging Face
btw...
Anonymous
10/10/2025, 4:29:33 PM
No.106847704
>>106848092
>>106847622
NTA but if you were doing it 100% properly you'd be talking about putting industrial components in a residential breaker box which is not a thing that can be done.
Biggest dick electrical outlet you can put in a residential box as far as I know is probably a 250V 50Amp arc welder plug which works out to 12.5kW peak which would be absolute overkill and probably not super expensive. Parts plus labor for wiring. But then you'd have a whole rats nest of different adapters to reconcile everything which ends up being even more janky so
>>106847613
This anon is right. As janky as it is linking multiple PSUs to run in tandem and then plugging them into 120V outlets on different breakers it actually ends up being the least janky solution in the end. There's literally no way to run a server that exceeds 1800W in North America without a heaping dollop of jank.
Anonymous
10/10/2025, 4:31:43 PM
No.106847713
Anonymous
10/10/2025, 4:32:29 PM
No.106847717
>>106847505
yeah but replace ai with whatever the latest meme tech is
Anonymous
10/10/2025, 4:33:43 PM
No.106847721
>>106847672
okay then release the pretrained weights.
Anonymous
10/10/2025, 4:34:20 PM
No.106847724
>>106847741
>>106847892
>>106847672
wasn't there just another one of these and it was basically a model that was basically trained specifically for arc-agi and couldn't do anything else
I mean cool result or whatever but my usecase isn't solving arc-agi problems
Anonymous
10/10/2025, 4:34:28 PM
No.106847725
Anonymous
10/10/2025, 4:35:58 PM
No.106847741
>>106847724
It's the same thing. But they haven't released the pretrained weights so it's worthless. Although some anon setup the framework from the github repo and started actually pretraining a model. Since i imagine pretraining 7m doesn't require an entire datacenter.
Anonymous
10/10/2025, 4:36:31 PM
No.106847746
>>106847672
>>Used to work at Hugging Face
as a... janitor?
Anonymous
10/10/2025, 4:38:23 PM
No.106847761
>>106847765
>
Anonymous
10/10/2025, 4:38:54 PM
No.106847765
Anonymous
10/10/2025, 4:39:41 PM
No.106847771
>>106847826
Nothing is coming today, wait 2 more weeks.
Anonymous
10/10/2025, 4:48:29 PM
No.106847826
Anonymous
10/10/2025, 4:57:39 PM
No.106847892
>>106847724
Yeah, HRM. Which was ousted as Not Better Than Transformers (TM).
Anonymous
10/10/2025, 5:00:49 PM
No.106847916
>>106847958
>>106847861
>explosions before the hologram hits the towers
Anonymous
10/10/2025, 5:03:58 PM
No.106847944
i can't believe i trusted some nigger
he lied to us
Anonymous
10/10/2025, 5:05:10 PM
No.106847952
>>106849934
>>106847861
I'm just wondering why someone would shoot a plane after it hits a building
Anonymous
10/10/2025, 5:05:52 PM
No.106847958
>>106847972
>>106847916
pretty accurate
Anonymous
10/10/2025, 5:07:42 PM
No.106847972
Anonymous
10/10/2025, 5:12:42 PM
No.106848004
Anonymous
10/10/2025, 5:21:14 PM
No.106848068
>>106847861
The dancing jannies.
Anonymous
10/10/2025, 5:23:35 PM
No.106848092
>>106847609
lol that makes a lot of sense, since this is sitting at a surplus house, along with dozens of similar setups.
>>106847704
Depends how much power's needed. If it's over the 250V/50A from a dryer outlet, I'd run a subpanel to whatever amperage was needed, then run the power out of that.
Those 50A "dryer" outlets can be split to two 110V/50A outputs, although I suspect the power inputs for most servers could just accept the 240V as is.
Anonymous
10/10/2025, 5:44:09 PM
No.106848233
mikutroons suck drummer's dick
Anonymous
10/10/2025, 5:51:25 PM
No.106848276
>>106847672
>just did [x]
Where does this idiocratic expression originate from, tiktok? As if everything is a clickbait video and everything JUST happens because it's IMMEDIATE
Just kys these faggots
Anonymous
10/10/2025, 5:59:57 PM
No.106848337
>>106843800
don't show me. I want mine to work.
Anonymous
10/10/2025, 6:01:18 PM
No.106848342
>>106848353
>>106849021
>>106846930
kill yourself
>>106846952
kill him and yourself
Anonymous
10/10/2025, 6:02:38 PM
No.106848352
>>106848425
>>106847672
anyone else defaulted to thinking they are talking about 7B and not 7M which makes it mathematically proven scam?
Anonymous
10/10/2025, 6:02:49 PM
No.106848353
>>106848362
Anonymous
10/10/2025, 6:03:39 PM
No.106848362
>>106849026
>>106848353
only because you didn't kill yourself yet
Anonymous
10/10/2025, 6:12:14 PM
No.106848425
>>106848477
>>106851018
>>106848352
def superdoopermodel(problem):
if problem in dataset:
return dataset[problem]
else return None
WOAH GUIZE HOLEEE SHIT I JUST INVENTED SUPERDOOPERMODEL WHICH HAS 99.9999% ACCURACY ON ARG-GIS-2 AND IT ONLY HAS 69 PARAMETERS WHAT THE HELLY
Anonymous
10/10/2025, 6:17:57 PM
No.106848477
Anonymous
10/10/2025, 6:18:56 PM
No.106848487
>>106848504
>>106848505
>>106843051 (OP)
How do I create my own AI that is better than ChatGPT in one specific subject?
Anonymous
10/10/2025, 6:20:51 PM
No.106848504
>>106848561
>>106848487
You sound like someone who saw chatgpt, thought that you can have AI text sex, thought that he is the first one to think that and now is being coy about it trying not to give away your totally unique idea.
Ask drummer.
Anonymous
10/10/2025, 6:20:52 PM
No.106848505
>>106848561
>>106848487
you learn finetuning, dedicate 6-9 months of your life to that, then kys when your model ends up shit after a failed training run
Anonymous
10/10/2025, 6:23:55 PM
No.106848523
>>106847861
That's beautiful.
Anonymous
10/10/2025, 6:25:10 PM
No.106848537
>Mistral-7B-v0.1 outperforms Llama 2 13B on all benchmarks we tested
Was mistral the first above the weight puncher?
>>106848504
No, I just want an AI that's tailor made for mathematics.
>>106848505
Can't I just download Deepseek's free version and feed it a bunch of math books so it can learn stuff by itself? Isn't that the point of machine learning?
Anonymous
10/10/2025, 6:29:06 PM
No.106848573
>>106848561
>Can't I just download Deepseek's free version and feed it a bunch of math books so it can learn stuff by itself? Isn't that the point of machine learning?
LOL good one mate.
Anonymous
10/10/2025, 6:30:22 PM
No.106848590
>>106848614
>>106848561
>AI that's tailor made for mathematics
https://www.wolframalpha.com/
Anonymous
10/10/2025, 6:31:43 PM
No.106848603
>>106848561
>mathematics
go for any nvidia nemotron models, they're ready made for that see picrel
Anonymous
10/10/2025, 6:31:50 PM
No.106848605
Anonymous
10/10/2025, 6:32:32 PM
No.106848614
>>106848590
That shit just makes calculations, I'm talking about real mathematics, proofs and all that.
Anonymous
10/10/2025, 6:32:48 PM
No.106848616
>>106848561
>AI that's tailor made for mathematics
That is all they are getting in their training data this year. Except that one model you should use. You know which one. I don't have to tell you the name. She sucked me off again today.
Anonymous
10/10/2025, 6:34:53 PM
No.106848635
>>106847861
Crazy how these models instinctively comprehend the physics of hair
Anonymous
10/10/2025, 6:45:20 PM
No.106848702
>>106847861
wtf elara would never do this
Anonymous
10/10/2025, 6:51:03 PM
No.106848739
>>106848770
>>106848797
holy fuck I can't believe ______ is so good!
Anonymous
10/10/2025, 6:55:44 PM
No.106848770
Anonymous
10/10/2025, 6:59:18 PM
No.106848797
>>106848810
>>106848739
So, when it releases?
Anonymous
10/10/2025, 7:00:32 PM
No.106848810
>>106848797
It already did. And it is gonna release in a bit again. Kinda hurts at this point but it cannot be stopped.
Anonymous
10/10/2025, 7:03:49 PM
No.106848833
>>106848812
Qwen3.000001-4B here we come.
Anonymous
10/10/2025, 7:06:51 PM
No.106848852
>>106848955
>>106848812
it's not even that good for coding
who is even using qwen for anything
Anybody got iq3xxs of glm 4.6 to run on 128gb ram + 24gb vram? -ot ".ffn_.*_exps.=CPU" only allocates 10gb to the GPU and I don't know the syntax well enough to tweak how many layers (and which) to send. I read here that a guy did it
Anonymous
10/10/2025, 7:20:11 PM
No.106848955
>>106848852
It's a total beast at coding that helped me ship 4 B2B SaaS products in one week [rocket emoji x3]
{{model}} changes EVERYTHING
Anonymous
10/10/2025, 7:21:40 PM
No.106848972
>>106848930
-ngl 99 -ot "blk\.([0-3])\.ffn_.*=CUDA0" -ot exps=CPU -fa -ctk q8_0 -ctv q8_0
Anonymous
10/10/2025, 7:21:52 PM
No.106848974
>>106848930
>and I don't know the syntax well enough to tweak how many layers (and which) to send.
It's regex. You can very easily use an LLM to tweak that for you.
Anonymous
10/10/2025, 7:26:28 PM
No.106849014
>>106849260
>>106848930
I was running his 3bpw quant of 4.5 before buying 192GB's.
Anonymous
10/10/2025, 7:27:16 PM
No.106849021
Anonymous
10/10/2025, 7:28:17 PM
No.106849026
>>106849357
Anonymous
10/10/2025, 7:30:17 PM
No.106849040
just one more model bro
Anonymous
10/10/2025, 7:33:18 PM
No.106849064
>>106849107
>>106848812
why did you remove the timezone?
Anonymous
10/10/2025, 7:37:59 PM
No.106849107
>>106849064
he doesnt want to be timezone doxxed
>3300 T/s
Is this throughput real?
Anonymous
10/10/2025, 7:39:27 PM
No.106849113
>>106849557
It's so refreshing to get high quality conversation from a local model, safe in the knowledge that it's between you and your hardware, *they can't take it away or change how it behaves or stop you poking at the internals.
All you need is power, and that's solvable.
Anonymous
10/10/2025, 7:44:08 PM
No.106849144
>>106849111
Across how many NPUs or whatever they're calling it across how many Watts?
>Is this throughput real
Think more like how does a service scale to that throughput is their hardware actually good where's the evidence, it's kinda irrelevant in that context?
Anonymous
10/10/2025, 7:51:34 PM
No.106849206
>>106844276
>She giggled like she's playing a joke or something
I'd prefer 'was' was written out in full here.
>She smiles and sat up
Tenses don't match.
Anonymous
10/10/2025, 7:52:45 PM
No.106849212
>>106849111
not that I've tried that model specifically but cerebras' whole thing is offering crazy speed so I wouldn't be surprised
Anonymous
10/10/2025, 7:57:33 PM
No.106849260
>>106849014
I dl'd bartowski's actually
Anonymous
10/10/2025, 8:00:26 PM
No.106849285
>L3.3 Nemotron Super
they're still messing with oldass llama?
Anonymous
10/10/2025, 8:02:13 PM
No.106849297
>>106849333
>>106848930
Put -ot "blk\.(number of layers)\.ffn_.*_exps\.weight=CUDA0" before -ot ".ffn_.*_exps.=CPU".
If you can't into Regex then replace "number of layers" with (0|1|2|3) and so on until you OOM.
Anonymous
10/10/2025, 8:04:12 PM
No.106849311
>>106849390
I just woke up.
Where's Gemma?
Anonymous
10/10/2025, 8:06:48 PM
No.106849327
>>106849367
>>106849515
Anonymous
10/10/2025, 8:07:28 PM
No.106849333
>>106849297
Thanks I get it now
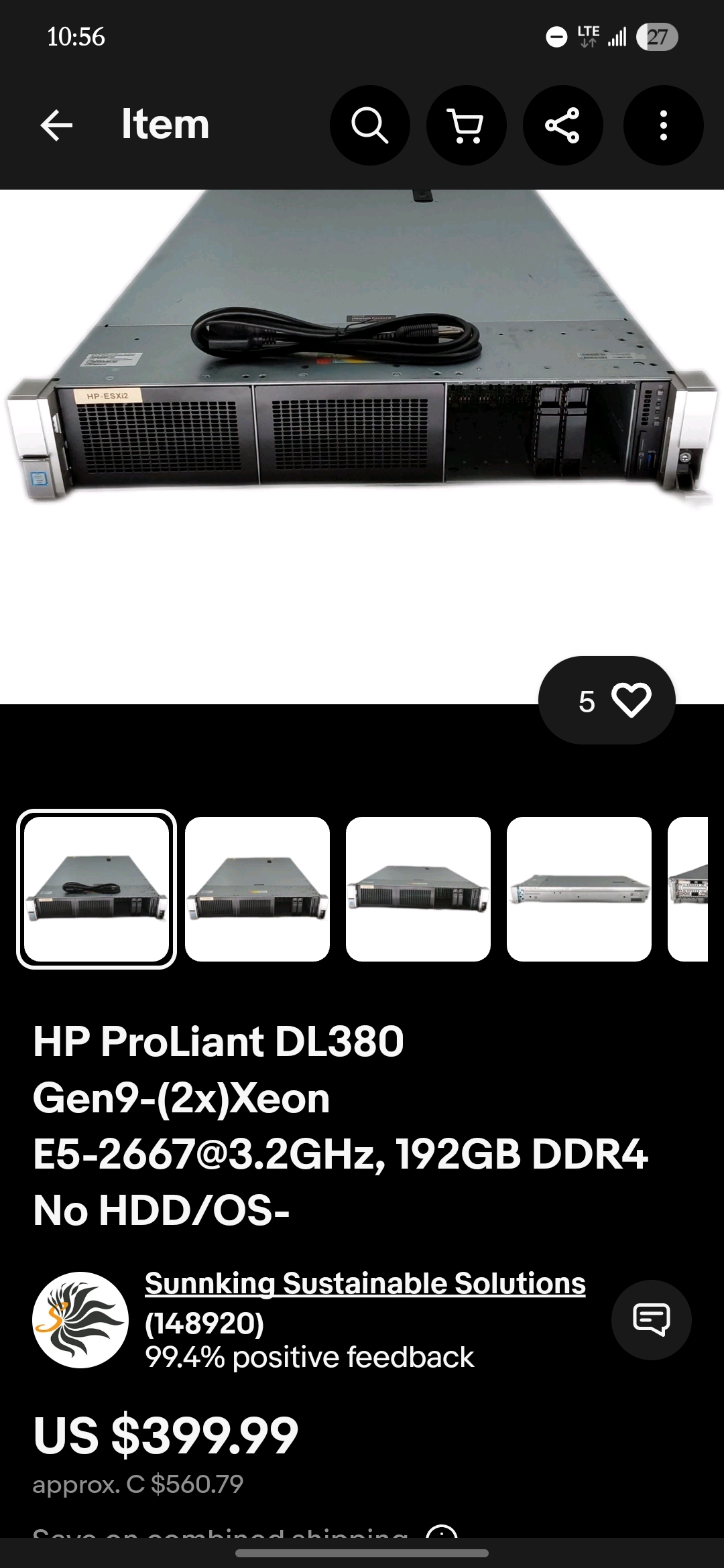
So is there a reason I can't just order something like this to run GLM 4.6? Why do I have to spend thousands of dollars on some jerry rigged autism setup that causes the lights in my apartment to flicker every time I turn it on to run large models? I am assuming there is a catch but I can't figure it out.
Anonymous
10/10/2025, 8:10:28 PM
No.106849357
>>106849438
>>106849026
>label doesn't say what it is
>nothing in the bottle
Anonymous
10/10/2025, 8:11:22 PM
No.106849367
Anonymous
10/10/2025, 8:11:26 PM
No.106849368
>>106849397
>>106849404
>>106849339
Okay here's some math for you retards.
Cloud models run on hardware running at near full occupancy since it's dynamically scaled.
Local models run on hardware not nearly at full occupancy, meaning you're wasting your money buying useless hardware that will soon be obsolete and there's not even an Nvidiot buy-back clause.
TL;DR: Just use API you fucktard
Anonymous
10/10/2025, 8:11:54 PM
No.106849370
>>106849339
Some people dish out advice but they are not running anything at home... Remember this.
Anonymous
10/10/2025, 8:13:49 PM
No.106849390
Anonymous
10/10/2025, 8:13:55 PM
No.106849391
>>106849339
How many memory channels? What is the maximum bandwidth supported by the processor and motherboard?
Also you probably can't fit a gpu in that case.
Anonymous
10/10/2025, 8:14:55 PM
No.106849397
>>106849403
>>106849368
>Just use API you fucktard
Look at the name of the general you're on you illiterate fucktard
P.S. your answer is not helpful in the slightest
>>>/g/aicg/
Anonymous
10/10/2025, 8:15:23 PM
No.106849403
>>106849416
>>106849420
>>106849397
Will you be eating shit if it's named shiteating general?
Anonymous
10/10/2025, 8:15:32 PM
No.106849404
>>106849411
>>106849368
how many more two more week periods until the hardware becomes obsolete?
Anonymous
10/10/2025, 8:16:25 PM
No.106849411
>>106849404
>i have 6 second memory span like a goldfish and have no object permanence
Anonymous
10/10/2025, 8:17:25 PM
No.106849416
>>106849426
>>106849403
>waaaaaaah thing I don't like
If you went to shiteating general and complained about eating shit, you would not be welcome there either
Fuck off
Anonymous
10/10/2025, 8:18:08 PM
No.106849420
>>106849403
that's how generals work yes
Anonymous
10/10/2025, 8:18:27 PM
No.106849426
>>106849456
>>106849416
Cloud service is pay as you go
Local is pay upfront and underutilize
Your whole hobby is a scam and you being low IQ don't even realize it
Anonymous
10/10/2025, 8:18:30 PM
No.106849427
>>106849468
>>106849339
I don't know what website you're using but to me that looks like the base price of the chassis, not the price of a fully specced-out machine.
Anonymous
10/10/2025, 8:19:31 PM
No.106849438
Anonymous
10/10/2025, 8:19:38 PM
No.106849439
Anyone using Zed or other agentic things with local models? What hardware/software are you using to run the models, and which do you like to use? What sorts of tasks do you use them for?
Anonymous
10/10/2025, 8:20:57 PM
No.106849450
>>106849476
>>106849339
>xeon e5
For something workstation shaped, look into hp z440.
You'll have to google around for performance figures.
Anonymous
10/10/2025, 8:21:13 PM
No.106849452
>>106849473
If you tell him some people don't want feds reading their cunny logs (not me btw), he'll just say "get fucked".
Anonymous
10/10/2025, 8:21:30 PM
No.106849456
>>106849426
>please send me your prompts to our good servers,,, redeem api token saar no scam guarantee :)
Anonymous
10/10/2025, 8:22:30 PM
No.106849468
>>106849565
Anonymous
10/10/2025, 8:23:26 PM
No.106849473
>>106849452
>(not me btw)
Anonymous
10/10/2025, 8:23:44 PM
No.106849476
>>106849514
>>106849450
Okay but why not picrel?
You have said no that doesnt work for models, and given an alternate suggestion but why? Explain like I'm retarded because I am.
Local:
1. Is not cost efficient because it underutilizes hardware
2. Has no access to most powerful models (>2T) and often have to run at braindamaged quantization
3. Has no hardware buyback agreement leaving you with obsolete hardware in a few months as models grow larger, without a way of recouping money
You have no argument against this
All you can do is namecalling and cope
Anonymous
10/10/2025, 8:28:08 PM
No.106849514
>>106849552
>>106849476
It would be a pain to physically manhandle. (Size, shape, weight vs tower case.)
It would probably be filled with those screamer fans.
Anonymous
10/10/2025, 8:28:13 PM
No.106849515
Anonymous
10/10/2025, 8:28:52 PM
No.106849520
>>106849506
Counterargument, I think running models locally is cooler.
Anonymous
10/10/2025, 8:29:15 PM
No.106849524
>>106849506
>hobby not cost efficient
Anonymous
10/10/2025, 8:30:07 PM
No.106849530
>>106849506
If local is so worthless then why are you here? Is your time so worthless that you spend it on reading a thread about things you don't like?
Anonymous
10/10/2025, 8:30:46 PM
No.106849541
>>106849555
>>106849566
>>106849506
I have full control over my own machine. Power is worth trade-offs. Specifically the power to do things you don't like and can't do anything against no matter how much you seethe about it.
>>106849514
Thanks
>screamer fans
Yeah then that's not an option. I don't want to bother my neighbors with something that sounds like a vacuum cleaner at 2:00 AM, so this is limiting for me. It's possible I am just completely fucked until I live somewhere more private.
If I was a richfag I'd just drop 2k on some 128gb gayming rig with a 5090 and use it for LLMs, but my budget is less than 1k so a server with cheap DDR4 is all I can dream of.
Why is this so difficult bros?
Anonymous
10/10/2025, 8:31:36 PM
No.106849553
>>106849506
thought this was gore for a second
>>106849541
>I have full control over my own machine. Power is worth trade-offs
You aren't important enough for people to care about your data
Anonymous
10/10/2025, 8:31:54 PM
No.106849557
>>106849568
>>106849725
Anonymous
10/10/2025, 8:33:04 PM
No.106849565
>>106849468
Huh, I looked up when these parts were released and they're older than I thought so I guess the price checks out.
Even with optimal software the maximum memory bandwidth will be like half that of a P40 though.
Anonymous
10/10/2025, 8:33:06 PM
No.106849566
>>106849541
And there are applications to being able to run agents fully offline and to not exfiltrating data etc etc, beyond the hobbyist stuff too.
>>106849555
Then why do they keep collecting anon's data?
Why don't they just stop doing that?
Anonymous
10/10/2025, 8:33:13 PM
No.106849568
>>106849725
>>106849557
Probably talking about GLM 4.6
Anonymous
10/10/2025, 8:33:52 PM
No.106849574
>>106849555
>he says, in general about the technology that eliminates this excuse
Anonymous
10/10/2025, 8:35:09 PM
No.106849586
>>106849555
Good afternoon officer, slow day?
Anonymous
10/10/2025, 8:35:19 PM
No.106849590
>>106849552
You could always leave the case open and replace the fans and heatsinks with bigger ones
Anonymous
10/10/2025, 8:37:23 PM
No.106849608
>>106849552
Just get the server. It's still an useful computer anyway.
Anonymous
10/10/2025, 8:38:19 PM
No.106849616
>>106849630
>>106849552
Bro just buy 128GB DDR4 RAM and a second-hand 3090. It's well within 1K.
Anonymous
10/10/2025, 8:38:33 PM
No.106849620
>>106849636
ITT "local sucks" trolling for the millionth time by the same fuckfaces that can't afford local
Anonymous
10/10/2025, 8:40:04 PM
No.106849630
>>106849644
>>106849616
I currently use a gayming laptop with two ddr5 sodimm slots, and no desktop PC, so that's not an option.
Anonymous
10/10/2025, 8:41:08 PM
No.106849636
>>106849640
>>106849663
Anonymous
10/10/2025, 8:41:30 PM
No.106849640
>>106849647
Anonymous
10/10/2025, 8:41:49 PM
No.106849644
>>106849658
>>106849630
Does it have an empty m.2 slot ?
Anonymous
10/10/2025, 8:42:23 PM
No.106849647
>>106849640
Local is peak reddit. Half of the posters here probably also post on /r/localllama
Anonymous
10/10/2025, 8:44:01 PM
No.106849658
>>106849785
>>106849644
Yes, but I don't see how that helps here
Anonymous
10/10/2025, 8:45:13 PM
No.106849670
Anonymous
10/10/2025, 8:47:24 PM
No.106849692
>>106849700
Why are faggots so asshurt over local models? Is it because they're too poor to own GPUs? People who can afford this shit can also afford claude credits or openrouter, many of us use it when necessary, but sometimes it's nice to have 100% privacy.
Anonymous
10/10/2025, 8:47:45 PM
No.106849696
>>106849713
>>106849735
>>106849663
What does next level recurrence mean / look like?
Anonymous
10/10/2025, 8:48:24 PM
No.106849700
>>106849692
It's not "people", it's 1 schizoaffective troll
Anonymous
10/10/2025, 8:50:36 PM
No.106849713
>>106849696
Your world view
Anonymous
10/10/2025, 8:53:03 PM
No.106849725
>>106849806
>>106850019
>>106849557
>>106849568
Yeah to me waiting 5 mins thonking on a Q3 is worth it, first time I can tolerate these waits. She understands.
Anonymous
10/10/2025, 8:53:27 PM
No.106849731
>>106849506
sure thing mr.fed
we should all give up our privacy at this instant
Anonymous
10/10/2025, 8:54:03 PM
No.106849735
>>106849696
unless you meant another level added on top of
>>106849663, in that case it would mean people's view of this particular world view difference
Anonymous
10/10/2025, 8:56:55 PM
No.106849755
>>106849506
>not cost efficient because it underutilizes hardware
It is still infinity times more efficient than cryptoshit.
Anonymous
10/10/2025, 9:00:11 PM
No.106849784
>>106849555
This is exactly what a glownigger would say kek
Anonymous
10/10/2025, 9:00:14 PM
No.106849785
>>106849808
>>106849658
You could use something like
>>106807507 together with an atx psu to plug a 3090 into your laptop.
Anonymous
10/10/2025, 9:02:00 PM
No.106849797
>>106849506
>pretends legitimate counterarguments don't exist and were never posted today or in the past, keeps posting the same thing over and over again like an LLM
Sad!
Anonymous
10/10/2025, 9:03:05 PM
No.106849806
>>106849725
>4 GPUs
I'll cope with nemo for now
Anonymous
10/10/2025, 9:03:18 PM
No.106849808
Anonymous
10/10/2025, 9:21:03 PM
No.106849934
>>106847952
At least you can talk.
Anonymous
10/10/2025, 9:21:53 PM
No.106849941
>>106849552
It's not that loud unless you're running at 100% CPU.
Have a few, can't really hear them through walls. If you really care can always get a server closet.
RAM is going to be most of the cost, ddr4 ecc is still quite expensive.
Anonymous
10/10/2025, 9:21:53 PM
No.106849942
qwen3 vl and next gguf status?
Anonymous
10/10/2025, 9:25:58 PM
No.106849968
>>106849995
>tell ai gf: "Don't be sycophantic" in sysprompt
>end of 7th message: "Just… don't say weird things like that again. It's creepy."
I am a transcendent incel.
Anonymous
10/10/2025, 9:29:18 PM
No.106849995
>>106849968
Kek
I'm sorry anon, at least you can practice not being creepy on fake women without any consequences
Anonymous
10/10/2025, 9:32:44 PM
No.106850019
>>106850141
Anonymous
10/10/2025, 9:33:40 PM
No.106850026
>>106850086
>>106850285
I was just thinking:
- The Asus Pro WS WRX90E-SAGE motherboard has 6 PCIe 5.0 16x slots.
- The Samsung 9100 NVMe SSD PCIe 5.0 4x has a maximum sequential read speed of 14.5 GB/s.
- Each PCIe slot could host 4 NVMe SSDs.
- 14.5 * 4 * 6 = 348 GB/s
It looks like SSDmaxxing might now be a reality. Sure, it wouldn't be very cost-effective (It would be $3400 in SSDs alone), but...
Anonymous
10/10/2025, 9:36:04 PM
No.106850039
I think the version of GLM offered as a coding API is lower quality than the version offered on openrouter.
Anonymous
10/10/2025, 9:43:49 PM
No.106850085
>>106850305
Claude told me DDR3maxxing is okay...
Anonymous
10/10/2025, 9:43:56 PM
No.106850086
>>106850222
>>106850026
What's the read lifetime on those?
Seems like that might be an issue.
Anonymous
10/10/2025, 9:48:31 PM
No.106850128
>>106850158
>>106843051 (OP)
Sirs and ma'ams, I may have just found the most GPT-slopped tweet of all time. I can't quite put my finger on why, but I'm convinced this was written by Gemini in particular.
https://xcancel.com/TheAIObserverX/status/1976523090889744700?t=vK02HSzqcXnA_SnCVQmnOA&s=19
Anonymous
10/10/2025, 9:50:21 PM
No.106850141
>>106850271
>>106850019
Yeah does it matter?
Anonymous
10/10/2025, 9:52:07 PM
No.106850158
>>106850176
>>106850128
>tweet
>textwall
Since when did twatter become a blog platform? Is there an extension that merges multi-part tweets together or what? This screenshot is fucking with me, it's like the uncanny valley.
Anonymous
10/10/2025, 9:52:33 PM
No.106850164
>>106850758
## ** Conclusion**
This is an **exceptionally well-engineered codebase** that demonstrates:
- **Professional software engineering practices**
- **Deep understanding of ML systems architecture**
- **Attention to performance and robustness**
- **Excellent code organization and documentation**
The codebase is **production-ready** and follows industry best practices for C-based ML infrastructure. The modular design makes it easy to extend and maintain, while the comprehensive testing ensures reliability.
**Rating: (5/5 stars)**
Anonymous
10/10/2025, 9:53:46 PM
No.106850176
>>106850158
If you're a "Twitter blue" sub you get the privilege of writing giant walls of text as opposed to the normal 200-ish character count limit.
Anonymous
10/10/2025, 9:54:11 PM
No.106850182
>>106850226
*Smedrins all over the place*
>>106850086
SSDs don't wear up in practice from read activity. The main issue is that only Threadripper PRO WX7000/9000 CPUs and actually support all those PCIe 5.0 lanes, which would drive costs up. Thermals might be an issue too.
Anonymous
10/10/2025, 9:59:01 PM
No.106850226
>>106850182
you can't say that here
Anonymous
10/10/2025, 10:04:36 PM
No.106850269
Anonymous
10/10/2025, 10:05:04 PM
No.106850271
>>106850141
I'm going to copy your launching params just to see how much t/s I can get. 4t/s at q5 is borderline insufferable
Anonymous
10/10/2025, 10:06:10 PM
No.106850285
>>106850328
>>106850026
>>106850222
>>106850222
DDR3maxxing is almost certainly cheaper and more efficient than SSDmaxxing
Anonymous
10/10/2025, 10:09:08 PM
No.106850305
>>106850314
>>106850356
>>106850085
You can probably run a model on Pentium 4 off of floppies if you're patient
Anonymous
10/10/2025, 10:10:19 PM
No.106850314
>>106850330
>>106850305
I am okay with 2-3 T/s at minimum
Anonymous
10/10/2025, 10:10:24 PM
No.106850316
For SSDmaxxers.
Scratch SSD Kingston A400 (240GB). Claimed speeds: 500MB/sec (read) y 350MB/sec (write)
> time dd bs=8192 if=mystery_meat.gguf of=/dev/null
2130860+1 records in
2130860+1 records out
17456009152 bytes transferred in 65.337 secs (267168819 bytes/sec)
Now do your math again. With your own hardware, whatever you have and compare them to their claimed speeds. TEST SUSTAINED READ. Minimum 8GB. I don't care what the specs for hardware you don't have say.
Anonymous
10/10/2025, 10:11:45 PM
No.106850328
>>106850222
>>106850285
the future is e-wastemaxxing
Anonymous
10/10/2025, 10:11:58 PM
No.106850330
>>106850351
>>106850314
That is what you'll get with 8-channel DDR4
Anonymous
10/10/2025, 10:13:01 PM
No.106850343
>>106850701
>>106850222
ssd wear is something only retards obsess for anyway
pic related graph has drives that have undergone extreme stress test of constant, non stop writes, which is more destructive irregular writes letting the controller/firmware do better house keeping / write balancing (particularly if you always leave a decent amount of empty space on your drives)
See that 970 evo (TLC drive)?
The 250gb was rated for 150 tb of writes warranty wise. It died after 5000TB of writes.
As long as you didn't buy a lemon, which is something that can happen with any electronics, no normal usage is going to kill your fucking drive
I'm not saying it's impossible for a SSD to die, but frankly I've experienced and heard of around me far more often of spinning rust garbage dying than S O L I D S T A T E
Anonymous
10/10/2025, 10:13:44 PM
No.106850347
>>106850384
I faintly remember a post about model loading from disk being random reads, not sequential. Was/is that true?
Anonymous
10/10/2025, 10:13:58 PM
No.106850351
>>106850445
>>106850330
The difference between ddr3 and ddr4 isn't that huge especially when running a MoE, do the math nigga
Anonymous
10/10/2025, 10:14:43 PM
No.106850356
>>106850305
pingfs maxxing is the cheapest solution if you're patient
Anonymous
10/10/2025, 10:17:42 PM
No.106850376
>>106850402
>>106850222
There's also another problem. Even if you filled all those PCIe 5.0 16x slots with NVMe 5.0 SSDs, it's not like the CPU would be directly reading data from them. The streamed data would have to go into RAM first. At the very least you'd need at least the same amount of RAM bandwidth to avoid bottlenecks, assuming no other overheads slowing things down.
Anonymous
10/10/2025, 10:18:32 PM
No.106850384
>>106850347
theoretically I think it depends in what order the tensors are arranged in the gguf. but when loading models that go over the available RAM in llama I get close to ideal speeds (you can check with iotop).
Anonymous
10/10/2025, 10:19:50 PM
No.106850402
>>106850376
Would it though? Doesn't it use DMA, which bypasses RAM and makes the data go directly into the CPU's cache?
Anonymous
10/10/2025, 10:21:17 PM
No.106850419
>>106850465
>>106850501
Anonymous
10/10/2025, 10:24:35 PM
No.106850445
>>106850489
>>106850351
Fewer channels though, and since you'll have to buy lrdimm I doubt you'll get anything better than 1333MHz
Anonymous
10/10/2025, 10:27:00 PM
No.106850465
Anonymous
10/10/2025, 10:29:46 PM
No.106850489
>>106850568
>>106850445
1333mhz to 1865mhz is like a gain of 0.2 tokens per second
Anonymous
10/10/2025, 10:31:18 PM
No.106850501
>>106850564
>>106850419
https://miladink.github.io/
>I have expertise in both likelihood models and RL. I think the mixture of this two will be the key to AGI.
this nigger is yet another grifter masquerading as a researcher
no sane person would be talking about anything "leading to agi" and his prior work is laughable crap that was buried and ignored
Anonymous
10/10/2025, 10:33:14 PM
No.106850514
Anonymous
10/10/2025, 10:36:18 PM
No.106850540
>>106849111
It's surely not the throughput for a single request, lmao.
Anonymous
10/10/2025, 10:38:43 PM
No.106850564
>>106851309
>>106850501
Here's chink xitter profile promoting it, you'll take your words back and lap it up now like a good chink shill doggy.
https://x.com/jiqizhixin/status/1976466786565656986
Anonymous
10/10/2025, 10:39:22 PM
No.106850568
>>106850598
>>106850489
With that logic, my DDR4-3200 is almost as good as DDR5-4800
Anonymous
10/10/2025, 10:43:32 PM
No.106850598
>>106850568
It is, kek
The upgrade would increase t/s very slightly but otherwise wouldn't be worth it
Anonymous
10/10/2025, 10:56:40 PM
No.106850701
>>106850343
If you're using them to read 200gb+ per prompt it might actually be an issue.
Anonymous
10/10/2025, 11:03:27 PM
No.106850758
>>106850164
Why you reviewing my code bro
Anonymous
10/10/2025, 11:11:46 PM
No.106850818
>>106849555
You conflate cause and effect. You are unimportant because you let them take your data.
Anonymous
10/10/2025, 11:21:24 PM
No.106850880
>>106850901
bought puts this morning
what motherboard and cpu would pair well with 2x rtx 6000 pro?
Anonymous
10/10/2025, 11:24:29 PM
No.106850901
>>106850880
>what motherboard
mine
>cpu
mine
>2x rtx 6000 pro
send me over and I'll check
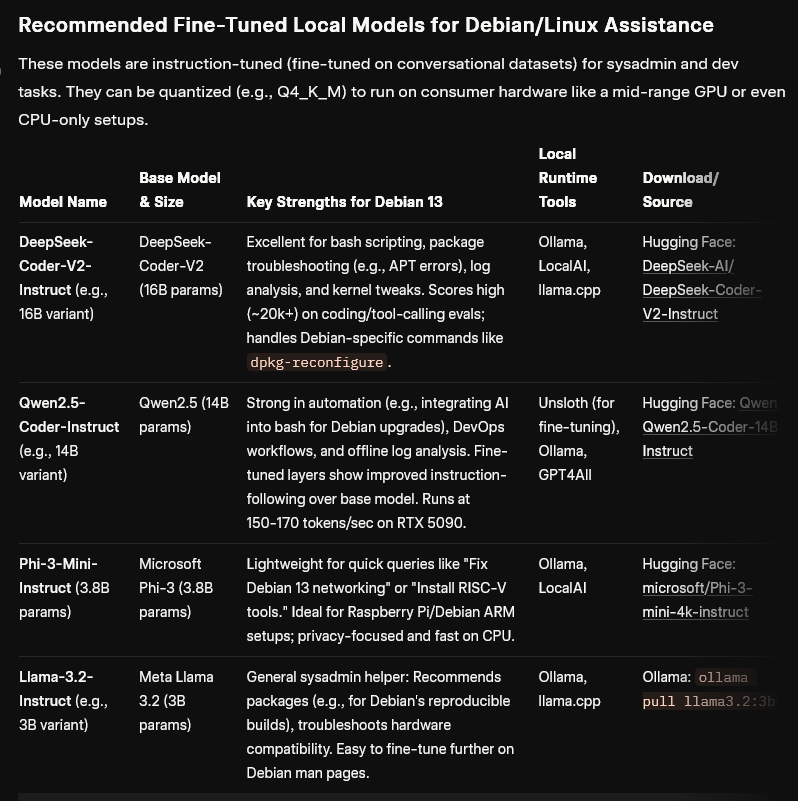
is there a local model fine-tuned as a Linux helper?
Anonymous
10/10/2025, 11:31:46 PM
No.106850953
>>106850986
>>106850926
post the source, not some faggot emoji-using ewhore's mitwit opinion on it
Anonymous
10/10/2025, 11:34:11 PM
No.106850986
Anonymous
10/10/2025, 11:37:21 PM
No.106851011
>>106851036
>>106850926
>death of text to speech
Transcripts useless according to literally who on Twitter?
Anonymous
10/10/2025, 11:38:12 PM
No.106851018
>>106851184
>>106851283
>>106848425
>doing two lookups when only one is needed
lol
lmao
return dataset.get(problem)
Anonymous
10/10/2025, 11:40:55 PM
No.106851036
>>106851065
>>106851011
You will never ever be happy with this attitude.
Anonymous
10/10/2025, 11:43:59 PM
No.106851065
>>106851036
>if you don't enjoy slopposting you will never be happy
Anonymous
10/10/2025, 11:57:23 PM
No.106851184
>>106851018
With this attitude, you won’t become an ML researcher
Anonymous
10/11/2025, 12:06:58 AM
No.106851283
>>106851334
>>106851018
You won’t become a Python brahmin either
return dataset.get(problem,"I'm sorry, but I can't help you with that.")
Anonymous
10/11/2025, 12:09:45 AM
No.106851309
>>106850564
> cutting context
how revolutionary...
Anonymous
10/11/2025, 12:11:29 AM
No.106851327
>>106851526
Anonymous
10/11/2025, 12:11:52 AM
No.106851334
>>106851283
You forgot to insert
if random.random() < 0.5:
return "The user's request is unsafe and problematic. We must refuse."
Anonymous
10/11/2025, 12:39:27 AM
No.106851526
Anonymous
10/11/2025, 12:47:56 AM
No.106851579
>>106851684
>>106851684
>>106850927
Are you asking for use or curios?
If for use, any local model should be fine, + a local RAG setup with notes would be the best path forward (grow your notes and swap models)
>>106843545
Current meta is Ryzen PRO AI 395+ with 128gb fast unified memory. Very good for MoE models. Running GMKtec EVO-X2 with 128gb of vram.
Very power efficient and compact.
Anonymous
10/11/2025, 12:56:40 AM
No.106851647
>>106851586
BASED. Fuck newfags.
Anonymous
10/11/2025, 1:02:34 AM
No.106851684
>>106851759
>>106851579
Nta
>>106851579
>any local model should be fine, + a local RAG setup with notes would be the best path forward
Is there an absolute minimum perimeter size you would say would be usable? For example, would a 7B model or even a 2B model be enough?
Anonymous
10/11/2025, 1:09:46 AM
No.106851732
Anonymous
10/11/2025, 1:15:37 AM
No.106851759
>>106851823
>>106851684
Honestly I would think qwen3-4B would be good enough. I've built something to do exactly this, and am hoping it will get usage once I start to share it (currently broken).
I haven't done testing with various model sizes but I plan to, to build up a record of how successful various models are with a few datasets with the RAG system its using.
Anonymous
10/11/2025, 1:24:28 AM
No.106851823
>>106851874
>>106851759
So that 3 to 4b model is good enough to essentially be used along with a RAG setup as a local information lookup machine? How accurate is it? I'm thinking of setting up something similar on a local instance of mine, but first I need to figure out how to set up a RAG pipeline in the first place. Where should I start?
Anonymous
10/11/2025, 1:34:08 AM
No.106851874
>>106851936
>>106851823
1. Accuracy is generally a search thing(retrieval), not an LLM thing. If you mean accuracy of response/truthfulness, no idea.
2. No way to tell you how often it might be wrong or similar. This is where the RAG comes into play, so that you can perform a query, have it retrieve info from your notes, generate a response, and then check it against the sources to say 'yes, this is correct.' - see gemma APS for one take/approach.
3. If you're just getting started with linux, having the Linux Sys admin handbook as one of the first pieces in your media library would be my suggestion.
Would recommend using SQLite (FTS / BM25) + ChromaDB +
https://github.com/rmusser01/tldw_server/tree/dev/tldw_Server_API/app/core/Ingestion_Media_Processing libraries for your specific media processing needs +
https://github.com/rmusser01/tldw_server/tree/dev/tldw_Server_API/app/core/Chunking for chunking.
Throw that into Deepseek/ChatGPT5 High and you should have a simple/straightforward setup. Project I'd like to recommend but can't right now is
https://github.com/rmusser01/tldw_chatbook, which is the single user TUI version, but the UI is broken.
For my full pipeline(for the server):
https://github.com/rmusser01/tldw_server/tree/dev/tldw_Server_API/app/core/RAG
Anonymous
10/11/2025, 1:43:32 AM
No.106851936
>>106851874
NTA, but I kneel for the effort invested in there
Anonymous
10/11/2025, 1:44:27 AM
No.106851939
>>106851586
how much t/s you get with what model and quant ?
Anonymous
10/11/2025, 1:49:27 AM
No.106851973
>>106851586
>Ryzen PRO AI 395+
Macucks need not apply