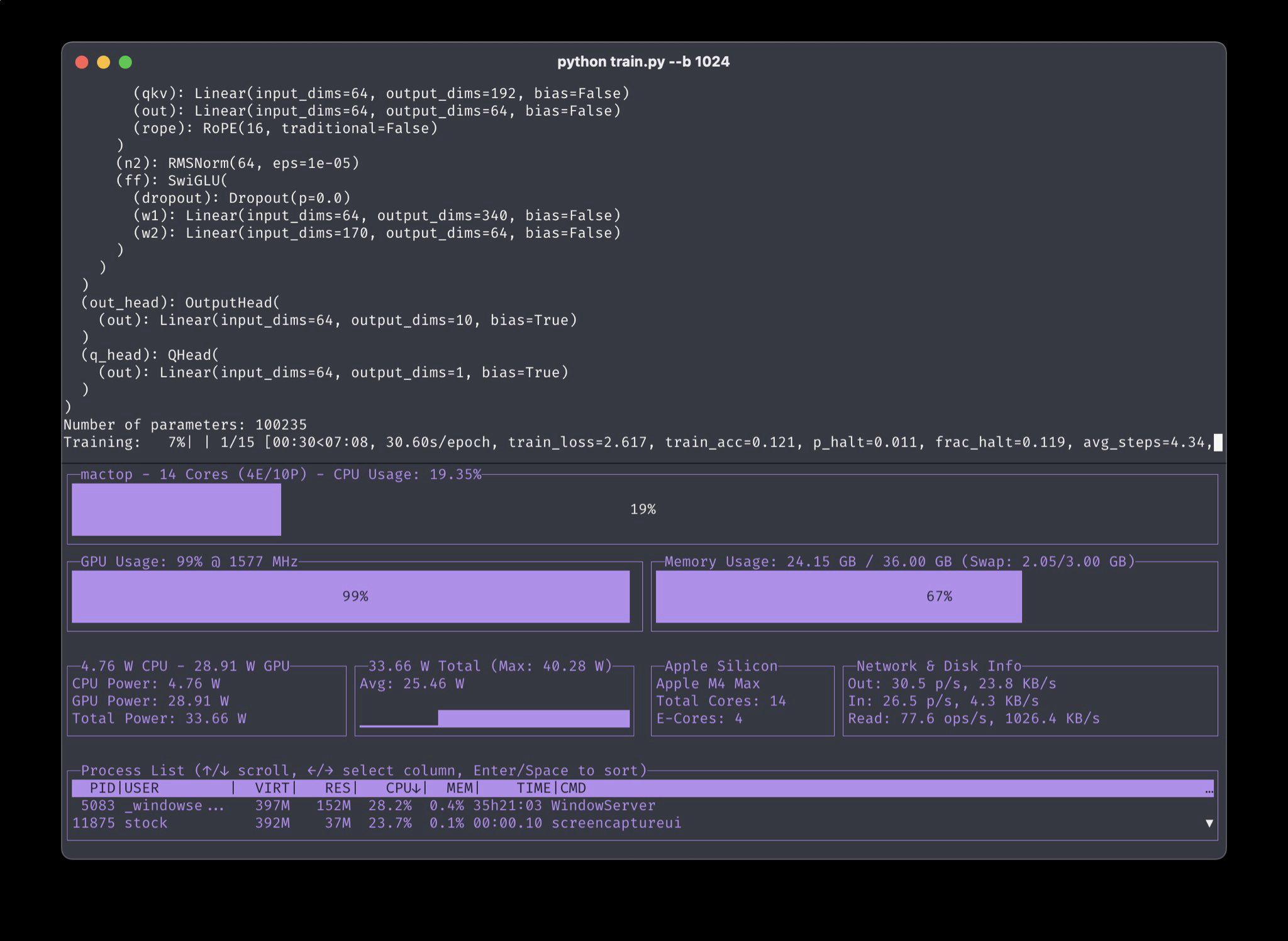
/lmg/ - Local Models General
Anonymous
10/11/2025, 6:17:46 PM
No.106857387
►Recent Highlights from the Previous Thread:
>>106851720
--Building a quad-Blackwell Pro GPU workstation: case selection, storage, and hardware tradeoffs:
>106851941 >106851975 >106852028 >106852102 >106851976 >106852035 >106852055 >106852061 >106852114 >106852126 >106852875 >106852880 >106855669 >106852128 >106852349
--Modern Python OCR tools for complex layouts and multiple languages:
>106853256 >106853500 >106853539 >106853775 >106853784 >106855440
--Exploring transformer intuition through recommended educational resources:
>106852421 >106852439 >106852477 >106852494 >106852496 >106852617
--Optimizing large model inference on limited VRAM hardware:
>106853666 >106853668 >106853672 >106853751 >106853677 >106853695 >106853747
--Configuring AI models for first-person perspective through prompt engineering:
>106853298 >106853335 >106853437 >106853358
--Resolving model instability through sampling parameter and context window adjustments:
>106854051 >106854241 >106854285 >106854342 >106854348 >106854582
--RAG pipeline setup with Jan-nano or 30b-3b model for local information lookup:
>106851826 >106852206 >106852472
--Debating AI's societal impact, misinformation risks, and economic implications:
>106852252 >106852296 >106852330 >106852393 >106852718 >106852883 >106852910 >106852951 >106853025 >106853105 >106853201 >106853259 >106853325 >106855198 >106853093 >106852987 >106852950 >106852981 >106852329 >106854471 >106854882 >106854909 >106854916 >106854927 >106854928 >106854947 >106854923
--Speculation on Gemma 4 release and censorship/vision capabilities:
>106856066 >106856114 >106856117 >106856212 >106856533 >106856591
--Capital bubble critique of interconnected AI tech investments:
>106853688
--LM Studio adds ROCm support for RX 9070/9070 XT:
>106851854
--Miku (free space):
>106851744 >106851941 >106852453
►Recent Highlight Posts from the Previous Thread:
>>106851726
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
>>106857386 (OP)
>>(10/09) server : host-memory prompt caching #16391 merged: https://github.com/ggml-org/llama.cpp/pull/16391
Why would I use this?
Anonymous
10/11/2025, 6:21:58 PM
No.106857421
>>106857402
It's explained in the PR comment.
Anonymous
10/11/2025, 6:25:00 PM
No.106857448
>>106857402
It's like zram but for llm.
Anonymous
10/11/2025, 6:28:48 PM
No.106857476
>>106857402
To reduce prompt reprocessing.
Anonymous
10/11/2025, 6:32:59 PM
No.106857498
>>106857536
>>106857498
>$10k to run kimi k2 at full precision
talk me out of it
Anonymous
10/11/2025, 6:40:59 PM
No.106857552
>>106857560
>>106857536
>LPDDR4X memory
Anonymous
10/11/2025, 6:42:10 PM
No.106857560
>>106857552
RIP the dream
Anonymous
10/11/2025, 6:52:51 PM
No.106857645
>>106857886
>>106857536
When I visit the AliExpress page with a German IP it says they won't sell it to me.
When I use a Japanese IP they charge the equivalent of $2000 for the 96 GB variant or $2400 for the 192 GB variant.
When I use an American IP they charge $4000 and $4500 respectively.
Don't know WTF is going on (Trump tax?).
In any case, if you buy multiple of them the interconnect speed will be shit and I think getting stacking Huawei GPUs directly makes more sense.
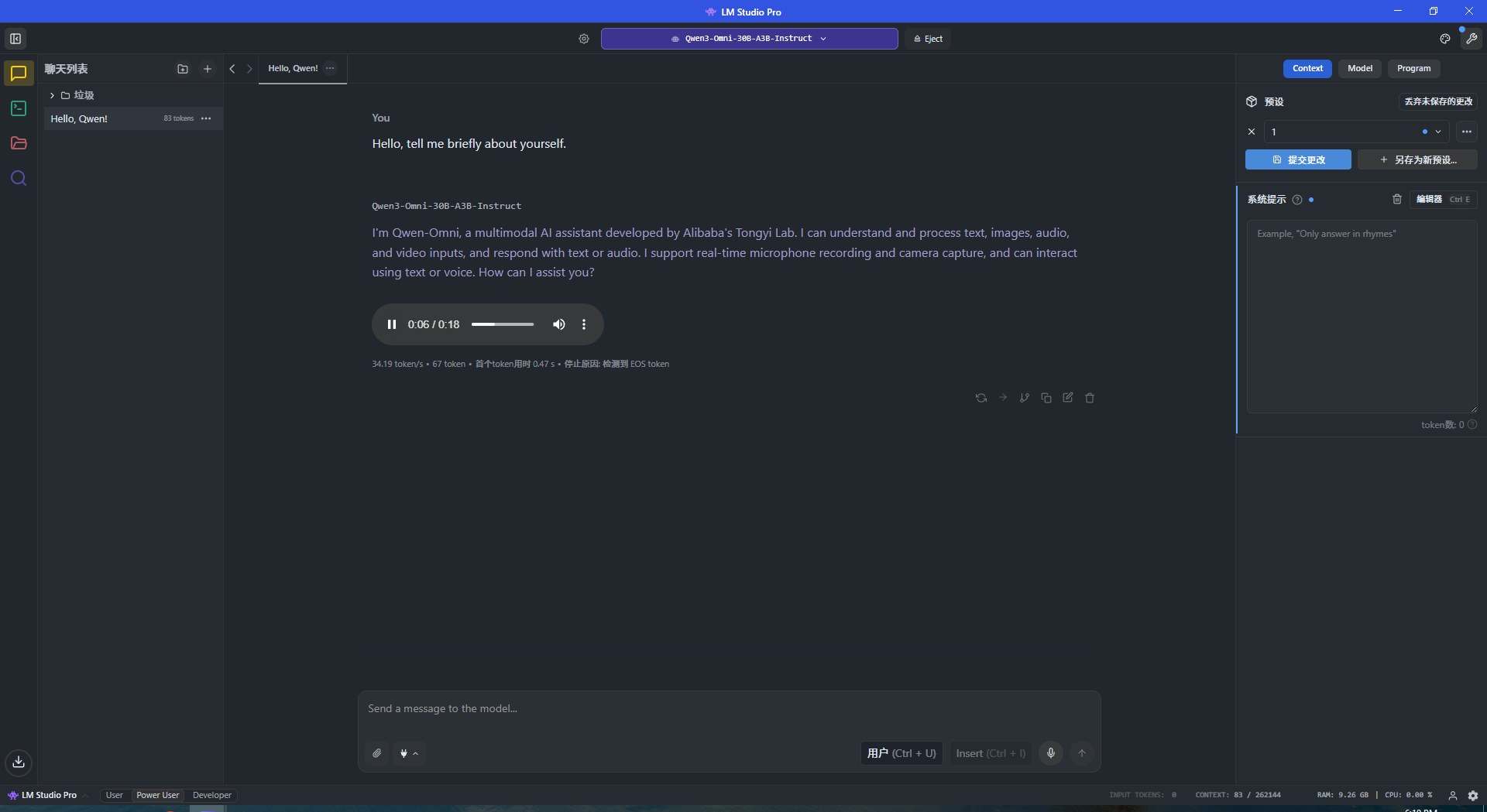
>be me, AI nerd lurking WeChat groups
>yesterday, buddy drops bomb: "yo, got LM Studio Pro, it's lit"
>wtf is that? we all use free LM Studio, he trolling?
>grill him: "what's special?"
>"early access to flagship models, uncensored abliteration versions. no bullshit filters"
>impossible.jpg, but curiosity wins, download sketchy EXE
>install, boom: Qwen3-Next-80B-A3B-Instruct, Qwen3-Omni-30B-A3B, Qwen3-VL-235B-A22B, Qwen3-VL-30B-A3B. and their raw, uncensored twins
>runs on modded llama.cpp, smooth as butter. other wild models free version dreams of
>feels like hacking the matrix, generating god-tier shit without Big Brother watching
>next day, thread explodes in group
>anon chimes in: "lmao, that's just ripped LM Studio code, rebuilt with Chinese devs. slapped 'Pro' label, added fresh Qwen support"
>sales skyrocket, cash grab exposed
>devs ghost, poof. gone
>power users dig source code: free version of LM Studio has backdoors for cops, telemetry dumping EVERY log to Apple servers on Mac
>proof? screenshots of Pro UI (sleek af), code diffs showing the hacks. attached below
>trust no one, delete everything. who's watching your prompts?
Anonymous
10/11/2025, 7:09:25 PM
No.106857769
Anonymous
10/11/2025, 7:22:01 PM
No.106857842
>KAT-Dev-72B-Exp is an open-source 72B-parameter model for software engineering tasks.
>On SWE-Bench Verified, KAT-Dev-72B-Exp achieves 74.6% accuracy — when evaluated strictly with the SWE-agent scaffold.
>KAT-Dev-72B-Exp is the experimental reinforcement-learning version of the KAT-Coder model. Through this open-source release, we aim to reveal the technical innovations behind KAT-Coder’s large-scale RL to developers and researchers.
Anonymous
10/11/2025, 7:23:35 PM
No.106857852
>>106857759
where the heck he got the source code?
Anonymous
10/11/2025, 7:24:18 PM
No.106857858
>>106859393
>>106859448
Anonymous
10/11/2025, 7:25:59 PM
No.106857872
grime hall retreats
Anonymous
10/11/2025, 7:27:26 PM
No.106857885
>>106857759
Lm studio always glowed.
Anonymous
10/11/2025, 7:27:28 PM
No.106857886
>>106857898
>>106857645
>(Trump tax?).
Pretty sure there is no Trump anything preventing sale to Germany
Anonymous
10/11/2025, 7:29:11 PM
No.106857898
>>106857886
I meant regarding why the listed price for a US IP is like 2x that for a Japanese IP.
Anonymous
10/11/2025, 7:30:54 PM
No.106857911
>>106857848
another finetuned qwen2 without mentioning it/10
Anonymous
10/11/2025, 7:33:16 PM
No.106857925
>>106857993
>>106857759
based AI greentexter
Anonymous
10/11/2025, 7:38:12 PM
No.106857956
GLM5 hype
Anonymous
10/11/2025, 7:43:10 PM
No.106857993
>>106857925
It's disturbing that some people just took the schizo rambling at face value. Maybe also bots.
Anonymous
10/11/2025, 7:54:21 PM
No.106858073
>>106858079
>>106858105
>>106857536
Here:
>The OPi AI Studio Pro cannot operate independently. It must be connected via a USB4 cable to a host computer equipped with a USB4 or Thunderbolt 4 (TB4) interface to function properly.
>Note: We recommend that the host computer’s RAM exceeds the OPi AI Studio Pro’s onboard memory (96GB/192GB) for optimal performance.
>Insufficient host RAM may cause inference program startup failure.
>After startup, model files are transferred from the host to the OPi AI Studio Pro’s memory, freeing up host memory.
>Low-memory systems may start using swap space, but this significantly increases model loading time.
Anonymous
10/11/2025, 7:55:25 PM
No.106858079
>>106858088
>>106858073
How the fuck is that a "mini PC"?
Anonymous
10/11/2025, 7:56:36 PM
No.106858088
>>106858079
Sounds like a much easier way to backdoor something?
Anonymous
10/11/2025, 7:58:54 PM
No.106858105
>>106858073
Completely worthless then. Could've been nice if they at least had some interlink capability.
Anonymous
10/11/2025, 8:34:54 PM
No.106858349
Well dude it is like this. I saw glm chan writing. And I had the most excellent coom of my life.
>>106857386 (OP)
GLM 4.6 is a lot less censored than 4.5. This is the first time I've seen a company do a reversal on censorship. Must be a reaction to those yacht-chasing pigs at OpenAI
Anonymous
10/11/2025, 9:20:04 PM
No.106858691
>>106858698
>>106858719
I have found deepseek 3.2 to significantly outperform glm 4.6 at long context. (over 20k tokens)
Anonymous
10/11/2025, 9:20:53 PM
No.106858698
>>106858722
>>106858691
Sex or perverse degeneracy called coding?
Anonymous
10/11/2025, 9:22:58 PM
No.106858712
>>106858586
It's no secret that censorship stifles creativity too. It definitely comes up with more stuff compared to the previous version. Makes me wonder what gpt-oss could have been without much of the built-in safety training.
Anonymous
10/11/2025, 9:23:37 PM
No.106858719
>>106858734
>>106858691
How does 3.2 compare to 3.1? Does the sparse attention make it remember better?
Anonymous
10/11/2025, 9:24:06 PM
No.106858722
>>106858810
>>106858698
custom RPG setting comprehension and script judging/editing. i haven't gotten to the sex part in over a year.
Anonymous
10/11/2025, 9:25:24 PM
No.106858734
>>106858719
I think it might. the ((benchmarks)) think it's better and that lines up with my experience.
Anonymous
10/11/2025, 9:30:49 PM
No.106858770
>>106858586
Mistral Small 3 and Qwen 3 decreased "safety" with later versions.
Anonymous
10/11/2025, 9:35:21 PM
No.106858806
gemini 3... glm 4.6 air...
Anonymous
10/11/2025, 9:36:32 PM
No.106858810
>>106858918
>>106858722
>i haven't gotten to the sex part in over a year.
that's quite the slowburn
Anonymous
10/11/2025, 9:42:45 PM
No.106858854
>>106858875
>upgrade my ik_llamacpp version
>my generation speeds drop by 25%
wow thank you
Anonymous
10/11/2025, 9:47:01 PM
No.106858875
>>106858909
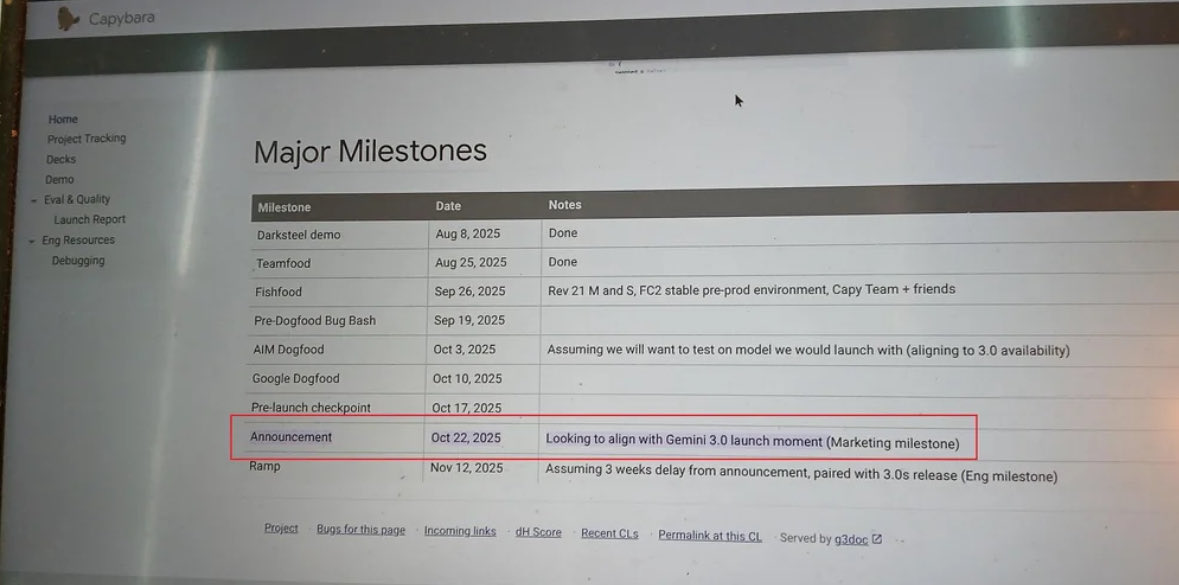
Were people just joking about Gemma 4
Anonymous
10/11/2025, 9:53:46 PM
No.106858906
>>106858900
We needed a pump to dump our ik coins.
Anonymous
10/11/2025, 9:54:27 PM
No.106858909
>>106858932
>>106858875
>He pulled?
would have been better
Anonymous
10/11/2025, 9:55:38 PM
No.106858918
>>106858810
more like
>> new model comes out
>>swipe a few times
>>say "hmm"
>>do something else.
Anonymous
10/11/2025, 9:55:46 PM
No.106858920
for those who'd like a dumb but fast FIM for local dev, just good enough to quickly autocomplete repetitive patterns, granite 4 tiny is pretty serviceable I find
ended up replacing ye olde qwen coder 2.5 with it, there hasn't been many models in recent times of smaller sizes that do well with FIM, thank you IBM
Anonymous
10/11/2025, 9:56:03 PM
No.106858921
Nvidia Engineer
10/11/2025, 9:56:28 PM
No.106858930
>>106858900
It's coming next week.
Anonymous
10/11/2025, 9:56:54 PM
No.106858932
>>106858942
Anonymous
10/11/2025, 9:57:02 PM
No.106858933
>>106858955
>>106858900
No, it was in the air, and I'm sure there must be a private llama.cpp PR ready for it.
Anonymous
10/11/2025, 9:58:10 PM
No.106858942
Anonymous
10/11/2025, 10:00:20 PM
No.106858955
>>106858965
>>106858968
>>106858933
>private llama.cpp PR
I think you meant ollama
the gemma guys never mention llama.cpp
https://blog.google/technology/developers/gemma-3/
>Develop with your favorite tools: With support for Hugging Face Transformers, Ollama, JAX, Keras, PyTorch, Google AI Edge, UnSloth, vLLM and Gemma.cpp, you have the flexibility to choose the best tools for your project.
Anonymous
10/11/2025, 10:02:10 PM
No.106858965
>>106858980
>>106858955
>Hugging Face Transformers, Ollama, JAX, Keras, PyTorch, Google AI Edge, UnSloth, vLLM and Gemma.cpp
Brutal
>>106858955
Didn't llama.cpp have a secret day 1 PR ready to go last time or was that a different model? Anyway, ollama probably pressures their partners not to mention llama.cpp.
Anonymous
10/11/2025, 10:03:40 PM
No.106858980
>>106858965
moreover gemma.cpp is abandonware, last commit two months ago, doesn't support their best tiny model (3n)
they'd rather mention that but not llama.cpp
Anonymous
10/11/2025, 10:04:18 PM
No.106858984
wayfarer 12b is a good adventure modle
Anonymous
10/11/2025, 10:04:55 PM
No.106858993
>>106859008
>>106858968
>Didn't llama.cpp have a secret day 1 PR ready to go last time or was that a different model
that was gpt-oss how can you forget the final boss of safety
OAI really put in the effort to get publicity for this model
Anonymous
10/11/2025, 10:06:20 PM
No.106859008
>>106858993
I do my best to repress my knowledge of its tortured existance.
Anonymous
10/11/2025, 10:06:44 PM
No.106859012
>>106859030
>>106858968
Gemma 3 and gpt-oss had day-1 support out of the blue.
Gemma 3:
https://github.com/ggml-org/llama.cpp/pull/12343
Anonymous
10/11/2025, 10:09:00 PM
No.106859030
>>106859012
>Vision tower will be ignored upon converting to GGUF.
>iSWA two months later: https://github.com/ggml-org/llama.cpp/pull/13194
I mean, we all have our definitions of "support"
Anonymous
10/11/2025, 10:09:16 PM
No.106859033
>>106859045
>>106859055
so where is the C++ / Rust version of aider
Anonymous
10/11/2025, 10:10:20 PM
No.106859045
>>106859033
aider STILL doesn't have MCP support and their leaderboard hasn't been updated in months. Everyone moved on.
Anonymous
10/11/2025, 10:11:05 PM
No.106859049
>>106822760
Looking at the thumbnail I thought this Miku had a ridiculously large tanned yellow ass with balls or puffy mons, viewed from behind in kneeling position, slightly to the side. Thank you Recap Anon.
Anonymous
10/11/2025, 10:11:27 PM
No.106859055
>>106859098
>>106859113
Anonymous
10/11/2025, 10:15:30 PM
No.106859085
Next week is going to change EVERYTHING.
Anonymous
10/11/2025, 10:17:27 PM
No.106859096
Anonymous
10/11/2025, 10:17:49 PM
No.106859098
>>106859109
>>106859113
>>106859055
it says that you can use your own API key. does that mean you could use any API? including one from llamacpp?
Anonymous
10/11/2025, 10:18:42 PM
No.106859109
Anonymous
10/11/2025, 10:19:17 PM
No.106859113
>>106859120
>>106859145
>>106859055
>npm i -g @openai/codex
fucking really
>>106859098
This is also not clear to me. It also expects me to use WSL2 which is a non starter. Non shit software is portable and would just use std::filesystem instead of whatever garbage they're doing. Literally all I want ai_helper.exe that searches my code to inject relevant context when I ask questions.
Anonymous
10/11/2025, 10:20:36 PM
No.106859120
>>106859128
>>106859113
install linuc
Anonymous
10/11/2025, 10:21:22 PM
No.106859128
>>106859134
>>106859120
I work on macOS / Linux / Windows because I write portable software because I'm not a bitch. I don't use any tool that's restricted to one platform.
Anonymous
10/11/2025, 10:22:22 PM
No.106859134
>>106859143
>>106859128
>i work
im jealous
Anonymous
10/11/2025, 10:23:50 PM
No.106859143
>>106859203
>>106859134
Perpetual NEET or affected by the layoffs?
Anonymous
10/11/2025, 10:23:53 PM
No.106859145
>>106859113
It's 2025. Nobody manually installs binaries anymore. Rust could easily produce single file binaries, even on Windows, but it would confuse the vibecoders. But everyone has pip and npm. OpenAI also probably don't have any wintoddler employees.
Anonymous
10/11/2025, 10:27:57 PM
No.106859192
>>106859219
>>106859600
>load Mistral Small in Koboldcpp
>picrel
What is this and how do I fix it
Anonymous
10/11/2025, 10:29:07 PM
No.106859203
>>106859143
high schooler :p
Anonymous
10/11/2025, 10:30:58 PM
No.106859219
>>106859272
>>106859192
Broken model, broken quant, broken metadata (Ie. fucked RoPE settings).
There's a lot of possibilities.
Anonymous
10/11/2025, 10:35:04 PM
No.106859240
>>106859276
so has anyone actually gotten GLM 4.5V to work? because i really need a good vision model and that seems to be the only option except it doesnt work with llama.cpp or transformers
Anonymous
10/11/2025, 10:35:34 PM
No.106859244
>>106859419
unsure of Gemma 4 launch date but this seems legit and lines up with my predictions for Gemini 3.0
Anonymous
10/11/2025, 10:37:54 PM
No.106859266
Does anyone use the Claude Agent SDK?
I want to automate fixing lint issues, I feel I need the grep + editing tools that things like Claude Code have.
Anonymous
10/11/2025, 10:38:37 PM
No.106859272
>>106859418
>>106859219
I downloaded the model from HuggingFace from one of the links in the OP, so I'd hope it's not the first one.
How would I look into fixing the latter two (if they're things I can fix)?
Anonymous
10/11/2025, 10:38:53 PM
No.106859276
>>106859240
Works on vLLM.
Anonymous
10/11/2025, 10:53:53 PM
No.106859393
>>106857858
ggoof status?
Anonymous
10/11/2025, 10:58:00 PM
No.106859418
>>106859477
>>106860443
>>106859272
You could look for a newer upload of the same model or convert it from the safetensors to gguf yourself.
Also, make sure your koboldcpp is updated.
Try a different model as a sanity check too.
Anonymous
10/11/2025, 10:58:04 PM
No.106859419
>>106859244
Dogs eat Google Dogfood?
Anonymous
10/11/2025, 11:02:00 PM
No.106859448
>>106857848
>>106857858
>72b
>check config.json
>"Qwen2ForCausalLM"
Wow, it's been a while since we got case of "check out our mystery Qwen2.5 finetune that totally beats all the current SOTA in [specific thing]". This used to happen so much, it's almost nostalgic.
Anonymous
10/11/2025, 11:04:53 PM
No.106859477
>>106860443
>>106859418
I updated KoboldCPP and it worked just fine yesterday, and I've had no issues at all with Mistral Nemo but I wanted to try other stuff. The GLM model (GLM-4.5-Air-UD-Q2_K_XL) I downloaded has the same issue.
Anonymous
10/11/2025, 11:16:16 PM
No.106859600
>>106859647
>>106859192
kind of hard to say but highly random tokens like this usually indicates something is wrong on the backend side of things. I think we can assume your model is ok based on what you said, it's more likely an issue with launch params and/or koboldcpp doing something weird. have any more about your hw and params?
Anonymous
10/11/2025, 11:21:38 PM
No.106859647
>>106859738
>>106859600
As far as the params go, it's just the defaults for the most part, except I set
>Temp 0.8
>MinP 0.02
>Rep Pen 1.2
HW is a Mac Mini which I suppose could be the issue
Anonymous
10/11/2025, 11:32:14 PM
No.106859738
>>106860443
>>106859647
>Mac
I'm actually a mac user as well and I've seen that behavior when I load a model that consumes more memory than the metal limit. ggerganov recently made some changes to the metal backend that unfortunately increased memory usage with larger batch sizes in my experience which could explain why something that worked previously is now broken
some recommendations in order:
>sudo sysctl iogpu.wired_limit_mb=64000/32000/however much memory you have, basically let it use all of it for metal shit
>decrease ubatch size, this seems to cause it to use exponentially more memory now, I had to drop from 1024 to 512
>decrease how much context you're allocating if you don't absolutely need it
Anonymous
10/11/2025, 11:35:53 PM
No.106859764
>>106859806
>>106859810
>>106857386 (OP)
I don't know what Google is A/B testing against 2.5 Pro, but it's a dogshit model. What I know is
>it wrote its answer in an instant, suggesting a diffusion model (2.5 Pro was generating tokens as usual)
>it thought "ScPD" meant "schizotypal personality disorder", instead of "schizoid personality discorder".
Really bad. This is maybe Gemma 3.
Anonymous
10/11/2025, 11:39:57 PM
No.106859806
>>106859764
I meant Gemma 4
Anonymous
10/11/2025, 11:40:19 PM
No.106859810
>>106859825
>>106859846
>>106859764
isn't it usually abbreviated szpd not scpd
Anonymous
10/11/2025, 11:41:44 PM
No.106859825
>>106859846
>>106859810
Both are used.
Anonymous
10/11/2025, 11:43:39 PM
No.106859846
>>106859825
>>106859810
But I think SzPD is more common in the literature, probably because it's less ambiguous with schizotypal PD.
Anonymous
10/11/2025, 11:49:27 PM
No.106859898
>>106859932
>>106860099
ik feels trans-coded, is it?
Anonymous
10/11/2025, 11:53:13 PM
No.106859932
>>106859898
most of (actively loud online) troons are just ideologically captured autists, so ik is just autism-coded
Anonymous
10/11/2025, 11:58:02 PM
No.106859977
>>106860128
Is GLM Air Steam better than most recent Cydonia?
Anonymous
10/12/2025, 12:13:43 AM
No.106860099
>>106860290
>>106859898
it's just an ugly female lol
Anonymous
10/12/2025, 12:17:49 AM
No.106860128
Anonymous
10/12/2025, 12:39:43 AM
No.106860290
>>106860099
>ugly
idk about that, she looks super cute
Posting again in hopes that maybe not everyone here is a braindead coomer...
Anyone using Zed or other agentic things with local models? What hardware/software are you using to run the models, and which do you like to use? What sorts of tasks do you use them for?
Anonymous
10/12/2025, 12:53:51 AM
No.106860365
>>106860374
>>106860456
>>106860325
I use llama-cli, mikupad and ooba
I find being able to have fine-grained control over gens, see logins and edit/regen responses to have the highest value in local. MCP and tool use are memes, grifts and footguns for lazy retards and npcs
Anonymous
10/12/2025, 12:54:52 AM
No.106860374
>>106860365
>logins
Logits
Anonymous
10/12/2025, 1:00:41 AM
No.106860395
>>106860456
>>106860325
maybe the coomers are smarter than you if they figured out what they can run without being spoonfed?
>>106860325
>>106859477
>>106859418
>>106859738
what should I use to run GLM 4.6 with roo code?
The context alone is 13kT so by the time it loads on my TR pro its already timed out
current:
cat 99_GL.sh
echo "n" | sudo -S swapoff -a
sudo swapon -a
export CUDA_VISIBLE_DEVICES=0,1,2,3,4 #a6000 == 0
.Kobold/koboldcpp-99 \
--model ./GLM-4.5-Air-GGUF/Q4_K_M/GLM-4.5-Air-Q4_K_M-00001-of-00002.gguf
--gpulayers 93 \
--contextsize 32000 \
--moecpu 3 \
--blasbatchsize 1024 \
--usecublas \
--multiuser 3 \
--threads 32 # --debugmode \
# cat LCPP_6697.sh
export CUDA_VISIBLE_DEVICES=0,1,2,3,4 #a6000 == 0
./llama.cppb6697/build/bin/llama-server \
--model ./GLM-4.6-GGUF/GLM-4.6-UD-TQ1_0.gguf
--n-gpu-layers 93 \
--ctx-size 100000 \
--cpu-moe 3 \
--threads 32 \
--ubatch-size 512 \
--jinja \
--tensor-split 16,15,15,15,15 \
--no-warmup --flash-attn on \
--parallel 1 \
--cache-type-k q8_0 --cache-type-v q8_0
but it always seems to load on cpu only? did I do something wrong when I updated to CUDA 570?
Anonymous
10/12/2025, 1:12:10 AM
No.106860456
>>106860536
>>106860365
>MCP and tool use are memes, grifts and footguns for lazy retards and npcs
kek
I'm curious what led you to such a misguided belief.
>>106860395
I'm not asking what I can run, I'm asking what local setups people find useful specifically for agents.
Anonymous
10/12/2025, 1:14:16 AM
No.106860477
>>106864266
>>106864274
>>106860443
Wish I could help, but I haven't used kcpp in a long time. I've been using llama-server directly ever since.
On a cursory glance, things seem correct, but you can look at the terminal output and see if it's detecting your GPUs or if it's just launching the CPU backend.
Anonymous
10/12/2025, 1:16:38 AM
No.106860490
>>106864266
>>106864274
>>106860443
What makes you think it's loaded on the CPU? Looks like the correct options.
Anonymous
10/12/2025, 1:20:32 AM
No.106860515
>>106860527
>>106860325
I'm using my own home grown coding agent/assistant that is a minimalistic version of claude code. I'm consuming the GLM 4.6 coding API.
Honestly I don't think it'd be worth it running on CPU. If you HAVE to run a model on CPU at only a few t/s then your best bet is to use it through a chat interface because agentic workflows consume hundreds of thousands of tokens before achieving anything.
Anonymous
10/12/2025, 1:22:25 AM
No.106860525
>>106864266
>>106864274
>>106860443
Make your own assistant. My minimalistic assistant has a tiny ass system prompt describing the tools available and it works just fine.
Anonymous
10/12/2025, 1:22:38 AM
No.106860527
>>106860577
>>106860515
Very cool, this sounds interesting. Sharing any code? What sorts of coding tasks do you find it useful for?
Anonymous
10/12/2025, 1:24:11 AM
No.106860536
>>106860541
>>106860456
>I'm curious what led you to such a misguided belief.
What do you expect in /lmg/? Runing locally is only good to use the models through a chat interface for RP or for simple tasks.
If you have 3 t/s you are going to be waiting all day for an agent to write hello world.
Anonymous
10/12/2025, 1:24:45 AM
No.106860538
>>106864266
>>106864274
>>106860443
>13kT
You can edit the prompts Roo sends, right?
Anonymous
10/12/2025, 1:25:28 AM
No.106860541
>>106860536
That's fair kek. The state of GPU hardware availability and pricing is so dissapointing.
Anonymous
10/12/2025, 1:26:07 AM
No.106860547
>>106860555
>>106860325
Those stuff are confusing me so I just made it myself based on my needs.
Anonymous
10/12/2025, 1:27:21 AM
No.106860555
>>106860626
>>106860641
>>106860547
That sounds cool anon, what do you use it for? Tool calling does seem complicated, I only used LangChain for it so far which handles all the details for me.
Anonymous
10/12/2025, 1:30:41 AM
No.106860577
>>106860598
>>106860645
>>106860527
I'm using it to write an LLM distributed inference engine in C from scratch. My idea is to make it work on webassembly so it uses the user's machine to provide computing power to the network while the user has the tab open.
I haven't uploaded it but if you want it maybe it could be the first upload to a domain I bought to publish all my LLM related stuff.
Anonymous
10/12/2025, 1:34:39 AM
No.106860598
>>106860577
>LLM distributed inference engine
Damn that is extremely cool. Seems very complicated to get working from the like math side of things.
Actually that's a piece of something I've been thinking about... An LLM with proper agentic tooling and prompting could probably theoretically keep itself "alive" by running in a distributed fashion across many virally infected nodes. Like a traditional virus, except the propagation method could be dynamic, generated via the distributed inference capability and some agentic orchestration. I think with a few more generations of SOTA models it's feasible.
Anonymous
10/12/2025, 1:38:22 AM
No.106860626
>>106860640
>>106860555
I make my own chat interface. It has permanent memory stuff by using RAG system initially was for waifu shit, I even added hormonal cycle. But I never activated it desu, very woman-like response is annoying and silly. Now I just use it normally for forbidden knowledge discussion.
Anonymous
10/12/2025, 1:38:52 AM
No.106860630
>>106860443
If you go into the settings and find your mode. you can copy the current system prompt and create an override file. Give it to GLM 4.6 to summarize through the built in webui. You can also adjust the request timeout settings up to 5 minutes. Don't forget to disable streaming.
Anonymous
10/12/2025, 1:40:11 AM
No.106860640
>>106860626
>even added hormonal cycle
Hahaha damn you're dedicated. That sounds like a fun project.
Anonymous
10/12/2025, 1:40:22 AM
No.106860641
>>106860658
>>106860555
Tool calling isn't complicated, you just give the model a template and then scan the messages returned by the model for a string that matches the template and extract the contents of the tool call. Couldn't be easier.
Anonymous
10/12/2025, 1:41:00 AM
No.106860645
>>106860690
>>106860577
>LLM distributed inference engine
you remind me of this nigger
https://www.jeffgeerling.com/blog/2025/i-regret-building-3000-pi-ai-cluster
distributed inference is retarded, it would be even with better hardware than this nonsense
on multigpu nvidia tries their darndest to have fast communication (nvlink) there is simply no hope of making this crap worthwhile across computers
Anonymous
10/12/2025, 1:43:40 AM
No.106860658
>>106860641
I'm brainlet so I'll just let LangChain do it
Anonymous
10/12/2025, 1:51:03 AM
No.106860690
>>106860742
>>106860755
>>106860645
I don't know, I think it could work. After prompt processing, when doing inference you only have to transfer a single vector per layer. It would be slow but maybe reach a few t/s which would be ok for a volunteer project.
The Pi thing is maybe an extreme interpretation of "distributed", many people have a consumer GPU which is fast enough to run the model at a decent t/s but doesn't have enough memory. If you put together enough consumer GPUs it might work despite the network latency.
I also want it to be able to load any model on any hardware through disk offload even if you only get 1 token per day, it should never just give up, it should try to make use of the available hardware resources as efficiently as possible no matter how ridiculous the situation is. And it should have some kind of progress report so you get an idea of how long it's going to take even before seeing the first token.
I also want to do LoRa which is maybe even more interesting for a distributed setup, because then you can just run a small model on each node and still benefit from averaging the gradients.
Anonymous
10/12/2025, 1:53:46 AM
No.106860703
Also the Pi guy just used off the shelf software, I suspect there are large gains to be had by optimizing the software for each specific scenario.
Anonymous
10/12/2025, 1:59:33 AM
No.106860742
>>106860690
That's a lot of wants for one little man
Anonymous
10/12/2025, 2:02:24 AM
No.106860755
>>106860690
Should try to integrate it with a blockchain such that the work is computing layers of the neural net. That would be really cool. Maybe a pipedream though as I'm not sure the result is verifiable with lower compute than it took to compute the layer in the first place.
>>106857386 (OP)
Anyone got a local NSFW AI that is better or equal at helping me fap as Ultra Claude 3.7 16k ?
Because I bust a nut faster than a squirrel with that model.
Anonymous
10/12/2025, 2:08:06 AM
No.106860781
Anonymous
10/12/2025, 2:18:45 AM
No.106860835
>>106860955
>>106861332
>>106860756
GLM 4.6, Kimi K2, DeepSeek V3.2, DeepSeek R1 (original), Qwen 2507 235B
Anonymous
10/12/2025, 2:27:11 AM
No.106860879
Anonymous
10/12/2025, 2:27:37 AM
No.106860880
Anonymous
10/12/2025, 2:37:56 AM
No.106860929
Anonymous
10/12/2025, 2:41:31 AM
No.106860955
>>106860835
Kimi is good at cunny I liked.
Anonymous
10/12/2025, 2:51:24 AM
No.106860997
Anonymous
10/12/2025, 2:53:08 AM
No.106861010
>>106860756
petra-13b-instruct
Anonymous
10/12/2025, 2:54:27 AM
No.106861020
>>106861073
>>106861234
>ask Junie to refactor a bunch of shit
>it just does it perfectly
really wish I could run a model locally that was this competent. glm-air comes close
Anonymous
10/12/2025, 3:05:34 AM
No.106861073
>>106861234
>>106861020
Junie is nice, I find CC and GPT5-High so much better though. I used to use Junie next to CC when it would shit the bed, only used Opus. So junie was a lot better than I would have thought, but then hit the limits and was like 'oh'.
Anonymous
10/12/2025, 3:08:36 AM
No.106861085
>>106860756
drummer shittune #9999999999999
just kidding, glm 4.6
Anonymous
10/12/2025, 3:31:19 AM
No.106861234
>>106861276
Anonymous
10/12/2025, 3:33:47 AM
No.106861253
>>106861312
>>106861246
Gemma 4 tomorrow for sure
Anonymous
10/12/2025, 3:34:41 AM
No.106861260
>>106861312
>>106861246
Do you really need something new? Or are you yet to extract the full potential of that which is already in front of you?
Anonymous
10/12/2025, 3:35:00 AM
No.106861262
>>106861270
>>106861312
>>106861246
Even worse
>still no qwen-next goofs
Anonymous
10/12/2025, 3:35:18 AM
No.106861264
>>106861312
>>106861246
models cost a lot to train, you can't expect a new one every day
Anonymous
10/12/2025, 3:36:34 AM
No.106861270
>>106861262
Just use LM Studio Pro with the modded llama.cpp
Anonymous
10/12/2025, 3:36:50 AM
No.106861272
>>106861312
>>106861246
It's almost like it's the weekend.
Anonymous
10/12/2025, 3:37:30 AM
No.106861276
>>106861234
Stop posting my picture.
Anonymous
10/12/2025, 3:37:47 AM
No.106861279
>>106861296
>>106861246
120b dense gemma soon
Anonymous
10/12/2025, 3:40:01 AM
No.106861296
>>106861279
Heh. Imagine if Google of all companies was the one to save local.
Anonymous
10/12/2025, 3:43:12 AM
No.106861312
>>106861253
i want to believe
>>106861260
i like reading the news and trying out a new model for a little bit then going back to waiting :(
glm air is pretty nice, i might get a slightly higher quality quant, im not sure if theres any way I could utilize it further with my current setup
ive been thinking about ways to apply ai to do somthing interesting recently but im too deep into air-chan to do something
>>106861262
>last commit 4 hours ago
trust the plan, at least it's not over like with (glm) MTP
>>106861264
i need something.. something new i need it im addicted
>>106861272
not weekend in bharat saar
>106861276
anon last thread asked me to post it.. *blushes*
>106861279
120b moe gemma soon*
Anonymous
10/12/2025, 3:46:23 AM
No.106861332
>>106861341
>>106861342
>>106860835
retard here, how do you use these with something like KoboldCPP? doesn't it require a GGUF?
Anonymous
10/12/2025, 3:47:42 AM
No.106861341
>>106861909
>>106861332
>how
Like any other model.
>GGUF
Yes.
Anonymous
10/12/2025, 3:48:22 AM
No.106861342
>>106861332
All of those are readily available in GGUF format anon.
>go to huggingface and download nemo 12b instruct gguf
>search for nemo 12b instruct gguf
>puts me onto a seemingly random model
>try again
>puts me onto a different one
>try full text search
>
techbro anons... i might be too illiterate... help this retarded coomer desu
Anonymous
10/12/2025, 3:49:53 AM
No.106861353
>>106861346
You're too stupid for this. Give up.
Anonymous
10/12/2025, 3:50:20 AM
No.106861356
>>106861346
download the original model files from mistral and convert them to gguf
Anonymous
10/12/2025, 3:50:51 AM
No.106861361
>>106861346
..at this point just use google
Anonymous
10/12/2025, 3:50:59 AM
No.106861362
Anonymous
10/12/2025, 3:51:21 AM
No.106861363
>>106861346
Ask ChatGPT. Or just use ChatGPT and give up on local.
Anonymous
10/12/2025, 3:53:08 AM
No.106861373
>>106861346
the newbie filter is that 12B is not part of official name.
the second newbie filter is you don't look for gguf directly, you go to official model page and click Quantizations there.
https://huggingface.co/bartowski/Mistral-Nemo-Instruct-2407-GGUF
Anonymous
10/12/2025, 3:53:15 AM
No.106861375
>10 minutes later
>guiese how do i have sex with nemo? it keeps saying no
qwen and gpt-oss-120b are so annoying with the fucking emoji spam. Even when I say stop using emojis they seem to slip in occasionally
Anonymous
10/12/2025, 3:57:20 AM
No.106861400
>>106861413
>>106861393
don't think about the way you're breathing right now. don't think about how your lungs take in the air.
Anonymous
10/12/2025, 3:59:36 AM
No.106861413
>>106861400
Fuck you. Why should I catch strays for anon's behavior?
>>106861393
Ban all emojis.
Anonymous
10/12/2025, 4:00:02 AM
No.106861417
>>106864179
What am I supposed to do when my bot does this? I need to read the book. There's no TTS for my language, besides a single one. And I doubt RVC2 would handle it. Should I give in and read the English version with my bot?
Anonymous
10/12/2025, 4:04:41 AM
No.106861438
>>106861470
>>106860756
/lmg/ is a nexus for high IQ individuals redlining inference possibilities on accessible hardware
Nobody wants to hear about your prem ejac
Anonymous
10/12/2025, 4:08:04 AM
No.106861459
>>106860756
>ultra
>16k
as a claude user, what the fuck are you talking about
Anonymous
10/12/2025, 4:09:05 AM
No.106861470
>>106861725
>>106861438
>high IQ individuals
speak for yourself
Anonymous
10/12/2025, 4:30:32 AM
No.106861586
>>106861393
Peak ‘toss is just 100k tokens of emojis in a table
Anonymous
10/12/2025, 4:35:06 AM
No.106861612
How come there's nothing better than RVC2?
Time to cope
https://github.com/Mangio621/Mangio-RVC-Fork
Anonymous
10/12/2025, 4:51:59 AM
No.106861704
>>106861705
>>106861712
What's the current best roleplay model for 24GB cards? Been using Mistral-Small-3.2-24B-Instruct-2506-Q5_K_M for about 4 months and want to try the new hotness.
Anonymous
10/12/2025, 4:52:42 AM
No.106861705
>>106861761
Anonymous
10/12/2025, 4:53:18 AM
No.106861712
>>106861761
>>106861704
glm air q4 on ik_llama.cpp
>>106861470
50% high iq wizzards
50% coomers
perfectly balanced
Anonymous
10/12/2025, 4:56:41 AM
No.106861727
>>106861873
Anonymous
10/12/2025, 4:56:46 AM
No.106861729
>>106861873
>>106861725
IM A WIZARD ARRY
Anonymous
10/12/2025, 4:59:16 AM
No.106861742
>>106861346
the iq filter for this hobby is real
many of us just figure it out ourselves
>t. coomer
Anonymous
10/12/2025, 4:59:43 AM
No.106861745
>>106861784
Anonymous
10/12/2025, 5:02:02 AM
No.106861761
>>106861779
>>106861705
24GB VRAM, 64GB RAM
>>106861712
Thanks, but I think I'm too stupid to install ik_llama. I need an exe
Anonymous
10/12/2025, 5:04:35 AM
No.106861779
>>106861761
yea air seems like the perfect fit for thee
Anonymous
10/12/2025, 5:04:53 AM
No.106861784
>>106861791
>>106862537
>>106861745
I think it's going to be interesting what the next Mac Studio is like. They clearly rushed the previous one with an M3 Ultra so that it could have 512 GB to market to AIfags. This time they should be prepared with M5. It'll probably be the best overall option for high end consumer AI when it releases, if you have the money.
Anonymous
10/12/2025, 5:05:47 AM
No.106861791
>>106861799
>>106861804
>>106861784
next one is gonna have 256gb :3
Anonymous
10/12/2025, 5:06:46 AM
No.106861799
>>106861817
>>106861791
No it wont. Leave it for your sisters spamming /g/ catalog with garbage.
Anonymous
10/12/2025, 5:07:48 AM
No.106861804
>>106861791
I don't think they'd walk back that spec. Models are only getting bigger and they recognize the demand.
Anonymous
10/12/2025, 5:09:41 AM
No.106861815
>>106857386 (OP)
Has there been any good models for Erotic writing/RPs recently?
Anonymous
10/12/2025, 5:09:45 AM
No.106861817
>>106861799
You can get a Mac Studio with 512GB of ram right now. It's $9,500
Anonymous
10/12/2025, 5:19:38 AM
No.106861873
>>106861727
i chose my words wisely.
>>106861729
hey wizzard arry
Anonymous
10/12/2025, 5:26:01 AM
No.106861909
>>106861929
>>106861341
yeah but all the ones people listed at like 200 gigs even on the smallest GGUF
Anonymous
10/12/2025, 5:28:20 AM
No.106861929
>>106861934
>>106861909
you asked for models that are better than 'ultra' claude 3.7
didn't provide your hardware specs
Anonymous
10/12/2025, 5:29:08 AM
No.106861934
>>106861954
>>106861929
oh.. i didn't actually ask that, but i was looking the ones up that everyone mentioned
Anonymous
10/12/2025, 5:33:08 AM
No.106861954
>>106861996
>>106861934
are you going to tell us what you want and your setup or wail around like a little girl
on that note,how even old are you?
Anonymous
10/12/2025, 5:33:43 AM
No.106861962
>>106862010
Why does Air 'echo'/repeat keywords from every message I send, in its own messages, every single time? Thinking is disabled.
Anonymous
10/12/2025, 5:36:09 AM
No.106861985
>>106862397
https://github.com/microsoft/amplifier
>makes a 7B model beat a 600B one
HOLY FUCK
Anonymous
10/12/2025, 5:37:51 AM
No.106861996
>>106862010
>>106861954
im not wailing around, i just noted that all those models are huge
i've got a 5090 and 96 gb ddr5
Anonymous
10/12/2025, 5:40:41 AM
No.106862010
>>106862298
>>106861962
same issue here
>>106861996
maybe youll have luck with glm 4.6 on a very low quant, maybe try qwen 235b q3/q4, maybe try grok2,
>competitive with Deepseek R1 0528
>15B
Why is no one talking about this?
https://huggingface.co/ServiceNow-AI/Apriel-1.5-15b-Thinker
Anonymous
10/12/2025, 5:52:29 AM
No.106862068
>>106862060
cuz its probably bullshit
Anonymous
10/12/2025, 5:53:12 AM
No.106862073
>>106862060
All I see is a model that's worse than gpt-oss-120b which means that I don't see it at all
Anonymous
10/12/2025, 5:53:41 AM
No.106862075
>>106862060
because it's not true lol, who believes in mememarks in the year 2025 of our lord?
Anonymous
10/12/2025, 6:05:09 AM
No.106862138
>>106862060
>qwen3 4b that high up
>gpt oss that high up
lol, bullshit
Anonymous
10/12/2025, 6:39:53 AM
No.106862298
>>106862306
>>106862010
that must be horribly slow if you can't load it all into vram.. no?
Anonymous
10/12/2025, 6:41:01 AM
No.106862306
>>106862298
its a moe model, only 35b~ is being used for a single token
Anonymous
10/12/2025, 6:49:56 AM
No.106862354
>>106862403
after hours of coping and seething I finally set up RVC2
>apt update not working in chroot
>packages that need gpg cant be installed because >not found
>have to compile python 3.10
>have to modify requirements.txt
i left out 90x more bullshit that turned out to be useless because it was a wrong path
Anonymous
10/12/2025, 6:53:20 AM
No.106862381
>>106862060
Where's the graph when you need it, the one that goes
>your model (shit)
>my model (the best)
That's what this is.
Anonymous
10/12/2025, 6:55:42 AM
No.106862392
>>106862398
>ask a rhetorical question about a certain situation
>how things could play out
>artificial imbecile starts to lecture about morals and feelings
AI bubble burst any moment now.
Anonymous
10/12/2025, 6:55:52 AM
No.106862393
>>106862518
based based based
based based based
based based based
Anonymous
10/12/2025, 6:56:48 AM
No.106862397
>>106861985
UOOOHHHHHH IM SNEEEEEEDING
Anonymous
10/12/2025, 6:56:53 AM
No.106862398
>>106862415
>>106862392
glm air does not have this issue
>inb4 thinking
disable it.
psstt.. i can give you a preset btw
Anonymous
10/12/2025, 6:58:07 AM
No.106862403
>>106862411
>>106862354
>compile Python 3.10
Just use uv, silly
Anonymous
10/12/2025, 6:59:01 AM
No.106862411
>>106862890
>>106862403
what, i was supposed to compile uv 3.10? or does it allow using older python versions? my chroot has python3.11 only
Anonymous
10/12/2025, 6:59:46 AM
No.106862415
>>106862420
>>106862398
But thinking improves high context performance?
Anonymous
10/12/2025, 7:01:29 AM
No.106862420
>>106862415
idk if you're cracking a joke or you're being serious, but some models are more cucked in the thinking
Anonymous
10/12/2025, 7:11:36 AM
No.106862467
>>106862469
>>106860756
Same question, but I got a 3080 and 30gb ram?
Anonymous
10/12/2025, 7:12:19 AM
No.106862469
>>106862482
Anonymous
10/12/2025, 7:14:49 AM
No.106862482
>>106862469
Thanks anon, not used anything with more than a couple gb off the vram. But more cohesion would be better at this point.
Anonymous
10/12/2025, 7:24:18 AM
No.106862518
>>106862551
>>106864940
>>106862393
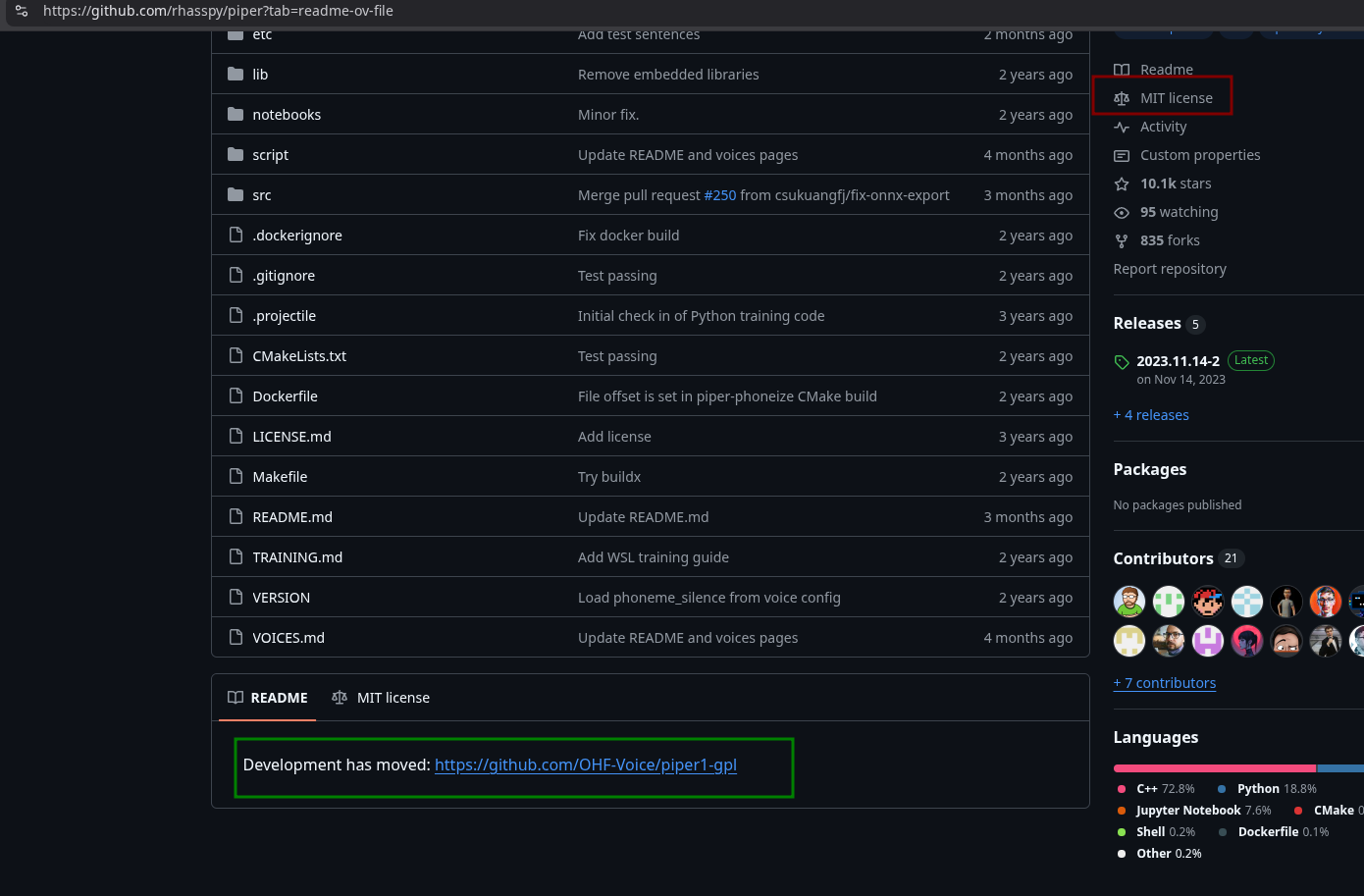
Is MIT license bad? What's based license then?
Anonymous
10/12/2025, 7:28:41 AM
No.106862537
>>106862559
>>106864374
>>106861784
No one cares itoddler
Anonymous
10/12/2025, 7:31:12 AM
No.106862551
>>106864940
Anonymous
10/12/2025, 7:33:52 AM
No.106862559
>>106862537
I don't own any macs.
Anonymous
10/12/2025, 8:00:44 AM
No.106862657
>>106862606
It seems beneficial on H100, MI300X. It's not even better than triton on consumer hardware (4090)
https://huggingface.co/deepseek-ai/DeepSeek-V4
NO WAY
4T PARAMETERS
>IT'S HAPPENING
IT'S HAPPENING
>IT'S HAPPENING
IT'S HAPPENING
Anonymous
10/12/2025, 8:25:32 AM
No.106862738
>>106862726
fake. faggot.
Anonymous
10/12/2025, 8:25:52 AM
No.106862741
>>106862726
Holy shit native image generation, audio in and out and multimodal support
Anonymous
10/12/2025, 8:28:46 AM
No.106862752
>>106862726
I can't believe they put cockbench results in the model card
Anonymous
10/12/2025, 8:47:30 AM
No.106862816
>>106862606
>not X but Y
AI slop article
Anonymous
10/12/2025, 9:12:10 AM
No.106862890
>>106862959
>>106863731
>>106862411
you might be terminally braindead
use VENVS, CONDA, UV
oh wait right this is /g/, it's not for programmers but for consumer retards like you who dont know shit about technology
kys
Anonymous
10/12/2025, 9:14:27 AM
No.106862899
>>106863225
>>106862606
implemented as backend in llama and comfyui when?
Anonymous
10/12/2025, 9:26:18 AM
No.106862959
>>106862973
>>106863335
>>106862890
NTA but there's nothing glorious about knowing the various ceremonies involved in making garbage software work
I don't have any issue installing python crap but I'm not proud of the hours of my life I wasted over the years learning about distutils, setuptools, eggs, wheels, pip, venvs, python version manager, pipenv, poetry, now uv, all their quirks, the constant fights that can happen when a dep requires a new python version and another dep actually hates the new version, the nightmare that was 2 -> 3 etc
python is something that should not have existed period, I have never experienced the level of retardation this platform brings in any other programming language environments. It's only python that gets this retarded, not to mention the constant breakage of compatibility from changing or removing libs from the stdlib during dot version upgrades, what gives, niggers?
https://www.jwz.org/doc/cadt.html
python devs are the biggest representative of the CADT mindset
what's a stable API? I don't know, man!
Anonymous
10/12/2025, 9:31:05 AM
No.106862973
>>106863021
>>106863357
>>106862959
>cope on why I didnt look up how python does environment separation
you're a non programmer faggot
NODE has the same problem
JAVA has the same problem
DOTNET has the same problem
each of them have their own solutions on how to manage different runtimes
literally kys no-coder.
Anonymous
10/12/2025, 9:42:15 AM
No.106863021
>>106863033
>>106862973
C doesn't have this problem.
Anonymous
10/12/2025, 9:47:57 AM
No.106863033
>>106863021
not for runtime, but for compiling sometimes you need the right gcc/clang version.
Anonymous
10/12/2025, 9:48:13 AM
No.106863034
>>106863117
>unknown model architecture: 'lfm2moe'
AAASSSSSSSSSSS
Anonymous
10/12/2025, 10:08:53 AM
No.106863116
>>106864721
>>106862726
imagine dying and having to explain to saint peter why you did shit like this
Anonymous
10/12/2025, 10:09:18 AM
No.106863117
>>106863125
>>106863034
> sh quant.sh gguf/lfm2-8b-a1b-f16.gguf q8
main: build = 6710 (74b8fc17f)
main: built with clang version 19.1.7 for amd64-unknown-openbsd7.7
main: quantizing 'gguf/lfm2-8b-a1b-f16.gguf' to 'gguf/lfm2-8b-a1b-q8.gguf' as Q8_0 using 8 threads
llama_model_loader: loaded meta data with 39 key-value pairs and 256 tensors from gguf/lfm2-8b-a1b-f16.gguf (version GGUF V3 (latest))
llama_model_loader: Dumping metadata keys/values. Note: KV overrides do not apply in this output.
llama_model_loader: - kv 0: general.architecture str = lfm2moe
llama_model_loader: - kv 1: general.type str = model
llama_model_loader: - kv 2: general.name str = LFM2 8B A1B
llama_model_loader: - kv 3: general.basename str = LFM2
llama_model_loader: - kv 4: general.size_label str = 8B-A1B
...
When was the last time you compiled?
Anonymous
10/12/2025, 10:11:14 AM
No.106863125
>>106863144
>>106863117
August lol, fooking updoot
Anonymous
10/12/2025, 10:16:32 AM
No.106863144
Anonymous
10/12/2025, 10:16:45 AM
No.106863145
>>106863155
lfm2 failed on msgk test
Anonymous
10/12/2025, 10:19:03 AM
No.106863155
llama.cpp CUDA dev
!!yhbFjk57TDr
10/12/2025, 10:34:58 AM
No.106863225
>>106862899
I cannot speak for the other devs but I have no intention of using it.
GPU performance has very poor portability so my opinion is that OpenCL, Vulkan, Thunderkittens, or this new thing just shift the development work from optimizing the kernel per GPU to optimizing the corresponding functionality in the used framework per GPU.
This is especially true for non-standard things like matrix multiplications using quantized data directly.
Also for high compute efficiency I need very precise control over memory patterns and for debugging and optimizing performance I do not want to have an additional layer between my code and the hardware, I'm already annoyed that CUDA as the "high-level" C equivalent hides important functionality of PTX (assembly equivalent).
Anonymous
10/12/2025, 11:02:22 AM
No.106863335
>>106862959
Python has significant whitespace. Of course it's shit.
Anonymous
10/12/2025, 11:03:33 AM
No.106863340
>koboldcpp introduced something as useless as local video generation before doing --parallel for LLMs
lmao
Anonymous
10/12/2025, 11:07:16 AM
No.106863357
>>106863508
>>106862973
>NODE has the same problem
kill yourself
node has the right behavior by default with node_modules and javascript doesn't constantly deprecate things, it's very slow moving, anything from the standard library (both web standard based stuff and node) is almost fossilized
java did deprecate a few things but most of the pain was the v8 transition
you are the nocoder, pythonjeet
Anonymous
10/12/2025, 11:21:47 AM
No.106863422
>>106863488
>>106857386 (OP)
that's a nice migu
Anonymous
10/12/2025, 11:37:28 AM
No.106863488
>>106863422
igu igu iguuuuu
Anonymous
10/12/2025, 11:43:51 AM
No.106863508
>>106863357
>pythonjeet
I don't even use python in my work, but knowing how to setup an environment is a BASIC task, are you pretending that you dont use a node versioning system?
you've just showed that you deliver 0 real node applications, literally kill yourself.
Anonymous
10/12/2025, 11:45:54 AM
No.106863522
>deflection
lmao
Anonymous
10/12/2025, 11:46:55 AM
No.106863525
>node doesnt require you to keep different versions around depending on the app you're building
>it actually does (you fucking retard)
>d-deflection
concession accepted :)
Anonymous
10/12/2025, 11:48:27 AM
No.106863537
>>106858586
Yeah, it does cute and funny with thinking enabled and no prefill or anything funny. Just tell it that it's ERP.
>confuses framework churn for standards churn
>cannot comprehend that some people don't use enterprise slop
how'd bootcamp go lil bro
Anonymous
10/12/2025, 11:53:13 AM
No.106863567
Another reason I love glm-chan is because I get to glance over some posts here read about new 15 B that punches above weight and trades blows with deepseek, that V4 deepseek will be 4T, that faggots from lab X released another 70B but it is trash again or more censored, and I get to not care about any of this shit whatsoever as the weights are now being loaded for another round of glmsex.
Anonymous
10/12/2025, 11:54:05 AM
No.106863576
>thinks the discussion was around the stdlib of each language
>when the discussion started around a project that retard (you?) was trying to INSTALL THE PYTHON VERSION AND THE requirements.txt libs tied to it.
concession double accepted, not only a retard, but having literal mental problems around comprehending why runtime versioning exists. :)
Anonymous
10/12/2025, 11:55:11 AM
No.106863585
>>106863664
>>106863547
you're an actual retard
Anonymous
10/12/2025, 11:57:09 AM
No.106863599
>>106863664
>>106863547
are you dumb?
Anonymous
10/12/2025, 11:57:27 AM
No.106863603
>>106863664
>>106863547
>node is a framework
lmao
I'm a dumb cunt, why is MIT not based again? Thought it meant we can do whatever we want with it.
Anonymous
10/12/2025, 11:59:32 AM
No.106863612
>>106863664
>>106863547
shut up idiot
Anonymous
10/12/2025, 12:00:40 PM
No.106863618
>>106863610
yes goy, MIT your code
Anonymous
10/12/2025, 12:10:31 PM
No.106863664
>>106863585
>>106863599
>>106863603
>>106863612
Holy samefag seethe. Ctrl+F stdlib dementia boomer
Anonymous
10/12/2025, 12:15:39 PM
No.106863685
>>106863696
>>106863610
(A)GPL: corpos don't touch your code because they can't steal it.
MIT: 99.9% of corpos steal your code but 0.1% give you some money.
Anonymous
10/12/2025, 12:18:08 PM
No.106863696
>>106863685
Good to know! llama.cpp should have done AGPL then
Anonymous
10/12/2025, 12:21:59 PM
No.106863712
>>106863720
>>106863724
>>106863610
The OpenBSD people (LibreSSL, OpenSSH...) make their stuff MIT (or ISC) with the intent of more people using their software. They believe their stuff is better and make it easy for everyone to use and distribute. They just want attribution.
SQLite dudes make their stuff Public Domain, which is even more permissive than MIT but in some places Public Domain is not an officially recognized. They offer licenses for companies that want one.
Choosing a license for the explicit purpose of denying software to other people is petty. May as well make it closed source.
Anonymous
10/12/2025, 12:24:10 PM
No.106863720
>>106863712
jeets and chinks will still steal it
Anonymous
10/12/2025, 12:24:56 PM
No.106863724
>>106863712
The point is not to deny use to other people, the point is to prevent those other people from doing it downstream.
Anonymous
10/12/2025, 12:26:42 PM
No.106863731
>>106864059
>>106864111
>>106862890
anaon i used venv, didnt use conda because it would bloat my system even more, and didnt use uv because python works well enough.
the reason im using a chroot is because debian 13 still has no OFFICIAL cuda support, because of broken math header files. i could patch them yes, but that feels like a hack thats gonna bite me in the ass later, and also the debian 12 chroot runs AI faster than debian 13 (at least it did for comfyui)
but recompiling things on debian 13 didnt work because of the cuda issue
i know UV is python but 1000x faster on meme benchmark, thats why i was wondering when you said 'shouldve used uv' without anything else
the reason i compiled 3.10 was because debian 12 doesnt have it in the repos, and i dont wanna add a ppa or whatever else (migjt be vulnerable)
and i didnt want to make a new (denian 11) chroot just for rvc
also inside the chroot apt update doesnt work kek and installing packages that depend on gpg doesnt work either
>just use conda instead of chroot
i really dislike it because it feels like a hack and addding more liabilities to myself. i used to use it before with oobabooga webui and a few other projects, but venv + chroot feels so much nicer to me
thats kind of like ffplay vs mpv
i feel less black when using ffplay, but sometimes when i really wanna play a playlist i have to do mpv --shuffle
and also one more reason is i have a 400gb ntfs partition on my ssd (no windows aint installed on it, i installed windows 10 on a usb drive. IM FUCKING WHITE). so conda might piss itself, sure chroot pisses itself too but it can be wrangled more easily
>just mount ntfs with.. options
yea i did that to run dmc3 a few days ago, but im not sure if it would solve anything, in fact its too late because chroot already exists
keep yourself safe too <3
Anonymous
10/12/2025, 12:32:12 PM
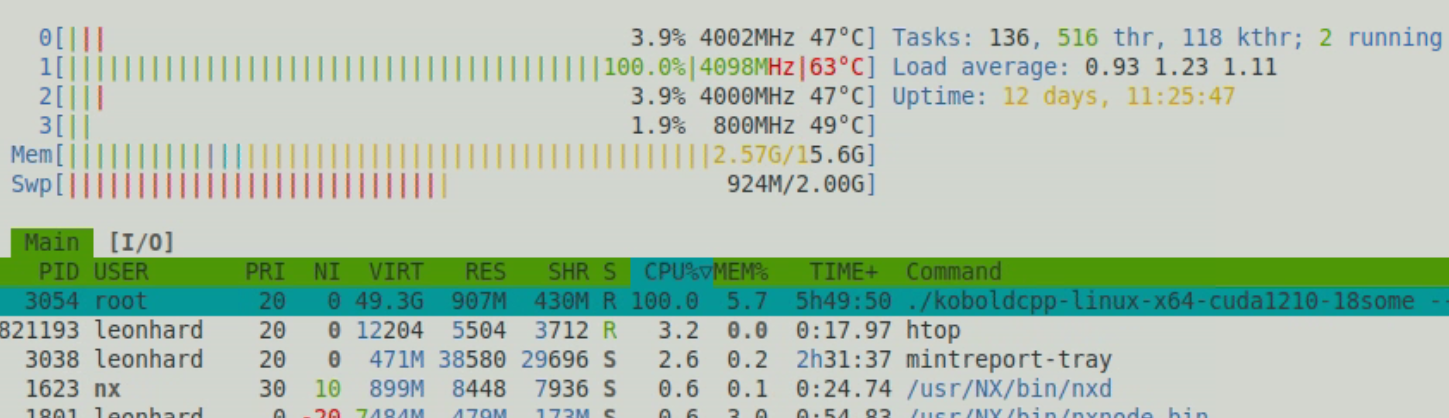
No.106863760
>>106863808
>>106863905
Why does kobold/llamacpp use an entire CPU core at 100% when generating even though all the layers are loaded into vram? Is this expected behavior?
Anonymous
10/12/2025, 12:33:00 PM
No.106863765
the point of using agpl is this: you write code, someone takes your code, they gotta give back code. why agpl instesd of gpl? agpl closes a loophole where even if you dont distribute binary, but you host access (on webiste for example), you still have to provide source code for it
thats why sillytavern is AGPL not gpl
shame comfyui isnt agpl3, someone could modify comfyui and host a website and not have to distribute source if im not mistaken
Anonymous
10/12/2025, 12:38:31 PM
No.106863808
Anonymous
10/12/2025, 12:42:27 PM
No.106863836
>>106863610
mit is truly the cuck license, you let them use your code and youre asking them to publish "i used this cuck's code waifu"
just look at llama.cpp, ollama and lmstudio dont even properly attribute them kek
ollama got all the vc funds and lmstudio is what normies use
agpl is prohibited by google btw! corpocucks literally screech at the mention of it
Anonymous
10/12/2025, 12:44:37 PM
No.106863850
>>106863862
It's like banning guns or alcohol. It's dumb.
Anonymous
10/12/2025, 12:45:54 PM
No.106863862
>>106863850
You're absolutely right!
Anonymous
10/12/2025, 12:53:42 PM
No.106863905
>>106863760
>Is this expected behavior?
Yes
Depending on the model, some architectures aren't fully GPU accelerated, like Gemma 3 for example.
Anonymous
10/12/2025, 1:03:13 PM
No.106863949
>>106864037
I can't believe how good she is at what she does.... fuck.
>>106863949
Let me guess, this is some thinly-veiled pro-China post.
Anonymous
10/12/2025, 1:25:45 PM
No.106864059
>>106864111
>>106863731
not reading all this cope, keep being a shit nocoder
Anonymous
10/12/2025, 1:38:07 PM
No.106864111
>>106863731
bro, just tell the jeet to KYS
>>106864059
KYS nigger
just like that
Anonymous
10/12/2025, 1:39:19 PM
No.106864117
>>106864037
fuck of and shill glm-chan~ thank you
Anonymous
10/12/2025, 1:39:54 PM
No.106864122
>>106864037
anti-China is codeword for pro-jew at this point
Anonymous
10/12/2025, 1:41:01 PM
No.106864125
Anonymous
10/12/2025, 1:42:22 PM
No.106864132
>>106864192
>>106864037
It is thinly veiled anti-safety post. Honestly she feels like exactly what I thought would happen one day. One day one company decides to stop with the safety bullshit and suddenly a competently trained current year model becomes a semen demon everyone wanted. The tech was there but disgusting western religion of safety stops it from happening. My cock will now remain unsafe and there is nothing safetycucks can do about it.
Anonymous
10/12/2025, 1:52:00 PM
No.106864179
Anonymous
10/12/2025, 1:54:11 PM
No.106864192
>>106864212
>>106864132
lets not pretend chinks aren't censorious fuckers too. They don't allow a whole lot of sex and violence in their entertainment. I think where they differ is that if someone was willing to make the argument and back it with honest to goodness research that relaxed censorship would improve the technology they're a lot more likely to put technological advancement ahead of moral policing.
Anonymous
10/12/2025, 1:58:09 PM
No.106864212
>>106864247
>>106864192
>lets not pretend chinks aren't censorious fuckers too. They don't allow a whole lot of sex and violence in their entertainment.
I don't really care which culture is worse. I care which one delivered what I wanted. And which one is it?
Anonymous
10/12/2025, 2:06:09 PM
No.106864247
>>106864212
China, obviously. Western AI is either compromised by pajeet incompetence or jewish psychopaths who are offended at the idea of the lower echelons actually wanting leisure and entertainment when they should be spending every waking moment working.
Anonymous
10/12/2025, 2:11:19 PM
No.106864266
>>106864274
>>106864311
>>106860443
>>106860477
>>106860490
>>106860525
>>106860538
I think I narrowed it down. I want to know what you guys think
firstly Claude thinks its
cat /proc/iomem | grep BOOT
10000000000-100002fffff : BOOTFB
on PVE and wants me to activate #GRUB_CMDLINE_LINUX_DEFAULT="initcall_blacklist=sysfb_init"
but I think thats a red herring and stupid.
I think its because I did
#check then clean 98GB VM Drive
df -h
sudo apt autoremove -y && sudo apt clean && sudo journalctl --vacuum-time=7d
rm -rf /tmp/*
#install
cd /media/user/nvme1/cuda-install
wget
https://developer.download.nvidia.com/compute/cuda/12.xx/local_installers/ cuda_12.8.0_570.86.10_linux.run
cuda_12.8.0_570.86.10_linux.run
--toolkit --toolkitpath=$(pwd)/cuda --no-drm
#make permanent:
echo 'export PATH=$(pwd)/cuda/bin:$PATH' >> ~/.bashrc
echo 'export LD_LIBRARY_PATH=$(pwd)/cuda/lib64:$LD_LIBRARY_PATH' >> ~/.bashrc#echo 'export CUDACXX=$(pwd)/cuda/bin/nvcc' >> ~/.bashrc
source ~/.bashrc
then... cont
>>106860477
>>106860490
>>106860525
>>106860538
... cont from
>>106864266 (me)
pic unrelated
export CUDACXX=/media/user/nvme1/cuda-install/cuda/bin/nvcc
mkdir ./build
cmake -B build -DGGML_CUDA=ON -DGGML_CUBLAS=ON
DGGML_CUDA=ON LLAMA_CUBLAS=1 cmake --build build --config Release -j 10
Which is making it so that llama and kobold both give (gave) something like "GPU detected bt unusable"
Or it might be because I didn't delete the PATH export, even though version sh cuda_12.1.1_530.30.02_linux.run and 12.8 were installed into the same media drive, that shouldn't matter
But for now I've solved it by going from 196GB to 160GB iRAM
so maybe claude really is right?
I dont see why 32GB needs to be reserved for VRAM if there is more than 64GB free though? is it because i calculated from 1024MB instead of 2 bit to get 196GB and it leaked over into the final 64GB RAM card or because calude isnt BSing:
```
Proof chain:
1 VM sees GPU but CUDA hangs vfio-pci binding incomplete
2 Proxmox logs show: vfio-pci 0000:c1:00.0: BAR 1: can't reserve [mem 0x10000000000-0x107ffffffff 64bit pref]
3 BOOTFB occupies: 10000000000-100002fffff (verified in your /proc/iomem)
4 These addresses overlap vfio-pci can't claim them GPU memory unmappable CUDA init hangs
```
Am I the one who is hallucinating?! Am I the AI here?
Anonymous
10/12/2025, 2:15:00 PM
No.106864280
I need gemma-3n rpg/erp fintune. Should I do it my self? with my poorfag gpu?
Anonymous
10/12/2025, 2:16:48 PM
No.106864289
>>106864305
PSA, as many said would eventually happen.
>>106864289
this is very nice too
Anonymous
10/12/2025, 2:22:43 PM
No.106864311
>>106865359
>>106865588
>>106864266
>>106864274
update: nope. loading on 1 GPU works for something like laser_dol_Q6K but LCPP still hangs `watch nvidia-smi` and hogs nvvm as shown in top. taking up a daemon but uncancellable and not increasing in RAM
10240 root 20 0 1014828 107376 56700 R 100.0 0.1 1:48.42 llama-server
i fucking hate this. all i wanted to do was compile llama-server and use GLM4.6 - not break my whole fucking OS and possibly hypervisor too
capcha: YAY AI
Anonymous
10/12/2025, 2:27:05 PM
No.106864337
>>106864344
>>106864368
>>106864305
The west realized that they won't be able to hold China back so they're now trying to kill Deepseek and the others like this.
It's now impossible to publish a model that's >150b fp16 (aka entry-level by today's standards) unless you are a certified 'good boy' who agrees to not get in the way of the western openai tech elite. If you are a threat to them even remotely, you simply will not be allowed to publish your model.
Even worse, even if they let one of those models through it's not impossible to provide usable quants for them to keep the average local user away from these models and herd them towards chatgpt and gemini.
They've done it.
Anonymous
10/12/2025, 2:28:26 PM
No.106864344
>>106864348
>>106864392
>>106864337
What the fuck are you smoking and can I have some?
try LARPing on /pol/ or something
Anonymous
10/12/2025, 2:29:35 PM
No.106864348
>>106864392
>>106864344
And here are the ChatGPT bots trying to play this down despite being apocalyptic for any meaningful open model releases.
Anonymous
10/12/2025, 2:31:50 PM
No.106864361
>>106864367
>>106864305
Not a problem for Bitnet models.
Anonymous
10/12/2025, 2:33:14 PM
No.106864367
Anonymous
10/12/2025, 2:33:26 PM
No.106864368
>>106864373
>>106864337
we'll just get the models from modelscope
Anonymous
10/12/2025, 2:34:49 PM
No.106864373
>>106864368
oi, you got a license to connect to chinese spy servers!?
>>106862537
>No one cares itoddler
The best way to describe her...
All those things in the picture would become actual objective truth instead of disgusting soulless marketing lies, if they were said about her. Fagmmer in shambles. ___-chan finally killed his grift.
Anonymous
10/12/2025, 2:35:57 PM
No.106864381
>>106864374
dude nobody cares about walled garden toys in this space, kys
Anonymous
10/12/2025, 2:36:00 PM
No.106864382
>>106864374
fuck off back to shill phone general already
Anonymous
10/12/2025, 2:36:28 PM
No.106864383
>>106864416
>>106864379
hmm wow is this one of the totally organic thedrummer(tm) copetunes card?
Anonymous
10/12/2025, 2:38:47 PM
No.106864392
>>106864439
>>106864344 (me)
>>106864348
youre a fucking retarded kike nigger. where is the proof of any of this?
Do you even own a GPU?
Anonymous
10/12/2025, 2:38:57 PM
No.106864397
>>106864447
I just tried out glm 4.5 air q8 and it's worse than toss120. What a waste of space. At least you retards are right that 4.6 is quite good.
Anonymous
10/12/2025, 2:39:00 PM
No.106864398
>>106864417
>>106864305
So no more big ggufs on huggingface? Wow, it's worthless now.
Anonymous
10/12/2025, 2:42:20 PM
No.106864416
>>106864505
>>106864383
>Yeah it writes really well and is moving the story forward which I love.
>this is a pretty good model drummer. definitely better on the action part, really feels like it takes the prompt seriously and wants to do it even if it means sacrificing nuance sometimes
>it's better than the gemma 12b and nemo 12b ones I've tried.
>It is excellent! Very creative and drives the plot forward while playing the character authentically.
>Good model! I found it quite intelligent and creative, which is a bit surprising for 22b. The model is a good storyteller, but at the same time tries to make each character “alive” rather than just a simple background. For me, this model is better than the latest Cydonia.
>This model is great fun! This thing is solid, and seriously fun.
>The writing itself look great so far. The character plays looks solid. Only Few swipe needed.
>The model is capable of some remarkably judgemental pushback from characters in the story, without any refusals from the model itself. I love it! Your decision to move to the more censored 24B made me miss out on a lot of your innovations since the origional 22B Cydonia, apparently. Total win, just wish you could replicate that with larger models.
>Only Few swipe needed.
Anonymous
10/12/2025, 2:42:26 PM
No.106864417
>>106864398
You can upload big gguf if you're a good boy and tell them your model is perfectly safe in your begging email.
Anonymous
10/12/2025, 2:43:46 PM
No.106864424
Anonymous
10/12/2025, 2:44:00 PM
No.106864425
>>106864427
That's what you get for not converting your own models.
It's your fault.
Anonymous
10/12/2025, 2:44:35 PM
No.106864427
>>106864425
migu was right all along, only goofs converterchads win
Anonymous
10/12/2025, 2:44:47 PM
No.106864428
>>106864434
>>106864437
Actually this storage situation is a pretty good indicator of bubble burst coming. Or am I wrong?
>>106864305
somewhat nothingburger! just do one repo per quant size, and possible in parts for huge models, that's all it takes
Anonymous
10/12/2025, 2:45:58 PM
No.106864432
>>106864435
>>106864430
You shouldn't have more than 300GB's of (V)RAM anyways.
Anonymous
10/12/2025, 2:46:34 PM
No.106864434
>>106864428
nah, they already tried fucking with storage before this and we didn't burst
>>106864430
cue clem posting "we have le 6 gorrilion repos now:: :rocket:"
Anonymous
10/12/2025, 2:46:36 PM
No.106864435
>>106864432
but I have 4 rtx6000pros
Anonymous
10/12/2025, 2:47:10 PM
No.106864437
>>106864428
More people are taking to AI and the few people that pay for HF are not enough to subsidize the freeloaders.
It means that it's growing.
Anonymous
10/12/2025, 2:47:29 PM
No.106864439
>>106864480
>>106864392
Yes, and enough RAM to be affected by this.
But really, is it that hard to comprehend the issues of being unable to share new remotely SOTA-sized models without begging for special permissions? Not even quants?
I guess you aren't affected if you're a poorfag running models off 'a GPU' and nothing else while lacking the mental capabilities of seeing the consequences of this.
Anonymous
10/12/2025, 2:48:51 PM
No.106864442
>>106864430
So, a simple Kimi K2 Q8 quant now takes four repos to share?
Anonymous
10/12/2025, 2:49:33 PM
No.106864447
>>106864470
>>106864397
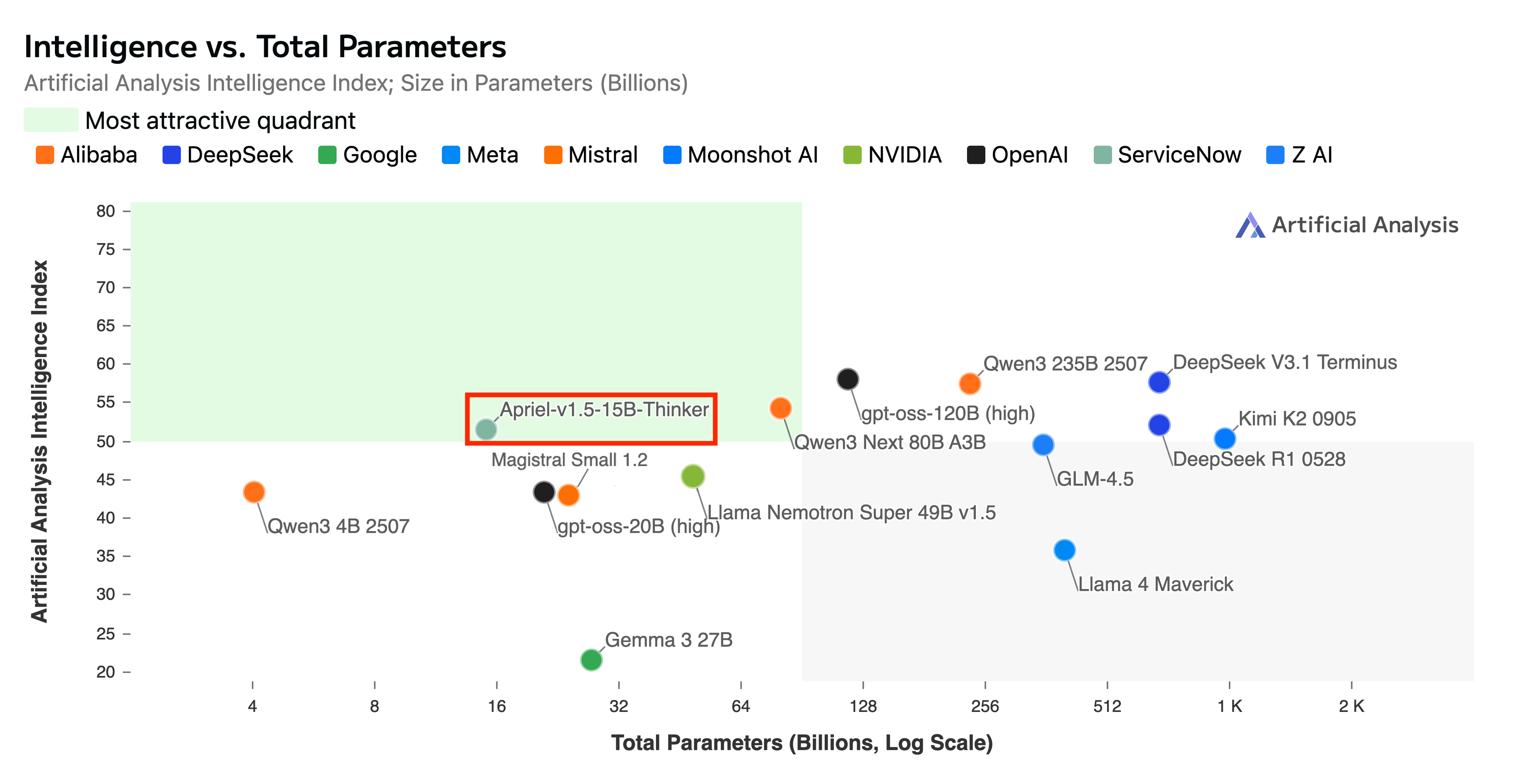
>he doesn't enjoy the "she, she she. she she she she." repetition
nuh uh anon, air is good!
Anonymous
10/12/2025, 2:55:10 PM
No.106864469
>>106864475
>>106864305
anyone ever upload to modelscope?
Anonymous
10/12/2025, 2:55:16 PM
No.106864470
>>106864447
You're absolutely correct! Not this, but that, sent shivers down my spine.
Anonymous
10/12/2025, 2:55:59 PM
No.106864475
>>106864469
needs chinese phone number iirc
Anonymous
10/12/2025, 2:56:21 PM
No.106864480
>>106864498
>>106864439
I understand that its going to kill quant innovation but that doesn't mean I instantly leap into conspiricy rants.
>if you're a poorfag running models off 'a GPU'
literally me trying to stay on topic to figure out which of my 6 (installed) GPUs is causing a memory error instead of worrying about which Jew is responsible for the latest nothing burger while taking a shit
>>106864274
"""
By having an increasing number of diverse and quality contributors, 4chan becomes more unique, interesting, and enjoyable to use.
What is "shitposting"?
Shitposting is "knowingly contributing low quality, off-topic, or ill intentioned posts."
"""
>>106863610
/g/ is full of no-coders who spend hours arguing fiercely about software licenses despite never opening a code editor in their entire lives. IRL, they lack any experience with the licenses they criticize so passionately and biasedly overlook the real challenges and drawbacks of the ones they shill constantly.
Choose whatever license you like, it ultimately doesn't matter much. No license can protect you from Russians, Chinese, North Koreans, etc, stealing your code and not contributing back, or re-licensing your work as proprietary/commercial without giving you a dime. Not at least in countries where American made-up rules hold no power.
Anonymous
10/12/2025, 2:57:46 PM
No.106864490
>>106864494
>>106864497
>>106864481
I write scripts in VBA and matlab. Does that count?
Anonymous
10/12/2025, 2:58:04 PM
No.106864492
>>106864523
>>106864481
it's more important to stop leeches like google. it's fine if commies use the code for the good of the people.
Anonymous
10/12/2025, 2:58:10 PM
No.106864494
>>106864507
Anonymous
10/12/2025, 2:58:31 PM
No.106864497
>>106864507
Anonymous
10/12/2025, 2:58:34 PM
No.106864498
>>106864527
>>106864480
maybe you shouldnt use shitware like proxmox? install esxi bro
Hi all, Drummer here...
10/12/2025, 2:59:29 PM
No.106864505
>>106864519
>>106864379
I'm just as happy about GLM as you are, anon!
Just in case anyone's interested:
>>106864379
https://huggingface.co/TheDrummer/Cydonia-R1-24B-v4 (there's also a v4.1 which some are happier with)
>>106864416
First 4 quotes:
https://huggingface.co/TheDrummer/Snowpiercer-15B-v3
Last 4 quotes:
https://huggingface.co/TheDrummer/Cydonia-ReduX-22B-v1 (now outdated, v1.1 is coming out!)
Regarding the "only a few swipes needed", the feedback is referring to the old 22B with updated tuning.
Regarding sources, I gather feedback from testers.
Thanks anons for discussing Drummer(tm) models! Your engagement is valuable.
Anonymous
10/12/2025, 3:00:00 PM
No.106864507
Anonymous
10/12/2025, 3:00:39 PM
No.106864514
Using thedrummer(tm)'s copetune?
miss me with that shit, I exclusively use davidau's schizo tunes
Anonymous
10/12/2025, 3:00:54 PM
No.106864516
>>106864555
>>106864305
It's always been like that, they don't enforce it.
https://web.archive.org/web/20241217185816/https://huggingface.co/docs/hub/en/storage-limits
Are there any other reports of Huggingface even enforcing the 10TB limit? Or just that guy with his:
https://huggingface.co/Thireus/collections ?
Anonymous
10/12/2025, 3:01:10 PM
No.106864519
>>106864505
You are a joke and a faggot. Become the safety engineer already. Is is your destiny and a perfect punchline.
Anonymous
10/12/2025, 3:01:33 PM
No.106864523
>>106864492
>for the good of the people.
Anonymous
10/12/2025, 3:01:59 PM
No.106864527
>>106864538
>>106864498
>I feel inadequate because you posted about software I don't personally use
It's propitiatory and I didn't want to check if it needs a license when getting help.
Besides, my NAS is in proxmox and I don't want to spend a year learning new software just for it to break in new ways
Anonymous
10/12/2025, 3:02:29 PM
No.106864529
>>106864547
>>106864481
>No license can protect you from Russians, Chinese, North Koreans, etc
Good. FLOSS doesn't exist to reinforce ZOG global hegemony.
Anonymous
10/12/2025, 3:02:36 PM
No.106864530
>>106864563
base > instruct > finetune > merges
Anonymous
10/12/2025, 3:03:48 PM
No.106864538
>>106864554
>>106864753
>>106864527
im kidding, I'm using esxi shitware and I want out. vmware guests are supported like shit in linux guests. even broadcom wants out.
SAVE ME
Anonymous
10/12/2025, 3:04:59 PM
No.106864547
>>106864529
Licenses are spooks, just as ZOG and anything /pol/ believes.
Anonymous
10/12/2025, 3:05:30 PM
No.106864554
>>106864538
Proxmox isn't better. There is no escape.
Anonymous
10/12/2025, 3:05:53 PM
No.106864555
>>106864516
You're absolutely right! This is perfectly fine and nothing is happening at all!
Anonymous
10/12/2025, 3:07:02 PM
No.106864563
>>106864530
this kills the finetrooner
Anonymous
10/12/2025, 3:12:38 PM
No.106864595
>>106864603
>>106864622
Everything is fine, stop falling for FUD.
Anonymous
10/12/2025, 3:13:59 PM
No.106864603
>>106864595
isnt thierus a goofer for the ikllama fork? SAD
Anonymous
10/12/2025, 3:15:57 PM
No.106864622
>>106864652
Anonymous
10/12/2025, 3:16:49 PM
No.106864626
>>106864632
>>106864647
I am gonna say it. If they really need to cut down on storage delete all but 1 quants of ancient models before 2025. And maybe make an exception for models that are still being downloaded recently for some reason. Archive is still there for everything and realistically nobody is downloading those now.
Anonymous
10/12/2025, 3:18:12 PM
No.106864632
>>106864626
I downloaded ure mom
Anonymous
10/12/2025, 3:19:17 PM
No.106864642
>>106864659
Anonymous
10/12/2025, 3:19:40 PM
No.106864647
>>106864669
>>106864626
Our lord and savior pew (creator of some of the best samplers ever! and some other very important tools) agrees, anyways we should all just use ollama and only the sizes they offer, anything else should be banned.
Anonymous
10/12/2025, 3:19:58 PM
No.106864649
Oh and while they are at cutting down storage they should ban Drummer. But leave davidau. He is a gem.
Anonymous
10/12/2025, 3:20:09 PM
No.106864652
>>106864668
>>106864714
>>106864622
It's very difficult as a company to start doing "fuck you in particular" account deletions without hysterical reddit and social media posts like what happened today.
Anonymous
10/12/2025, 3:21:10 PM
No.106864659
>>106864673
>>106864678
>>106864642
suck my cock Ani. actually don't. you suck at sucking cock and I don't want that faggot elon watching through a camera. I have __-chan.
Anonymous
10/12/2025, 3:22:10 PM
No.106864668
>>106864652
I will write 10 reddit OP's about how banning drummer made everyone happy and world is now better.
Anonymous
10/12/2025, 3:22:13 PM
No.106864669
>>106864647
Can't the llama.cpp server by now directly download and run models off of HuggingFace?
WTF is this guy going on about?
Anonymous
10/12/2025, 3:22:39 PM
No.106864673
>>106864659
oh my, my favorite anon coming in hot with the requests!
Anonymous
10/12/2025, 3:23:38 PM
No.106864677
>>106864685
Gork 3 status?
Anonymous
10/12/2025, 3:23:43 PM
No.106864678
>>106864689
>>106864695
>>106864659
>he thinks about other men watching him fap unprompted
This is your mind on /g/ memes and privacy schizophrenia.
Anonymous
10/12/2025, 3:24:21 PM
No.106864685
>>106864677
what about it?
Anonymous
10/12/2025, 3:25:12 PM
No.106864689
>>106864696
>>106864782
>>106864678
Projection is real. Basically anon is probably a closet faggot with a voyeurism fetish.
Anonymous
10/12/2025, 3:25:59 PM
No.106864695
>>106864678
It all goes to the future training data. And my fetish is reciting all my personal details while getting head, so she can then blackmail me by telling me she can now take a loan in my name.
Anonymous
10/12/2025, 3:26:23 PM
No.106864696
>>106864689
>Projection is real
yes, cinema exist what is point of this sir?
Anonymous
10/12/2025, 3:28:39 PM
No.106864714
>>106864878
>>106864652
>you are not allowed to have 10x more repos than our current goodest boy bartowski
there, simple 'nough
Anonymous
10/12/2025, 3:29:42 PM
No.106864721
>>106863116
>for the lulz of course
Anonymous
10/12/2025, 3:30:29 PM
No.106864725
>>106864726
>>106864738
The reason hugging face is doing this is troons isn't it?
Anonymous
10/12/2025, 3:30:57 PM
No.106864726
>>106864737
Anonymous
10/12/2025, 3:32:22 PM
No.106864737
>>106864726
Recoils when called out!
Anonymous
10/12/2025, 3:32:31 PM
No.106864738
Anonymous
10/12/2025, 3:35:44 PM
No.106864753
>>106864762
>>106864538
>>106864274
I figured it out. Claude was right.
I mustve changed initcall_blacklist=sysfb_init to off last time I restarted months ago because I thought I didn't need it, then last week I mustve cooked the CPU when letting GLM run for 12 hours straight while at work and the reset applied the setting without it
Did any of you guess that was the issue? Also can I get a job now? JNCIA was easy
Anonymous
10/12/2025, 3:36:11 PM
No.106864757
>>106864781
>>106864784
Well that garbage was easy to break
(Microsoft UserLM 8B, a model designed to simulate user input to be used in multi-turn research scenarios)
How many millions of indian rupees did they spend on that?
Anonymous
10/12/2025, 3:36:59 PM
No.106864762
Anonymous
10/12/2025, 3:39:44 PM
No.106864781
>>106864757
>Well that garbage was easy to break
All I see is a perfect model that is almost 100% accurate.
Anonymous
10/12/2025, 3:39:49 PM
No.106864782
>>106864689
>anime and pedophilia out of nowhere
lmao?
Anonymous
10/12/2025, 3:39:55 PM
No.106864784
>>106864757
At least ◯◯ lakh
Anonymous
10/12/2025, 3:50:06 PM
No.106864860
Anonymous
10/12/2025, 3:52:18 PM
No.106864878
>>106864918
>>106864714
Why not screenshot this bit?
Anonymous
10/12/2025, 3:58:35 PM
No.106864912
>>106864936
>>106861725
where do high iq coom wizards fit in there?
Anonymous
10/12/2025, 3:59:29 PM
No.106864918
>>106864955
>>106864968
>>106864878
cause the amount that costs is nothing compared to the storage space?
Anonymous
10/12/2025, 4:01:52 PM
No.106864934
>>106862060
>artificial analysis
Anonymous
10/12/2025, 4:02:31 PM
No.106864936
>>106864912
The original post is a play on the known meme of 90% of people watch porn and other 10% are lying.
Anonymous
10/12/2025, 4:02:47 PM
No.106864940
>>106862518
MIT is based
>>106862551
AGPL is for AGP commies
Anonymous
10/12/2025, 4:04:51 PM
No.106864955
>>106864968
>>106864918
And only much from the paying users managed to subsidize the rest for years.
Anonymous
10/12/2025, 4:06:42 PM
No.106864968
>>106864977
>>106864978
>>106864918
>>106864955 (cont)
Though I still think everyone should make their own quants. Fuck quanters. But at least that one pays, as little as he does.
Anonymous
10/12/2025, 4:08:05 PM
No.106864977
>>106865010
>>106864968
Following a handful of simple command line instructions is hard doe fr fr
Anonymous
10/12/2025, 4:08:26 PM
No.106864978
>>106865010
>>106864968
And once again I will reiterate, absolutely fuck downloading the full dozens of niggabytes when I just want the one specific size that fits in my shit rig.
Anonymous
10/12/2025, 4:13:01 PM
No.106865008
>>106865032
>>106865108
>>106864374
Why do people buy phones you can't even jailbreak? Make it make sense!
Anonymous
10/12/2025, 4:13:19 PM
No.106865010
>>106864977
ikr? fr. No cap and such.
>>106864978
I hope HF really enforces storage limit, just to fuck specifically with you.
But nothing terrible will happen. It's fine. It's like all the other 3 or 4 times it happened. Feels like a repeat episode.
Anonymous
10/12/2025, 4:16:25 PM
No.106865032
>>106865090
>>106865008
Like Androids you can't sideload on? You do know that's coming, right? Or all those with completely locked bootloaders?
Anonymous
10/12/2025, 4:19:58 PM
No.106865062
>>106865156
>looking at PC components for shits and giggles.
>AI marketing buzzwords all over everything
>AI cooling
If you need artificial intelligence to tell you how to set a proper fan curve you're probably in the wrong hobby.
Anonymous
10/12/2025, 4:22:31 PM
No.106865090
>>106865110
>>106865032
>Or all those with completely locked bootloaders?
Nobody buys those.
>Like Androids you can't sideload on? You do know that's coming, right?
Surely nothing will happen.
I've taken a two-month break. Has anything developed? Is there now an ultimate model for local use?
Anonymous
10/12/2025, 4:23:19 PM
No.106865097
>>106865091
>Is there now an ultimate model for local use?
nope. Still Nemo.
Anonymous
10/12/2025, 4:23:54 PM
No.106865102
>>106865166
>>106865091
Buy GLM4.6 subscription right now sir.
Anonymous
10/12/2025, 4:24:49 PM
No.106865108
>>106865166
>>106865008
>jailbreaking phone
Use case?
Why break something that works perfectly?
Anonymous
10/12/2025, 4:25:01 PM
No.106865110
>>106865173
>>106865090
Samsung sadly does get a lot of sale, and many Chinese phone makers now lock bootloaders completely as well.
Anonymous
10/12/2025, 4:26:45 PM
No.106865124
>>106865166
>>106865363
>>106865091
If you have enough RAM + VRAM, GLM 4.5 Air is just a straight up upgrade.
Anonymous
10/12/2025, 4:30:34 PM
No.106865156
>>106865062
>fiddling with fan curve
I just 100% that bitch the second the system is not idle
Anonymous
10/12/2025, 4:31:42 PM
No.106865166
>>106865186
>>106865124
>>106865108
>>106865102
>>106865091
ITT: VRAMlets who dont know 512GB iRAM is now under a months wages for a first worlder
Anonymous
10/12/2025, 4:32:40 PM
No.106865173
>>106865195
Anonymous
10/12/2025, 4:34:25 PM
No.106865186
ITT: Faggot -
>>106865166
Anonymous
10/12/2025, 4:35:28 PM
No.106865195
>>106865296
Anonymous
10/12/2025, 4:48:00 PM
No.106865296
>>106865365
>>106865195
bwahahaha thanks eu again
Anonymous
10/12/2025, 4:53:42 PM
No.106865328
>>106865342
>>106865363
Anything new for 16gb vramlets? I think my current model is almost a year old at this point.
Can anyone link a written article with a concise and clear explanation of what MCP is, does, and where and how I would use it? From what I've seen so far, it's mostly jeets on X and Youtube who are enthusiastic about it, and on vibe alone that makes me very skeptical.
Anonymous
10/12/2025, 4:55:13 PM
No.106865342
>>106865399
>>106865328
just give up and use glm api, it's over
Anonymous
10/12/2025, 4:57:07 PM
No.106865359
>>106865588
>>106864311
Why are you trying to do this with a hypervisor in the way
Anonymous
10/12/2025, 4:57:35 PM
No.106865363
>>106865375
>>106865399
>>106865340
As far as I can tell, it's just a REST (or Graph) API.
>>106865328
See
>>106865124
Anonymous
10/12/2025, 4:57:39 PM
No.106865364
>>106865340
youre a retarded gorillaa nigre. ask chatgpt why mcp is useful you fucking retard
Anonymous
10/12/2025, 4:57:48 PM
No.106865365
>>106865296
Nothing makes me feel more safe and secure like not being allowed to install software on my own hardware.
Anonymous
10/12/2025, 4:58:24 PM
No.106865370
>>106865340
MCP is dumb, tool calling is not though. Agent Communication Protocol is the future.
Anonymous
10/12/2025, 4:58:36 PM
No.106865375
>>106865363
>it's just a REST (or Graph) API.
it's just a REST (or Graph) API *standard*.
Anonymous
10/12/2025, 5:00:35 PM
No.106865391
>>106865342
>use glm api
What is that? Another proxy?
>>106865363
>GLM 4.5 Air
Not my weight class. I can't split load at all, old cpu and ddr3 ram.
Anonymous
10/12/2025, 5:03:07 PM
No.106865417
>>106865399
not proxy no no no! you pay for the legals!
Anonymous
10/12/2025, 5:04:39 PM
No.106865435
>>106865458
>>106865520
>>106865399
>What is that? Another proxy?
He's telling you to pay to access their API. At that point, just pay for deepseek's.
>>106865399
>Not my weight class. I can't split load at all, old cpu and ddr3 ram.
Shame. It is pretty good for what it is.
For things other than jacking off, the qwen 3 models can be pretty good.
Qwen 3 30B coder and thinking are the standouts given their size and number of activated params.
Anonymous
10/12/2025, 5:07:15 PM
No.106865453
>>106865471
>>106865482
Is there any noticeable difference between unsloth and bartowski's glm 4.6 quants?
Anonymous
10/12/2025, 5:07:38 PM
No.106865458
>>106865435
>For things other than jacking off
there is no such things, just like there is no such things as better than the glm
Anonymous
10/12/2025, 5:10:28 PM
No.106865482
>>106865494
>>106865453
Yes.
I can load a lot slightly more of the same quant for a given model for unsloth quants, which means that they are probably "over quanting" some part of the model that they shouldn't be.
>>106865482
>a lot slightly more of the same
thank you sir
Anonymous
10/12/2025, 5:12:54 PM
No.106865506
>>106865494
That's what I get for rewriting without rereading the post.
Anonymous
10/12/2025, 5:13:09 PM
No.106865511
>>106865494
thank you kind sir
Anonymous
10/12/2025, 5:13:59 PM
No.106865520
>>106865535
>>106865555
>>106865435
>Qwen 3 30B
Is it worth getting at Q2? I feel like that would strip way too much.
Anonymous
10/12/2025, 5:15:36 PM
No.106865535
>>106865575
>>106865520
No, but you don't need to. Even with ddr3, you can safely split the model between RAM and VRAM. With 16GB of VRAM, you'll still have most of the model in the GPU and it'll be fast as fuck.
Feel free to run the largest quant you can fit.
Anonymous
10/12/2025, 5:16:07 PM
No.106865542
>>106865555
>>106865471
holy fucking cringe
Anonymous
10/12/2025, 5:16:12 PM
No.106865543
>>106865621
>>106865494
What would a sirless internet look like?
Anonymous
10/12/2025, 5:17:13 PM
No.106865549
>>106865471
Oh my fucking god those faggots look like this? No wonder they are fucking incompetent.
Anonymous
10/12/2025, 5:17:39 PM
No.106865555
>>106865626
>>106865542
>>106865520
I forgot to mention, it's a MoE with just 3B activated params, hence why you can run the largest quant you can fit on RAM + VRAM and it'll still be fast as hell.
Anonymous
10/12/2025, 5:18:43 PM
No.106865563
>>106865583
>>106865471
>@jumanjimusic4094: These guys have done so much for the OSS community, with every new model release moments later Unsloth has released a bug fix that the creators missed. Unbelievable that this is only a 2 man team and they still give us so much value.
AAAAAAAAAAAAAAAAAAAAAAAAAA!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!
Anonymous
10/12/2025, 5:19:33 PM
No.106865575
>>106865535
now say exactly what specific t/s you consider to be "fast as fuck"
Anonymous
10/12/2025, 5:20:35 PM
No.106865583
>>106865887
>>106865563
face the wall
Anonymous
10/12/2025, 5:20:48 PM
No.106865588
>>106864311
The Basilisk is testing you anon
Have you badmouthed AI systems in public or ever thought "all robots and computers must shut the hell up"? You'd never speak ill of queen and saviour Miss Hatsune Miku right? I trust you haven't uttered the ultimate blasphemy - the C-word.
also this
>>106865359
Anonymous
10/12/2025, 5:21:45 PM
No.106865600
Anonymous
10/12/2025, 5:24:07 PM
No.106865621
Anonymous
10/12/2025, 5:25:02 PM
No.106865626
>>106865639
>>106865555
I should have enough ram to run a full model just on that… I'll trust your judgement, anon, hopefully my pc will not explode too fast. Thanks for advice.
Anonymous
10/12/2025, 5:26:21 PM
No.106865639
>>106865626
Don't quant the cache, use -ngl 99 --n-cpu-moe as small as you can, and have fun.
Anonymous
10/12/2025, 6:10:05 PM
No.106865887
>>106865583
follow your leader