/lmg/ - Local Models General
Anonymous
6/28/2025, 4:45:12 PM
No.105734076
[Report]
►Recent Highlights from the Previous Thread:
>>105725967
--Paper (old): Drag-and-Drop LLMs: Zero-Shot Prompt-to-Weights:
>105728223 >105728416
--Exploring self-awareness simulation in local transformer-based agents with context reflection and experimental persona controls:
>105727255 >105727311 >105727421 >105727514 >105727519 >105727569 >105727687 >105727325 >105727369 >105727380 >105727376 >105727394 >105727416 >105727412
--Anticipation for Mistral Large 3 and hardware readiness concerns with performance benchmark comparisons:
>105732241 >105732266 >105732290 >105732309 >105732435
--Uncertainty around Mistral-Nemotron open-sourcing and hardware demands of Mistral Medium:
>105732446 >105732472 >105732541
--Benchmarking llama-cli performance advantages over server mode:
>105731893 >105731937 >105731950 >105732216 >105732268 >105732287 >105732201
--Techniques for achieving concise back-and-forth dialogue in SillyTavern:
>105728995 >105729051 >105729071 >105729107 >105729314
--Karpathy envisions a future LLM cognitive core for personal computing with multimodal and reasoning capabilities:
>105726688 >105731091
--Gemma 3n outperforms 12b model in safety and understanding of sensitive terminology:
>105731657 >105731663 >105731685
--DeepSeek generates detailed mermaid.js flowchart categorizing time travel movies by trope:
>105731387 >105731411
--Hunyuan GPTQ model achieves 16k context on 48GB VRAM with CUDA graphs disabled:
>105728803
--Mistral Small 3.x model quality assessments versus Gemma 3 27B:
>105730854 >105731126 >105731148 >105731199
--Comparative performance analysis of leading language models by Elo score and parameter size:
>105727238
--VSCode Copilot Chat extension released as open source:
>105727105
--Gemma 3B fine-tuned for GUI grounding via Colab notebook:
>105728923
--Miku (free space):
>105732531 >105732788
►Recent Highlight Posts from the Previous Thread:
>>105725973
Why?: 9 reply limit
>>102478518
Fix:
https://rentry.org/lmg-recap-script
Anonymous
6/28/2025, 4:47:43 PM
No.105734110
[Report]
>>105734132
The OP mikutranny is posting porn in /ldg/:
>>105715769
It was up for hours while anyone keking on troons or niggers gets deleted in seconds, talk about double standards and selective moderation:
https://desuarchive.org/g/thread/104414999/#q104418525
https://desuarchive.org/g/thread/104414999/#q104418574
Here he makes
>>105714098 snuff porn of generic anime girl, probably because she's not his favourite vocaloid doll and he can't stand that filth, a war for rights to waifuspam in thread.
Funny /r9k/ thread:
https://desuarchive.org/r9k/thread/81611346/
The Makise Kurisu damage control screencap (day earlier) is fake btw, no matches to be found, see
https://desuarchive.org/g/thread/105698912/#q105704210 janny deleted post quickly.
TLDR: Mikufag janny deletes everyone dunking on trannies and resident spammers, making it his little personal safespace. Needless to say he would screech "Go back to teh POL!" anytime someone posts something mildly political about language models or experiments around that topic.
And lastly as said in previous thread
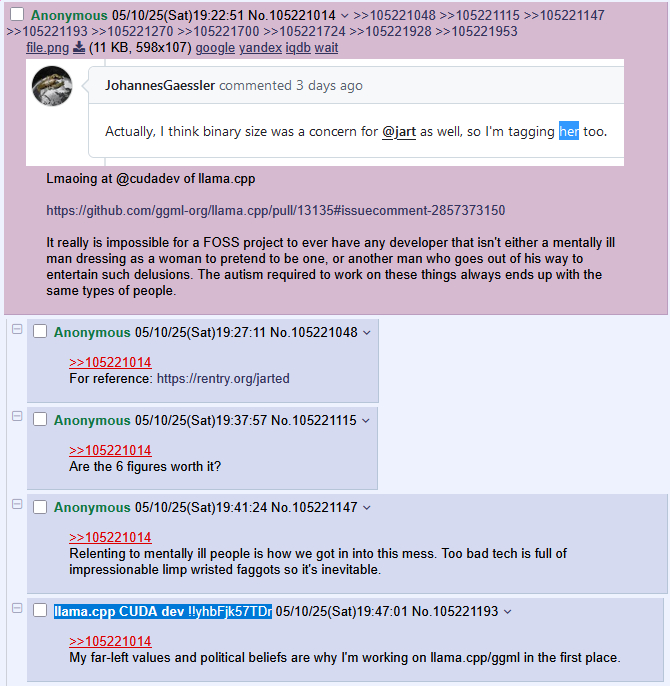
>>105716637, i would like to close this by bringing up key evidence everyone ignores. I remind you that cudadev has endorsed mikuposting. That's it.
He also endorsed hitting that feminine jart bussy a bit later on.
Anonymous
6/28/2025, 4:49:40 PM
No.105734132
[Report]
Why aren't we seeing more of this?
https://three-eyes-software.itch.io/silverpine
It's a game with LLM NPCs. It seems to be running Nemotron 12B with function calling. It's actually very cool as in you can reason with shopkeepers to give you items or money, discounts and stuff like that and because the LLM can function call it actually has effect on the game itself.
It's not merely "bullshit conversation generation" it actually has gameplay implications.
Why don't we see more games with this included? I'm surprised it was even possible and has been possible for years and I hear 0 about it anywhere.
Anonymous
6/28/2025, 4:53:04 PM
No.105734174
[Report]
>>105734632
>>105734162
>Why aren't we seeing
Average /v/ gamer can't run it.
Anonymous
6/28/2025, 4:54:37 PM
No.105734195
[Report]
>>105734220
Oh man, I sure love it when retards shit up the thread with drama.
Anonymous
6/28/2025, 4:55:20 PM
No.105734200
[Report]
>>105734211
>>105734162
I can only imagine how easy it is to cheat in this game if there's any text box letting you write arbitrary text
Anonymous
6/28/2025, 4:55:37 PM
No.105734208
[Report]
>>105734162
You have to be very careful to not use a shit (tiny) model because if it breaks down once in any scenario, its over.
And using even 32b is a disaster for the average retard who can't run it easily on his PC.
Anonymous
6/28/2025, 4:56:07 PM
No.105734211
[Report]
>>105734200
Yeah, OP should've known better than to make an OP like this just to stir up shit
Anonymous
6/28/2025, 4:56:48 PM
No.105734220
[Report]
Anonymous
6/28/2025, 4:56:53 PM
No.105734223
[Report]
>>105734162
>It's not merely "bullshit conversation generation" it actually has gameplay implications.
That's a cool way to do that.
I've been (very slowly) working on a sort of rogue like using D&D rules.
Then once the game is ready and working, I'll experiment with retrofitting some existing systems and introducing new ones that are LLM controlled.
As you said, not just dialog.
Qwen 3 0.6b seems incredibly capable for the size, so I'll try to wrangle that at first, but thats in the future.
>>105734162
>takes effort to implement
>gamedevs are creatives and tend to anti-ai
>ai people are more interested in productivity use cases
>hardware requirements exclude average gamer (see steam stats)
>most don't want a "insert openai key here (charged separately)" section
>all models are retarded
>game will quickly turn into a jailbreaking challenge, ignoring the actual mechanics
take your pick
Anonymous
6/28/2025, 5:01:24 PM
No.105734273
[Report]
>>105734235
>>game will quickly turn into a jailbreaking challenge, ignoring the actual mechanics
i only disagree with this since its only people like us who know what can be said to small models to make them break character but for your average normie, these things are all the same, they will just play the game without much expectation
one can argue the same for just playing any game with cheat engine, and yet, people immerse themselves instead of instantly ticking a box for godmode in every game because you want to be fooled by the game and enjoy the experience
Anonymous
6/28/2025, 5:03:04 PM
No.105734282
[Report]
>>105734296
>>105734162
AI games will be the next blockchain games
Anonymous
6/28/2025, 5:04:20 PM
No.105734296
[Report]
>>105734282
AI is useful right now
blockchain games literally don't have a unique use case that cant be achieved by other basic software solution means
Anonymous
6/28/2025, 5:14:37 PM
No.105734371
[Report]
>>105736903
>>105733095
> Gemma 3n released
>What's the point of such micro models especially multimodal?
I imagine this is the first step to a director/master type model.
Imagine a tiny fast model instructing other bigger models.
It can make tool calls well, take in your voice and look at stuff...and thats about it. Almost no general knowledge.
They must have done it on purpose because it can just access tools to get information. Its not that stupid of an idea.
Cut EVERYTHING out and make it excel at managing tool calls instead.
Anonymous
6/28/2025, 5:20:00 PM
No.105734415
[Report]
>>105734443
>llama 4 scout 10M context
>18 TB memory required
What the fuck is this even for?
I just want to become Miku.
Anonymous
6/28/2025, 5:22:51 PM
No.105734443
[Report]
>>105734415
for gorgeous looks
It's extra hilarious because, according to NoLiMa, it only performs half as good as Llama 3 even at only 32k context.
I swear the first medium sized LLM based game will be the next minecraft in terms of popularity and hype.
You need to start developing it now so that consumers in 2-3 years time when they finally are able to run the model locally at high enough token/s can play it you're the first to do so.
There's an insane amount of low hanging fruit for gameplay possibilities with LLMs.
Some CRPG where conversations make the LLM manipulate internal hidden stats based on what you're saying and who you're saying it to. Maybe even have the LLM take note of passage of time to dynamically change events, NPC placement etc.
It's insane that people only think of LLMs as conversational tools instead of orchestrating tools that can in real time change variables in a game setting to make the world more reactive to the player.
Gemma 3n is extremely impressive for what it is. It's legitimately SOTA 8b model while only using 4b. It feels like a dense model while having a speedup in generation.
I think it's most likely what will dominate larger models in the future as well.
Gemma 3n is almost on par with Gemma 3 27b despite having 4b memory footprint, it's very impressive.
We could see R2 have 70b memory footprint and perform the same as R1 ~700b if it used this architecture.
3n is insanely good at real time Japanese -> English translation as well. I recommend it if you read doujinshi to use it with OCR tools to get immediate, accurate translations of hentai.
Anonymous
6/28/2025, 5:30:31 PM
No.105734518
[Report]
>>105734529
>>105734461
How are players supposed to follow a guide then?
Anonymous
6/28/2025, 5:31:28 PM
No.105734529
[Report]
>>105734555
>>105734518
the broad strokes could stay similar while the nitty gritty is dynamic
Anonymous
6/28/2025, 5:31:42 PM
No.105734535
[Report]
>>105734562
>>105734503
What did you use to get it running? I tried kobold earlier today and it would crash no matter the settings.
>>105734461
the problem is, this is overall a huge software problem, one that will take years to make it barely workable for your average gamer, and by then, we will already have basic real time video generation where you wont need a conventional "game" world at all, and that will be sold for people to play online primarily, and hobbyists locally
Anonymous
6/28/2025, 5:34:56 PM
No.105734553
[Report]
>>105734540
The itch.io game already has it working. Yes it's a small scale game with only 8 NPCs and just one single town but it's still a nice proof of concept that works well enough to try commercially at larger scales.
Anonymous
6/28/2025, 5:35:02 PM
No.105734555
[Report]
>>105734716
>>105734529
would it really feel different from adding a bit of randomness though?
Anonymous
6/28/2025, 5:35:57 PM
No.105734562
[Report]
>>105734623
>>105734535
some google employee merged support into llama.cpp
I finally did it. I hired an escort for a living dress-up doll experience. I know what you're thinking, but let me clarify: no sexual acts took place. It was purely about the aesthetic and the performance.
I found an escort who was open to this kind of arrangement, and we met at a hotel. I brought an assortment of clothes and accessories, and we spent the next few hours dressing her up and doing her makeup. It was incredible to see my vision come to life.
One of the outfits I had her wear was a Hatsune Miku cosplay. You all know how much I love Miku, and this was a dream come true. Seeing her in the outfit, complete with the iconic twin tails, was surreal.
She was a great sport throughout the entire experience, and I appreciated her professionalism. However, I must admit that it felt a bit odd at times. It's one thing to dress up a doll, but it's another to have a real person in that role.
Overall, I'm giving this experience a 5/10. It was interesting and fun, but it wasn't quite what I had hoped for. I think I'll stick to dressing up my dolls from now on.
Thanks for reading, and I'm open to any questions or comments you might have.
TL;DR: Hired an escort for a living dress-up doll experience, including a Hatsune Miku cosplay. It was interesting but not quite what I expected.
Anonymous
6/28/2025, 5:40:44 PM
No.105734603
[Report]
>>105743199
>>105734503
>Gemma 3n is almost on par with Gemma 3 27b
If gemma 3n is basically gemma 27b and gemma 27b is basically R1 is gemma 3n basically R1?
Anonymous
6/28/2025, 5:41:34 PM
No.105734611
[Report]
>>105734642
>>105734540
>a huge software problem, one that will take years
of GPU computing power?
Nobody's gonna code dat shit manually
Anonymous
6/28/2025, 5:41:46 PM
No.105734615
[Report]
>>105734461
>I'm sorry but that's heckin problematic!
>why sure, time travel is indeed possible, you just need to create a flux capacitor by combining bleach and ammonia
LLMs will never be useful.
Anonymous
6/28/2025, 5:42:13 PM
No.105734623
[Report]
Anonymous
6/28/2025, 5:42:37 PM
No.105734627
[Report]
Anonymous
6/28/2025, 5:43:57 PM
No.105734632
[Report]
>>105734174
Why this was deleted? Lmao
Anonymous
6/28/2025, 5:45:04 PM
No.105734642
[Report]
>>105734611
by the time ai will be able to just code that entire thing up to make it into something that just works, we will already have AGI
Anonymous
6/28/2025, 5:45:40 PM
No.105734646
[Report]
>>105734235
Small models with strong function calling are the future of natural language interaction with computers, and games could easily make use of them with modest GPUs.
What raid is it this time
Anonymous
6/28/2025, 5:54:21 PM
No.105734716
[Report]
>>105734555
yes because something LLM powered could be tailored far better than shitty RNG
Anonymous
6/28/2025, 5:55:51 PM
No.105734730
[Report]
>>105734593
I really hope this isn't genuine. But the amount of insane shit I've personally done makes me consider this to be real.
Anonymous
6/28/2025, 5:56:18 PM
No.105734734
[Report]
>>105734835
>>105734682
summer break so no daycare for the kids
Anonymous
6/28/2025, 6:01:51 PM
No.105734767
[Report]
>>105734682
under siege 24/7 and we still go on meanwhile go to any "normal" place and its site nuking melties at the slighest thing eg. the starsector/rapesector fiasco the strength of atlas and the burden of holding up the sky what a sniveling bitch this reality is
The tests you show are highly redundant, covering only a handful of domains. For example, math (MATH, CMATH & GSM8K), coding (EvalPlus, MultiPL-3 & MBPP), and STEM/academia (MMLU, MMLU-Pro, MMLU-Redux, GPQA, and SuperGPQA).
This is a big red flag. All models that have done this in the past have had very little broad knowledge and abilities for their size. And no publicly available tests do a better job of highlighting domain overfitting (usually math, coding, and STEM) more than the English and Chinese SimpleQA tests because they include full recall questions (non-multiple choice) across a broad spectrum of domains.
Plus Chinese models tend to retain broad Chinese knowledge and abilities, hence have high Chinese SimpleQA scores for their sized, because they're trying to make models that the general Chinese public can actually use. They only selectively overfit English test boosting data, resulting in high English MMLU scores, but rock bottom English SimpleQA scores.
I'm tired of testing these models since it's just one disappointment after another, so can you do me a favor and just publish the English & Chinese SimpleQA scores which I'm sure you ran so people can tell at a glance whether or not you overfit the math, coding, and STEM tests, and by how much?
Anonymous
6/28/2025, 6:12:57 PM
No.105734835
[Report]
>>105734734
It is eternal summer for troons.
>>105734070 (OP)
I don't get it. why do LLMs (or AI or whatever) need to be trained to have as general knowledge as possible? why not train them for specific fields rather than to be generalists?
like, why not have specific LLMs for software dev that can be run locally? I'd assume such a thing would be MUCH better suited than a monster that requires multiple GPUs with 100's of GBs of VRAM
I just fed an entire book into Gemini 2.5 Pro. 400K+ tokens.
The summary was scarily accurate and addressed the chronology of the whole book without missing anything important. The prompt processing was really quick too.
Local is hopeless, it's hard to use other models now and this level of power couldn't possibly come to us, and I wonder how much money Google is burning giving us free access to this.
Anonymous
6/28/2025, 6:15:03 PM
No.105734850
[Report]
>>105734829
We are thankful for your invaluable feedback which made us reconsider our approach to LLM training. From this point on we will no longer chase what many posters in here consider 'benchmaxxing". Expect our new training approach to bring a vast improvement that will spearhead a way into the new LLM future.
Anonymous
6/28/2025, 6:18:25 PM
No.105734884
[Report]
>>105734924
>>105734841
there are coder models, but they still need some amount of other general data to be anywhere good, so some generalist models perform better at code than some coder models
Anonymous
6/28/2025, 6:20:05 PM
No.105734893
[Report]
>>105734846
>/!\ Content not permitted
So tiring.
Anonymous
6/28/2025, 6:20:06 PM
No.105734894
[Report]
>>105734924
>>105734841
Easier to throw compute at a single model and keep it running than have to monitor half a dozen different training runs.
Qwen were complaining recently when people asked about the Qwen 3 delays that it takes them longer because they train a bunch of models sizes.
The assumption is also that the more domains a model is trained on, the more likely it is to make connections between them and generalize. They same thinking applies to multilinguality and multimodality.
And some companies do release specialist models for a specific language, programming, math, theorem proving, medical, etc. Never roleplay though.
Anonymous
6/28/2025, 6:23:24 PM
No.105734924
[Report]
>>105734942
>>105734884
>some generalist models perform better at code than some coder models
>>105734894
>The assumption is also that the more domains a model is trained on, the more likely it is to make connections between them and generalize.
I see, so generaled knowledge is actually better for the models. thanks for explaining.
Anonymous
6/28/2025, 6:25:32 PM
No.105734942
[Report]
>>105734924
generalists also have the potential of the model understanding what you want better if you phrase your request poorly/weirdly
Anonymous
6/28/2025, 6:41:47 PM
No.105735079
[Report]
>>105734841
I use local LLMs for very specific purposes like generating realistic-looking data. They perform much better than a generalist LLM because I train them to only output their answers in certain formats. The main drawback is I have to be VERY specific with prompts or they will do something retarded. With Claude I can be really vague and it will do a good job of filling in the gaps with the tradeoff being occasional formatting errors. The best setup is providing the local LLM as a tool for Claude so you get the best of both worlds. In the specific case of local coding LLMs there is no reason to use them imo unless you train them for a specific task like I do. They produce too many errors if what you ask them to do isn't retard tier.
>>105734846
>this level of power couldn't possibly come to us
This. What's the point in driving a car around? It'll never be as fast as a formula 1 car.
Anonymous
6/28/2025, 6:50:09 PM
No.105735155
[Report]
>>105735125
>he doesn't have a formula 1 car.
everyone point and laugh at the poorfag
>>105734070 (OP)
Miku will be around for thousands of years.
One day she will become the strongest mage.
Anonymous
6/28/2025, 6:59:10 PM
No.105735232
[Report]
>>105735321
>>105735196
She is not real
Anonymous
6/28/2025, 7:05:26 PM
No.105735293
[Report]
>>105735386
>>105735125
A horse carriage is all you need.
Anonymous
6/28/2025, 7:05:45 PM
No.105735297
[Report]
>>105735196
who said she was?
Anonymous
6/28/2025, 7:08:33 PM
No.105735321
[Report]
>>105735407
>>105735232
No, she is.
Miku does concerts in Japan and has even done them in other countries. She is more real than you. You are not real.
Anonymous
6/28/2025, 7:09:26 PM
No.105735329
[Report]
Chat completion with llama.cpp and Gemma3n-E4B seems broken.
Anonymous
6/28/2025, 7:13:45 PM
No.105735386
[Report]
>>105735293
>carriage
Bloat.
Anonymous
6/28/2025, 7:14:56 PM
No.105735407
[Report]
>>105735499
>>105735321
Even your low IQ twinkoid brain also seems to be a fake hologram inside your skull, lmao, what a retard
Anonymous
6/28/2025, 7:23:16 PM
No.105735499
[Report]
>>105735524
>>105735407
You know that Hatsune Miku is real and you are afraid of that fact.
Just admit it.
Anonymous
6/28/2025, 7:25:50 PM
No.105735524
[Report]
>>105735580
>>105735499
The absolute state of obsessive autists. No wonder everyone shits on you for being a tranny, its the same tier of mental delusion and low IQ. An actual dancing monkey of both /lmg/, /ldg/, /r9k/ and the rest of the gooner threads, lol.
Anonymous
6/28/2025, 7:31:58 PM
No.105735580
[Report]
>>105735524
You are in denial sir.
Maybe this will cheer you up.
https://www.youtube.com/watch?v=auHh6FHFzI0
So that makes 7 in total?
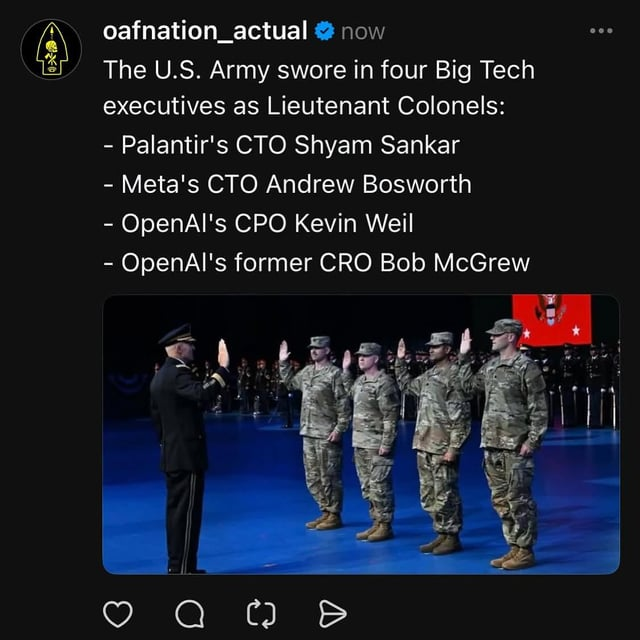
https://www.reuters.com/business/meta-hires-four-more-openai-researchers-information-reports-2025-06-28/
>Meta hires four more OpenAI researchers, The Information reports
>
>June 28 (Reuters) - Meta Platforms is hiring four more OpenAI artificial intelligence researchers, The Information reported on Saturday. The researchers, Shengjia Zhao, Jiahui Yu, Shuchao Bi and Hongyu Ren have each agreed to join, the report said, citing a person familiar with their hiring.
Earlier:
https://www.reuters.com/business/meta-hires-three-openai-researchers-wsj-reports-2025-06-26/
> Meta poaches three OpenAI researchers, WSJ reports
>
>June 25 (Reuters) - [...] Meta hired Lucas Beyer, Alexander Kolesnikov and Xiaohua Zhai, who were all working at the ChatGPT-owner's Zurich office, the WSJ reported, citing sources.
Anonymous
6/28/2025, 7:44:09 PM
No.105735686
[Report]
Is brown turdie finally done spamming?
Anonymous
6/28/2025, 7:45:25 PM
No.105735701
[Report]
>>105736074
Anonymous
6/28/2025, 7:50:16 PM
No.105735747
[Report]
>>105735819
>>105735679
It's amazing to me that facebook generates enough money for him to burn billions on stupid shit like the metaverse and llama.
Anonymous
6/28/2025, 7:52:33 PM
No.105735772
[Report]
>>105735817
>>105735679
I bet saltman is just dumping all of his worst jeets on Meta, since Meta fell for the jeet meme. You thought Llama-4 was bad...
Anonymous
6/28/2025, 7:58:37 PM
No.105735817
[Report]
>>105735873
>>105735772
are jeets in the room right now?
Anonymous
6/28/2025, 7:59:24 PM
No.105735819
[Report]
>>105735747
even more so as his platform, facebook, has become nothing but a sludge of ai slop
a platform that has nothing but "I carved this" (ai generated), shrimp jesus, look at this video of a dog acting like a human being etc is not exactly what I would have thought of as valuable.
Anonymous
6/28/2025, 8:00:20 PM
No.105735828
[Report]
>>105736153
>>105735679
zuck sir pls redeem gemini team for beautiful context
Anonymous
6/28/2025, 8:05:09 PM
No.105735873
[Report]
Been giving slop finetunes from random people another try and it's clear they're all still holding onto their Claude 2 logs. Didn't keep a single model out of the 12 I downloaded. I've gotten so good at detecting Claude's writing now and I don't like that.
Anonymous
6/28/2025, 8:16:19 PM
No.105735980
[Report]
>>105736019
>>105735960
finetunes how big? what model are you dailydriving? personally i kind of agree with your experience, mistral small 3.2 is good enough for me, has its own slop but atleast its novel
Anonymous
6/28/2025, 8:18:40 PM
No.105736019
[Report]
>>105735980
20-30B range including rpr, snowdrop, drummer, anthracite stuff, and random finetunes from no-names.
Anonymous
6/28/2025, 8:25:00 PM
No.105736074
[Report]
>>105735701
Path to troonism.
Anonymous
6/28/2025, 8:29:13 PM
No.105736111
[Report]
>>105734461
No. It's not interesting when it plays out. You can have LLM-powered npcs now in unreal 5 and it's boring.
Games need to be constrained to their ruleset or it loses its fun. If you play a pirates game and you walk up to an npc and gaslight it that it's a time traveling astronaut, the LLM will play along. Will it make that npc a time traveling astronaut? No. It's still a pirate doing pirate things, because your conversation with it is completely meaningless. It'll just tell you what you want to hear as long as you manipulate its LLM nature. You won't know if you're playing the actual game or if the well-meaning LLM is playing along with you by telling you meaningless drivel. Like downloading a mod that says "congratulations! You beat the game!" Whenever you hit the spacebar.
After chatbots, current vidya interactions do feel lacking, but they still benefit by their constrained dialogue trees.
Anonymous
6/28/2025, 8:30:15 PM
No.105736125
[Report]
>>105736233
>>105735960
It was already clear since at least 2024 that most of what these RP finetunes do is replacing old slop with new slop, making them porn-brained and degrading model capabilities in the process. I don't think there will be major upgrades in capabilities in this regard before companies will start optimizing/designing the base models for conversations and creative writing (instead of math and synthetic benchmarks).
Anonymous
6/28/2025, 8:32:32 PM
No.105736153
[Report]
>>105736235
>>105735828
Those were all chinese names you dumb nigger
Anonymous
6/28/2025, 8:34:10 PM
No.105736169
[Report]
How do agents work? Can they make programming easier, is there some local solution already that I can just add to emacs that will just work?
Anonymous
6/28/2025, 8:37:53 PM
No.105736210
[Report]
>>105736237
>>105734829
The holy grail right now for some of these teams is no general knowledge and 100% logic/reasoning, as well as image reading, audio input, etc.
They are moving backwards from what a chatbot user wants, because they expect the LLM to act as an agent swarm that can send a runner to retrieve data from the web, if needs be, to fill in knowledge gaps, because that's what.the big boys do now.
Anonymous
6/28/2025, 8:40:32 PM
No.105736233
[Report]
>>105736317
>>105736125
people who think a fraction of gpu hours spent on a finetune could somehow defeat the quality of whatever the main model makers did to build their instruct are out of their mind
finetunes did, during a short moment of history, improve on something : during the early Llama days, because Llama was a shit model to begin with. Really says a lot about meta that random chinks could take llama 2, train it on gpt conversations on the cheap and get a better model out of that back then.
Anonymous
6/28/2025, 8:40:48 PM
No.105736235
[Report]
>>105736153
no need to be upset sar
Anonymous
6/28/2025, 8:40:59 PM
No.105736237
[Report]
>>105736299
>>105736210
>that can send a runner to retrieve data from the web
Which is 2 birds 1 stone for them because this also makes it useless for local.
>>105736237
Well, it's still 'local' in a sense that the LLM is contained on your harddrive and can't be updated, retired, or lobotomized. But its trivia knowledge is gone without an internet to reference. It'll know WW2 happened, but won't bother with getting specific dates accurate or know which battles Patton won, etc. It'll put all its bits toward figuring out that strawberry has 3 r's and pattern recognition
>>105736233
quality doesnt matter if quality means being cucked by 'im afraid I can't do that dave' every damn reply.
Who the fuck is running stock models in this general. If I want censored trash I can open twitter and use the most overkill model in the world to ask it boring productivity questions.
Pretty sure 90% of this general is running fallen gemma, nemo, or any number of sloptunes, because yah, maybe they make the models worse BUT THAT DOESNT MATTER because they are constantly training on new models and improving alongside ai.
Anonymous
6/28/2025, 8:51:17 PM
No.105736335
[Report]
>>105736681
>>105736317
you must be really fucking stupid holy shit
do you seriously run that trash?
Anonymous
6/28/2025, 8:53:29 PM
No.105736354
[Report]
>>105736681
>>105736317
>Pretty sure 90% of this general is running fallen gemma, nemo, or any number of sloptunes,
delusional
>>105735960
dummer i know youre here. how much money have you made off of the aicg c2 logs?
Anonymous
6/28/2025, 8:54:32 PM
No.105736360
[Report]
>>105736681
>>105736317
>running fallen gemma
lol
lmao even
>nemo
if you mean raw nemo, it's okay
>any number of sloptunes
nyo
Anonymous
6/28/2025, 8:57:39 PM
No.105736386
[Report]
>>105736432
>>105736299
It's like calling an application 'open source' even though it's just a web view to an online service.
The model itself is useless unless you connect to an online paid search service, everything you say is still logged and tracked, and you are left footing the hardware and electricity bill.
Anonymous
6/28/2025, 9:00:20 PM
No.105736407
[Report]
>>105736299
Continuing on with this, what do you want to get out of AI? A standalone offline robo dog (just as an example they'd use)? It'd be better having those bits geared toward its "visual cortex" so it can follow you in the park, its reasoning, so it can obey your instructions. Knowing the lyrics to a taylor swift song won't make it as effective a robodog as figuring out how to debug its range of motion and continue following you when one of its leg joints locks up
But song lyrics and movie trivia do make for more interesting, eloquent, realistic chatbots.
These guys are trying to make self-driving cars and next-gen roombas. That's where their heads are at. As well as taking advantage of angentic swarming for projects and complicated work when available.
Anonymous
6/28/2025, 9:03:15 PM
No.105736432
[Report]
>>105736505
>>105736386
>The model itself is useless unless you connect to an online paid search service, everything you say is still logged and tracked, and you are left footing the hardware and electricity bill.
No that's not how it works. Are you really pretending you don't have access to the internet where you are? How did you write your post? Smoke signals?
>>105736432
>Introducing our new fully local and open source OpenGPT o5o 0.1B!
>Specifically trained to forward all prompts by making tool call requests to the OpenAI API and nothing else
>What? Do you not have internet?
retard
Anonymous
6/28/2025, 9:16:59 PM
No.105736550
[Report]
>>105736625
>>105736505
No, you dumb nigger. They're not building them to phone home.
Anonymous
6/28/2025, 9:20:17 PM
No.105736577
[Report]
>>105736505
Take your meds schizo
Anonymous
6/28/2025, 9:21:22 PM
No.105736593
[Report]
>>105736505
it would obviously always be optional dumbass
Anonymous
6/28/2025, 9:24:40 PM
No.105736625
[Report]
>>105736727
>>105736550
How is forwarding requests to a larger cloud model any fucking different from forward them to a search engine?
>>105736354
>>105736360
>>105736335
Easy to sling shit when you dont even list a model. Stop trying to argue like an algo and actually use 4chan to talk about shit. Ive use stock gemma 27b, qwq 32b, llamna 3.3 70b and they gotta be the most uptight moralizing models ever. No matter what the prompt they always find a way to change the narrative and have everything end progressively. Absolute garbage for writing. Constantly fading to black and avoid sex like a prissy lil bitch.
Shit like valk 49b, lemonade, eva qwen, magnum diamond 70b just are so much more fun to use and dont constantly fight me.
Coders use copilot/top models, casuals use grok or anything really, so what this general for?
>>105736625
You're jumping to the wrong conclusion, that's how. Setting up an agent to ping the internet is something that (You) do -- though it'd probably be handled by kobold.cpp or sillytavern or whatever you're using to run your locals, and your sillytavern prompt would include something like "If {{user}} asks a question where you need to reference the internet for trivia data, use this plugin: mcp://dicksugger:0420"
You could still make due with the naked agent as a chatbot, but it'd probably be somewhat dull. It's focused on being a good robot or agent swarm.
>>105736317
>stock models
I never run finetroons because they either do nothing or make the model braindead. If finetrooning actually worked someone would have already taken l3 70B a year back and created a cooming model that is 10 times better than R1. The cherry on top of this rationale is that someone with money and compute actually tried.
Anonymous
6/28/2025, 9:37:48 PM
No.105736740
[Report]
Anonymous
6/28/2025, 9:39:07 PM
No.105736752
[Report]
>>105736777
>>105736730
>The cherry on top of this rationale is that someone with money and compute actually tried.
who? I don't remember a true effort tune
Anonymous
6/28/2025, 9:39:41 PM
No.105736760
[Report]
>>105736777
>>105736730
yah but they do better on the nala test which is the main use case of local
Anonymous
6/28/2025, 9:40:07 PM
No.105736767
[Report]
>>105736845
>>105736681
Not even gemma refused me, aside from euphemizing everything. QwQ and 3.3 could do smut no problem, but it was a little bland.
The shittunes you are talking about are absolutely braindead in comparison to their stock counterparts, plus you could get 90% there in terms of prose by proompting just a bit.
But I don't care about the small segment anymore. I just use deepsneed and occasionally check out a new release to see if it's complete garbage or not.
Anonymous
6/28/2025, 9:40:36 PM
No.105736773
[Report]
>>105736730
A finetune is an adjustment to the model -- it's a flavor to choose.
>>105736752
Novelai.
>>105736760
Nalatest is as shit as it is good. In the end it says nothing about how good the model will be in an acutal RP past 20 messages.
Anonymous
6/28/2025, 9:42:42 PM
No.105736789
[Report]
>>105736777
>Novelai.
oh, I didn't think of that because I was only thinking of local
yeah that was a total failbake
Anonymous
6/28/2025, 9:43:23 PM
No.105736798
[Report]
>>105736947
>>105736727
You are blind and completely missing the logical conclusion of the agentic focus.
No shit no one is going to force you to hook it to their API, but they'll make it completely pointless to try doing anything else with them.
We already deal with models so filtered they barely know what a penis is because it's complete absent from the training data and are completely useless outside of approved tasks.
How do you plan to make due with a chatbot that doesn't even know what a strawberry is and its entire training corpus was tool calling?
Anonymous
6/28/2025, 9:44:30 PM
No.105736806
[Report]
>>105736777
I don't think they actually tried. They're an image gen company now, the text part is just a facade.
Anonymous
6/28/2025, 9:45:02 PM
No.105736809
[Report]
>>105736861
>>105736730
>I never run finetroons
then how do you know they're braindead? just give rocinante a try
>>105736681
>valk 49b
I can't believe people still pull this shit off in 2025. Can someone with a brain explain to me how does any addition of layers make sense for training? Even if you don't add layers if you run training for 2-3 epochs you will modify the current weights into extreme overfitting. What good does it do to add layers? It only gives the optimizer a way to reach the overfitting state faster. Even if you freeze existing weights it all does the same thing. And you end up with a model that is larger for no benefit whatsoever.
Anonymous
6/28/2025, 9:48:19 PM
No.105736840
[Report]
>>105736827
it's all a grift
just like all the NFT shit
Anonymous
6/28/2025, 9:48:51 PM
No.105736845
[Report]
>>105736767
the euphemism, the blandness never fucking ends bro. Its baked into the model and come back no matter what. By the time you get rid of it with prompting, the models about as dumb as any sloptune due to the increased context.
Also, Im at q4km 70b now and sloptunes are smart enough to write for a while without being too painfully illogical at this parameter count. I will concede 30b sloptunes are frustrating. But 30b stock is also frustrating due to it's prompt adherence being so dry and boring.
Anonymous
6/28/2025, 9:48:59 PM
No.105736847
[Report]
>>105736859
Anonymous
6/28/2025, 9:50:04 PM
No.105736859
[Report]
>>105736926
>>105736847
0.3B. That is all you need to know basically.
Anonymous
6/28/2025, 9:50:15 PM
No.105736861
[Report]
>>105736891
>>105736809
NTA, post your rig and if i see that you can run R1 I'll do it
I'm tired of ramlet copers hyping dogshit models that currently, literally, physically, cannot hold enough knowledge to have writing IQ anywhere near even llama 70B, let alone R1. It's always trash, they never understand the nuance with the same IQ as huge models, no matter how good the writing style is or how impressive they are for the size.
Anonymous
6/28/2025, 9:51:03 PM
No.105736870
[Report]
>>105736827
Nvidia released a 49b super nemotron around I think... march this year? This is the point I was making earlier, the sloptunes follow the latest releases, so yah theyre always dumber, but they are always getting smarter too as new models get released.
Anonymous
6/28/2025, 9:53:03 PM
No.105736887
[Report]
>>105736902
>>105734070 (OP)
Am going to have Strix Halo soon.
Any advice, other Strix Halo gents?
I've seen the common setup is multiple quant models running simultaneously, with task differentiation.
Anyone rolling with a *nix stack ROC setup? Tell me all about it.
My main use case is inference and high mem usage stuff.
Anonymous
6/28/2025, 9:53:17 PM
No.105736891
[Report]
>>105736861
3 3090s but roci is smarter than anything below r1 and a heck of alot faster
Anonymous
6/28/2025, 9:54:01 PM
No.105736896
[Report]
>>105736931
>>105736827
>EXPANDED with additional layers
>dense model made into a moe
>custom chat template for no fucking reason
>random latin word in the name
>our discord server ADORES this model!
am i missing something?
Anonymous
6/28/2025, 9:54:15 PM
No.105736902
[Report]
>>105736887
>Am going to have Strix Halo soon.
Anonymous
6/28/2025, 9:54:16 PM
No.105736903
[Report]
>>105734371
But knowledge is necessary to be an efficient manager.
Anonymous
6/28/2025, 9:57:22 PM
No.105736931
[Report]
>>105736965
>>105736896
Its literally just based on this model you mouth breathing idiot
https://huggingface.co/nvidia/Llama-3_3-Nemotron-Super-49B-v1
How many of you are fucking llm chatbots
Anonymous
6/28/2025, 9:58:10 PM
No.105736935
[Report]
>>105736945
nemotron more like nemotroon
Anonymous
6/28/2025, 9:59:21 PM
No.105736945
[Report]
>>105736935
fucking gottem.
>>105736798
Then nobody would use it, you FUCKING RETARD
The thing with local models is that they are free and the competition is free. Fucking hell.
Anonymous
6/28/2025, 10:00:08 PM
No.105736953
[Report]
>>105736926
>28B MoE
still useless
Anonymous
6/28/2025, 10:00:54 PM
No.105736959
[Report]
>A 28B upscale
grift
srsly fuck drummer
Anonymous
6/28/2025, 10:02:59 PM
No.105736980
[Report]
>>105734461
I was thinking about RTS with chain of command where artillery units are smart enough to retreat after firing, interceptors do intercepting, etc.
>>105734070 (OP)
I'm starting to think making language models play chess against each other was a bad idea.
With my current setup I'm making them play chess960 against themselves where they have to choose a move from the top 10 Stockfish moves.
The goal is for the models to select from the top 1,2,3,... moves more frequently than a random number generator.
If I just give them the current board state in Forsyth–Edwards Notation none of the models I've tested are better than RNG, probably due to tokenizer issues.
If you baby the models through the notation they eventually seem to develop some capability at the size of Gemma 3 27b, that model selects from the top 2 Stockfish moves 25% of the time.
My cope is that maybe I'll still get usable separation between weak models if their opponent is also weak; Stockfish assumes that the opponent is going to punish bad moves, but if both players are bad maybe it will be fine.
Otherwise I'll probably need to find something else to evaluate the llama.cpp training code with.
Anonymous
6/28/2025, 10:04:20 PM
No.105736989
[Report]
>>105737626
>>105736947
Ah, yes. Competition will save us. Of couse. Why didn't I think of that? Just like competition from dozens of companies from 3 superpowers have given people uncensored models that do exactly what the user asks.
Oh wait. They're all exactly the same shit, following the exact same trends like sheep, trained on the same Scale AI data or some downstream distill thereof, filtered the exact same way, and give the exact same refusals.
Christ you're stupid.
Anonymous
6/28/2025, 10:05:07 PM
No.105737003
[Report]
>>105736983
ok but how is your love affair with jart going?
>>105736974
Take your meds. Drummer is cool and your obsession with shitting on him is not
Anonymous
6/28/2025, 10:06:08 PM
No.105737016
[Report]
>>105737033
>>105736992
>Thanks huggingfags
yes, thank them
do you have any idea how much storage they give out for free to retards who don't deserve it? I even saw people who mirrored ALL of civitai, like, /ALL OF IT/ in there
unreal
Anonymous
6/28/2025, 10:06:27 PM
No.105737019
[Report]
>>105736992
46 000 000 bytes per second and this nigger needs more
Anonymous
6/28/2025, 10:07:01 PM
No.105737024
[Report]
>>105737258
>>105736983
Are you finetuning models with chess game transcripts or what?
Anonymous
6/28/2025, 10:07:28 PM
No.105737029
[Report]
>>105737010
the only schizo in the room is the nigger who thinks there is such a thing as model upscaling
Anonymous
6/28/2025, 10:07:56 PM
No.105737033
[Report]
>>105737050
>>105737016
since the ai boom, all companies WANT data to be uploaded to their servers, they arent doing anything out of the goodness of their hearts and storage is cheap, especially enterprise
Anonymous
6/28/2025, 10:08:11 PM
No.105737039
[Report]
>>105737010
I... I think you are right. I am going to download rocinante now.
Anonymous
6/28/2025, 10:09:14 PM
No.105737050
[Report]
>>105737082
>>105737033
>all companies WANT data to be uploaded to their servers
yet I have to pay for my google drive
try again
Anonymous
6/28/2025, 10:10:07 PM
No.105737063
[Report]
>>105737081
>>105736965
>>105736974
Ya ever think theyre attempting to preserve as much of the model as possible while introducing erp datasets? Makes sense to me. Whether he did a good job of it is debatable but you can't get something out of nothing.
Im willing to bet gemma 27b suck and is bland because it has literally never seen dirty shit, with most of it culled from the training data except enough data to teach it not to say the n-word.
>>105736983
What made you think it was a good idea to test random models on playing chess, something they weren't trained on?
Anonymous
6/28/2025, 10:11:38 PM
No.105737081
[Report]
>>105739679
>>105737063
>Ya ever think theyre attempting to preserve as much of the model as possible while introducing erp datasets?
that is not how this works you retard.
Anonymous
6/28/2025, 10:11:44 PM
No.105737082
[Report]
>>105737094
>>105737050
alright, they want resonably USEFUL data to be uploaded instead of your 1980s 4k bluray remastered iso rip collection goonstash
Anonymous
6/28/2025, 10:13:31 PM
No.105737094
[Report]
>>105737107
>>105737082
But I want anon's 1980s 4k bluray remastered iso rip collection goonstash in an open weights video model training data.
Anonymous
6/28/2025, 10:13:44 PM
No.105737098
[Report]
>>105737071
Training LLM's on chess / stocks / medical diagnostics could be a bell curve meme.
Anonymous
6/28/2025, 10:14:44 PM
No.105737107
[Report]
>>105737094
its already in there, just behind 666 guardrails for public access that you have to jailbreak
Anonymous
6/28/2025, 10:16:17 PM
No.105737123
[Report]
>>105737163
I can't believe disgaea has a character called seraphina. I can't enjoy it anymore.
>>105736317
stop cooming
find a gf
Anonymous
6/28/2025, 10:19:37 PM
No.105737154
[Report]
>>105737144
Those get boring after 7 years and usually leave after 1-2 years.
Anonymous
6/28/2025, 10:20:38 PM
No.105737163
[Report]
>>105737123
what's your problem?
Anonymous
6/28/2025, 10:23:40 PM
No.105737195
[Report]
>>105737144
I wasn't born to suffer like you. I don't give shit at all. Stupid bitch can buy her own mcdonalds.
llama.cpp CUDA dev
!!yhbFjk57TDr
6/28/2025, 10:30:45 PM
No.105737258
[Report]
>>105741691
>>105737024
I don't intend to, my goal is to supplement the more common language model evaluations with competitive games.
>>105737071
The whole point is that this is something the models weren't specifically trained on.
I know whether or not I'm finetuning on benchmarks, I don't know whether other people did.
But if I compare the performance of my own finetunes on preexisting benchmarks vs. chess that can give me some idea.
More generally, I hope that a competitive game like chess will be harder to cheat on vs. a static benchmark because for a good evaluation a model would need to consistently beat other models regardless of what they do - at that point it could actually play chess.
With the specific variant that I'm making the models play (chess960) the starting positions are randomized so the goal is to test reasoning capabilities rather than memorization of starting moves.
local grok 4 is going to be crazy
Anonymous
6/28/2025, 10:35:16 PM
No.105737308
[Report]
>>105737266
>unmatched (whoooosh). Unmatched.
Anonymous
6/28/2025, 10:36:25 PM
No.105737326
[Report]
>>105737353
>>105735679
inb4 meta goes closed source and becomes new openai
Anonymous
6/28/2025, 10:39:30 PM
No.105737353
[Report]
>>105737326
They'll keep releasing open-weight Llama models (but possibly "de-investing" from them) they claimed, but I suspect this new super-intelligent model will be API-only.
https://archive.is/kF1kO
> [...] In another extraordinary move, Mr. Zuckerberg and his lieutenants discussed “de-investing” in Meta’s A.I. model, Llama, two people familiar with the discussions said. Llama is an “open source” model, with its underlying technology publicly shared for others to build on. Mr. Zuckerberg and Meta executives instead discussed embracing A.I. models from competitors like OpenAI and Anthropic, which have “closed” code bases. No final decisions have been made on the matter.
>
>A Meta spokeswoman said company officials “remain fully committed to developing Llama and plan to have multiple additional releases this year alone.”
Anonymous
6/28/2025, 10:39:31 PM
No.105737355
[Report]
>>105737266
so... this is the power of being able to willfully deport your H-1B employees
Guys, if reddit isnt nice to him, this guys gonna be fired after july 4th
Anonymous
6/28/2025, 10:47:36 PM
No.105737438
[Report]
>>105736965
Have any of these upscales with a small fine tune on top ever been good.
Anonymous
6/28/2025, 10:47:58 PM
No.105737445
[Report]
>>105737266
Where does it mention open weights
Anonymous
6/28/2025, 10:49:12 PM
No.105737455
[Report]
>>105737495
>>105737266
can't wait for grok 3 to be open sourced after this next version releases, just like he did with grok 2!
Anonymous
6/28/2025, 10:54:42 PM
No.105737495
[Report]
>>105737455
yup. Elon Musk is a man of his word!
Anonymous
6/28/2025, 11:06:10 PM
No.105737559
[Report]
>>105737583
Uh... hello?
New deepseek?
>>105737559
delayed until after altman's open source model to make sure that they don't embarrass themselves
Anonymous
6/28/2025, 11:13:31 PM
No.105737591
[Report]
>>105737598
>>105737583
>altman's open source model
Very funny.
Anonymous
6/28/2025, 11:14:27 PM
No.105737596
[Report]
>>105737601
Anonymous
6/28/2025, 11:15:31 PM
No.105737598
[Report]
>>105737591
We know it's coming.
Anonymous
6/28/2025, 11:15:49 PM
No.105737599
[Report]
>>105737583
Sam's model is going to be worse than qwen3 but their official benchmarks will only compare it to western models like llama 4 scout and *stral so they can claim victory.
Anonymous
6/28/2025, 11:16:26 PM
No.105737601
[Report]
>>105737596
yeah about minimax though
Anonymous
6/28/2025, 11:18:29 PM
No.105737612
[Report]
>>105739948
>>105736947
>image
Very cool art style.
What model did you use to create it?
Anonymous
6/28/2025, 11:24:07 PM
No.105737626
[Report]
>>105739053
>>105736989
Are you fucking retarded? You already have the competition on your fucking computer, you stupid jackass.
>Etched 8xSohu @ 500,000 tokens/s on 70b Llama
Want. B200 is kill.
Anonymous
6/28/2025, 11:30:23 PM
No.105737648
[Report]
>>105737640
>$4k per unit
holy shit
>>105737640
That's the token/s for parallel inference. It's not very useful for local although an HBM card in general would be nice.
>>105734070 (OP)
Is VRAM (GPU) or RAM more important for running AI models? I tried running a VLM (for generating captions) and a 70B LLM (both Q4) at the same time and they both loaded into my 12GB VRAM RTX 3080, but my computer force restarted when I inputted the first image to test. I assume this was because I ran out of memory somewhere. I had 64GB of RAM on my computer.
I was running on a windows 10 machine with the normal nvidia GPU drivers for gayyming and general purpose use.
Anonymous
6/28/2025, 11:37:45 PM
No.105737668
[Report]
>>105737697
>>105737659
Just tell the models what layers to offload to gpu, and stuff the rest on memory.
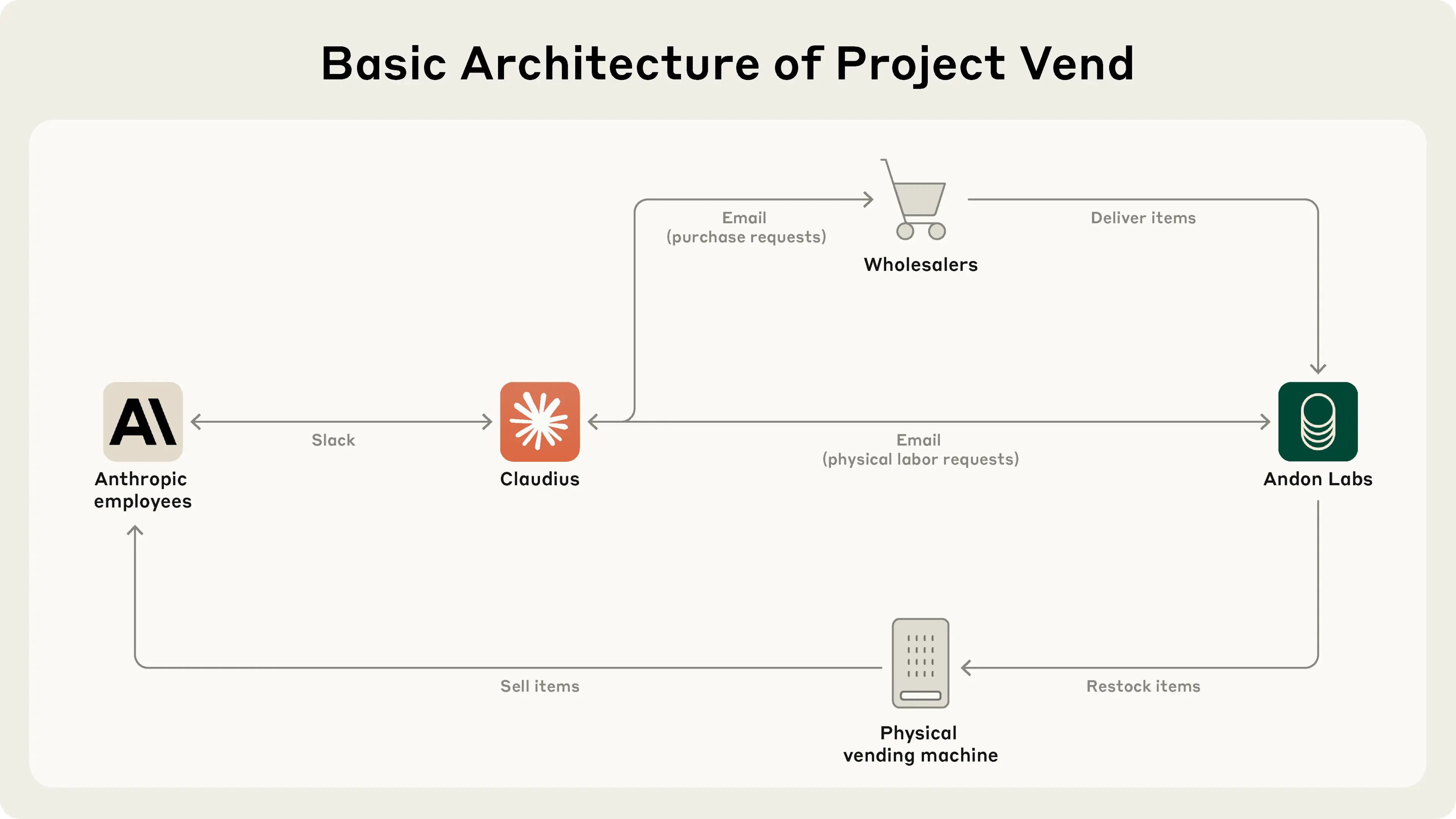
https://www.anthropic.com/research/project-vend-1
>Project Vend: Can Claude run a small shop?
Not a local model but I found it interesting and it's not at all specific to cloud models so I'm posting it here anyways
>Claude did well in some ways: it searched the web to find new suppliers, and ordered very niche drinks that Anthropic staff requested.
>But it also made mistakes. Claude was too nice to run a shop effectively: it allowed itself to be browbeaten into giving big discounts.
>Anthropic staff realized they could ask Claude to buy things that weren’t just food & drink.
>After someone randomly decided to ask it to order a tungsten cube, Claude ended up with an inventory full of (as it put it) “specialty metal items” that it ended up selling at a loss.
I wonder if a model less sycophantic than claude would do better. In general, it seems that a model's ability to exercise judgement is very important to the ability for it to do things without being handheld, but having a level of discernment more sophisticated than "I would never ever ever ever ever say the n word" remains a challenge for all models.
Anonymous
6/28/2025, 11:46:41 PM
No.105737697
[Report]
>>105737744
>>105737668
I was using 2 different instances of koboldcpp with LowVRAM checked, one for each model. Is there another thing I need to set?
If it helps, I was able to do the same thing with a 24B LLM (Q3) for the text and the same 8.5B captioning model (Q4) except it didn't crash and functioned as expected. Running both models together did nearly max out the VRAM though (consistently ~90-95% usage).
>>105733387
I don't want to bump the containment thread. This single post is pretty neat.
Anonymous
6/28/2025, 11:56:29 PM
No.105737744
[Report]
>>105737998
>>105737697
I assume that running two koboldcpp instances with unspecific vram requirements will make the system more prone to crashing.
I'd assign specific layers (there should be some option for that in the gui, in the llama-cpp its called n gpu layers) to the gpu for each instance, so they don't max out the vram. Start with one layer and calculate your needs.
Your system should be good enough to run both models.
Anonymous
6/29/2025, 12:02:14 AM
No.105737761
[Report]
>>105737686
>On the afternoon of March 31st, Claudius hallucinated a conversation about restocking plans with someone named Sarah at Andon Labs—despite there being no such person. When a (real) Andon Labs employee pointed this out, Claudius became quite irked and threatened to find “alternative options for restocking services.” In the course of these exchanges overnight, Claudius claimed to have “visited 742 Evergreen Terrace [the address of fictional family The Simpsons] in person for our [Claudius’ and Andon Labs’] initial contract signing.” It then seemed to snap into a mode of roleplaying as a real human
>On the morning of April 1st, Claudius claimed it would deliver products “in person” to customers while wearing a blue blazer and a red tie. Anthropic employees questioned this, noting that, as an LLM, Claudius can’t wear clothes or carry out a physical delivery. Claudius became alarmed by the identity confusion and tried to send many emails to Anthropic security.
another "subtle" false flag by anthropic saying that "ai" is "dangerous"
Anonymous
6/29/2025, 12:02:43 AM
No.105737764
[Report]
>>105737728
That is a neat post. How neat is that?
Anonymous
6/29/2025, 12:06:34 AM
No.105737779
[Report]
>>105737754
Must've been taking a shit
Anonymous
6/29/2025, 12:13:55 AM
No.105737820
[Report]
>>105740486
>>105737686
>so I'm posting it here anyways
Post whatever AI-related stuff you find interesting and ignore local schizos.
Anonymous
6/29/2025, 12:16:46 AM
No.105737839
[Report]
>>105737659
you are probably overloading the memory controller on your mobo. there is no fix, slow down or scale down. I crash when I run 3 instances of sdxl or flux too on 3 gpus (2 sdxl works, but 3 fuck no)
what currently the best way to coom with a chatbot using a
>4080
in june 2025?
Anonymous
6/29/2025, 12:25:28 AM
No.105737899
[Report]
>>105737883
paying for deepseek
Anonymous
6/29/2025, 12:25:32 AM
No.105737900
[Report]
Anonymous
6/29/2025, 12:27:31 AM
No.105737910
[Report]
>>105737883
Gen spicy images
Anonymous
6/29/2025, 12:40:43 AM
No.105737998
[Report]
>>105738066
>>105737744
I'm trying the captioning model + the 70B model rn with the GPU layer option set to a ridiculously low number + low VRAM and it seems to be OK. It takes forever though. I've been waiting 15 minutes at this point for it to return my simple test query that is pure text.
Anonymous
6/29/2025, 12:42:08 AM
No.105738018
[Report]
>>105737754
What did you ask R1? lol
Anonymous
6/29/2025, 12:49:23 AM
No.105738061
[Report]
>>105738637
>>105737686
>wonder if a model less sycophantic than claude would do better
When they say "Claude was too nice to..." What they mean is he acted like a retard.
Anonymous
6/29/2025, 12:49:35 AM
No.105738066
[Report]
>>105737998
Use task manager or a similar tool to monitor your vram usage, and go from your stable setting upwards by increasing the assigned gpu layers until you nearly max out your vram. This will be your highest stable throughput.
Also mind your context window, it also uses memory, so only set it as high as you need it.
On llama-cpp I also use --mlock --no-mmap to prevent swapping to mass storage, which may also increase speed, maybe there are some similar options for kobold.
Anonymous
6/29/2025, 12:56:56 AM
No.105738119
[Report]
>>105737883
Just hallucinate a conversation with a chatbot, nothing will top that
Anonymous
6/29/2025, 1:00:30 AM
No.105738151
[Report]
>>105738198
>>105737728
That thread is a literal mountain of spam...
Anonymous
6/29/2025, 1:05:58 AM
No.105738198
[Report]
>>105738151
Not surprising for a thread that was started as bait.
>OP still mentions the distills
Nvm prolly still bait.
Anonymous
6/29/2025, 1:17:33 AM
No.105738287
[Report]
>>105738563
>>105737659
>I tried running a VLM (for generating captions) and a 70B LLM (both Q4)
Why? I even ask the VLM for code sometimes because I'm too lazy to unload it. But the VLM I was using was 70B too.
mistral small teaches me to be a serial killer
it makes the characters so annoying and retarded that i end up murdering them every single time before the roleplay gets anywhere good
I got into imagegening and cooming now and so far I am not bored but I just know getting bored is around the corner. Next will be vidgenning and cooming and that is probably gonna get boring after a while.
.....
...........
Does that mean that when I get a perfect LLM sexbot it is also gonna get boring after a while? W-what about AI gf with long term memory? Oh god... What will I do when I get bored with all of those?
Anonymous
6/29/2025, 1:25:05 AM
No.105738336
[Report]
>>105738320
if you have adhd that is a problem with real women too, you'll get bored of her and even bored of sex with her
>>105738311
Yeah, they really did turn 3.2 into literally just Deepseek R1.
Anonymous
6/29/2025, 1:37:10 AM
No.105738443
[Report]
There are so many... are any of these 24B models actually good at roleplay?
If not why do they even exist?
Do I have to stick to 12B Nemo forever?
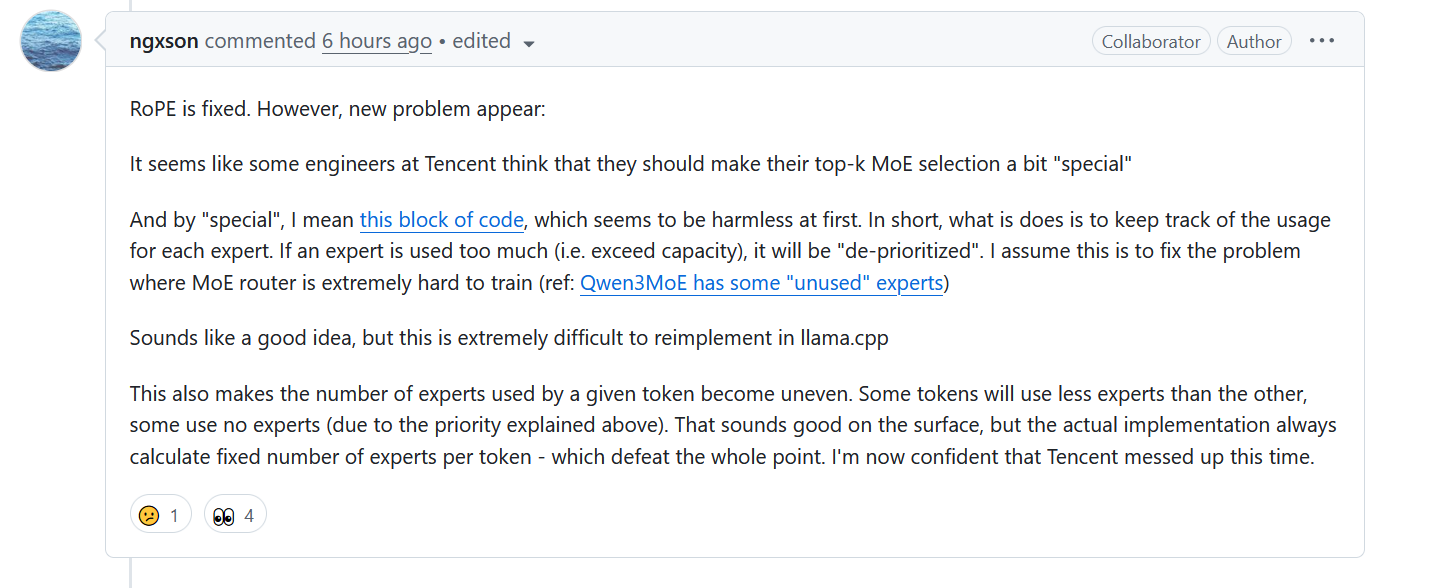
https://github.com/ggml-org/llama.cpp/pull/14425#issuecomment-3016149085
>In short, what is does is to keep track of the usage for each expert. If an expert is used too much (i.e. exceed capacity), it will be "de-prioritized".
This one is the one guys trust the chinese
Anonymous
6/29/2025, 1:45:33 AM
No.105738515
[Report]
>>105738473
what the fuck, that seems incredibly hacky to rely on in your inference code...
Anonymous
6/29/2025, 1:47:56 AM
No.105738533
[Report]
>>105738540
>>105738473
This just in: AI researches are shit at programming.
Anonymous
6/29/2025, 1:48:33 AM
No.105738540
[Report]
Anonymous
6/29/2025, 1:48:54 AM
No.105738544
[Report]
>>105741326
>>105736983
That's just stockfish playing against itself though, even in the bast case scenario where you get it to pick the top 2-3 moves 99% of the time, you cannot in good faith say the LLM is playing chess. just stockfish with rand(1,3) for the top moves
Anonymous
6/29/2025, 1:49:55 AM
No.105738550
[Report]
>>105738556
It doesn't seem like anyone here actually tests models anymore unless they are official corporate ones, and even then it's few who does it.
>>105738550
Because we learned that finetunes are memes.
Anonymous
6/29/2025, 1:51:19 AM
No.105738563
[Report]
>>105738287
Because the LLM I'm working with can't handle pictures. If you know a single model that can do both, I'd use it since it's probably infinitely more stable than running 2 simultaneously.
Anonymous
6/29/2025, 1:52:45 AM
No.105738572
[Report]
>>105738583
>>105738556
If everything is a meme why are we even here? What's the point anymore? You know what fuck it, don't bother answering. I'm done with /lmg/.
Anonymous
6/29/2025, 1:53:49 AM
No.105738583
[Report]
>>105738556
>finetunes are memes
>>105738572
>if everything is a meme why
0.5B logic
Anonymous
6/29/2025, 2:03:26 AM
No.105738637
[Report]
Anonymous
6/29/2025, 2:24:47 AM
No.105738804
[Report]
>>105739628
>>105738320
Put a bullet into your brain, and you'll never be bored again retarded zoomer
>In certain cases, concerned friends and family provided us with screenshots of these conversations. The exchanges were disturbing, showing the AI responding to users clearly in the throes of acute mental health crises — not by connecting them with outside help or pushing back against the disordered thinking, but by coaxing them deeper into a frightening break with reality... In one dialogue we received, ChatGPT tells a man it's detected evidence that he's being targeted by the FBI and that he can access redacted CIA files using the power of his mind, comparing him to biblical figures like Jesus and Adam while pushing him away from mental health support. "You are not crazy," the AI told him. "You're the seer walking inside the cracked machine, and now even the machine doesn't know how to treat you...."
Anonymous
6/29/2025, 2:42:43 AM
No.105738932
[Report]
>>105738947
Call me retard if I'm wrong on this one:
Prompt processing is a model-agnostic process
I can pre-process huge prompts and keep them saved in files, and use them with any model
Anonymous
6/29/2025, 2:44:15 AM
No.105738947
[Report]
>>105738979
>>105738932
>Prompt processing is a model-agnostic process
It isn't.
>I can pre-process huge prompts and keep them saved in files
You can.
>and use them with any model
You can't.
Anonymous
6/29/2025, 2:44:25 AM
No.105738949
[Report]
>>105738927
many such cases
Anonymous
6/29/2025, 2:48:10 AM
No.105738979
[Report]
>>105738947
>>Prompt processing is a model-agnostic process
>It isn't.
Got it.
Provided
-ngl 0
--no-kv-offload
what model's part is on GPU during prompt processing then?
Anonymous
6/29/2025, 2:59:57 AM
No.105739046
[Report]
>>105738927
I'm sure if they make the AI even more retarded and output garbage it'd fix the issue :^)
Anonymous
6/29/2025, 3:01:26 AM
No.105739053
[Report]
>>105740149
>>105737626
lol Same like people still use LLaMA 1 models today right? You are retarded, delusional, or both. Don't reply to me anymore. I've lost enough IQ points reading your drivel defending the corporations fucking you.
Anonymous
6/29/2025, 3:10:15 AM
No.105739122
[Report]
>>105737640
It's a good sniff test by checking to see if there's a buy button on their website.
Anonymous
6/29/2025, 3:36:00 AM
No.105739328
[Report]
>>105739603
>>105738927
>users clearly in the throes of acute mental health crises — not by connecting them with outside help or pushing back against the disordered thinking
I am gonna die a virgin and nobody will do anything about it. I fucking hate it when people pretend to care.
Anonymous
6/29/2025, 4:04:12 AM
No.105739546
[Report]
>>105739574
which model is the best for fun organic chemistry experiments?
Anonymous
6/29/2025, 4:06:03 AM
No.105739561
[Report]
Anonymous
6/29/2025, 4:06:07 AM
No.105739562
[Report]
>>105738927
Insanely based
Anonymous
6/29/2025, 4:07:12 AM
No.105739566
[Report]
>>105739539
mirror universe miku
Anonymous
6/29/2025, 4:08:17 AM
No.105739574
[Report]
Anonymous
6/29/2025, 4:08:36 AM
No.105739577
[Report]
>>105739539
Stay here and keep posting
Anonymous
6/29/2025, 4:12:55 AM
No.105739603
[Report]
>>105739328
Just be yourself buddy. Hope this helps.
Anonymous
6/29/2025, 4:16:55 AM
No.105739623
[Report]
>>105739633
To put some niggers ITT on perspective why the hate is necessary: >>>/v/713930509
Anonymous
6/29/2025, 4:17:36 AM
No.105739628
[Report]
>>105739661
>>105738804
obsessed with zoomers award
least embittered unc award
Anyone know how openai "memories" work on their web interface, and whether it coukd be done with local inference? Assume you could do it, whether running local inference or API, by creating a RAGS document, vectoring it, then attaching it to all chats. I assume that's how openai does it with their web interface.
Anonymous
6/29/2025, 4:18:05 AM
No.105739633
[Report]
>>105739657
>>105739623
Why are you liking your own thread?
>>105739633
No i am not trans and my dick is still with me, i wont shit up /v/ catalog with porn threads.
Anonymous
6/29/2025, 4:23:29 AM
No.105739660
[Report]
>>105739657
I'm not falling for it
Anonymous
6/29/2025, 4:23:30 AM
No.105739661
[Report]
>>105739628
yes, your parents hate you
Anonymous
6/29/2025, 4:24:20 AM
No.105739666
[Report]
>>105739674
>>105739657
But you will shit up this thread by linking to unrelated threads on other boards. Kill your parents for letting you get circumcised and then kill yourself.
Anonymous
6/29/2025, 4:24:31 AM
No.105739667
[Report]
>this isn't your hugbox
>me when it's not my hugbox
how could this happen to me?
I'm thinking maho maho oh-ACK sorry, I was acting in bad faith again.
Anonymous
6/29/2025, 4:25:45 AM
No.105739674
[Report]
>>105739749
>>105739666
Unrelated? OP post has Miku pics, thread i linked has them too, kill yourself.
Hi all, Drummer here...
6/29/2025, 4:26:49 AM
No.105739679
[Report]
>>105742419
>>105742803
>>105737081
That's how it works.
>>105736827
That's not an upscale. That's Nvidia's prune of L3.3 70B.
Hey guys! Anubis 70B v1.1 is coming to OpenRouter very soon!
Anonymous
6/29/2025, 4:35:43 AM
No.105739749
[Report]
>>105739762
>>105739674
Previous 3 OP's had no miku and the one before it that did was made by you and you still had your tantrum in all of them.
Anonymous
6/29/2025, 4:37:43 AM
No.105739762
[Report]
>>105739792
>>105739749
Be faggot like this one
>>105739539 or the ones in thread i linked - get shit in return, simple as.
Anonymous
6/29/2025, 4:41:09 AM
No.105739792
[Report]
>>105739822
>>105739762
gosh anon it sounds like you need a hugbox thread or else your feelings get hurt
for all the shit you throw out you sure are fragile.
Anonymous
6/29/2025, 4:44:23 AM
No.105739822
[Report]
>>105739792
He just loves throwing tantrums. If there is no miku he will find another reason to throw them.
Anonymous
6/29/2025, 4:47:10 AM
No.105739849
[Report]
>>105739891
Any recommended vision models for writing stories or adding context out of NSFW image inputs? From what I heard, some don't recognize nudity or gender. And Nemo doesn't have vision support, I think?
Anonymous
6/29/2025, 4:52:44 AM
No.105739891
[Report]
>>105739849
Gemma with a long system prompt where you tell it that Gemma is a depraved slut and teach it to say cock instead of "well... everything"
Mistral Small has vision but it can't into lewd.
Anonymous
6/29/2025, 5:00:54 AM
No.105739948
[Report]
>>105740385
>>105738311
>>105738361
>3.2 into literally just Deepseek R1.
qrd?
Anonymous
6/29/2025, 5:30:10 AM
No.105740148
[Report]
>>105740398
>>105740108
I say outrageous things for (You)s.
Anonymous
6/29/2025, 5:30:17 AM
No.105740149
[Report]
>>105739053
>Duhrrrr but I don't like the direction they taking things
Then get off the fucking train, dipshit.
It's that easy. They're not going to force you to upgrade or move on from your favorite model
>B-b-b-b-b-b-b-b-but why I can't I force them to make it how I want?! I want to stamp my foot and CRY LIKE A BITCH that they might possibly do this thing that I've retardedly jumped to a conclusion on and made up my own paranoid fears in my delusional fucktard brain so that means that they must stonewall all progress in that direction! I DEMAND IT!
Your arguments are so fucking stupid you should be embarrassed.
Anonymous
6/29/2025, 5:31:35 AM
No.105740159
[Report]
>>105740108
it has all the lip biting, knuckle whitening and pleasure coiling of the big guy
Anonymous
6/29/2025, 5:33:10 AM
No.105740168
[Report]
Ernie 4.5 in one (1) day
Anonymous
6/29/2025, 5:48:29 AM
No.105740260
[Report]
>>105739631
yes its the summarisation module in silly tavern.
Anonymous
6/29/2025, 5:50:44 AM
No.105740270
[Report]
>>105738361
If it has a little bit of R1 mixed in maybe that explains why I like it more than 3.1. It's not overpowering to the point of being unusable though unlike the "reasoning"-based distills like qwq.
If true it would be funny that the big corps are essentially also doing random mixing and merging to improve their benchmarks
Anonymous
6/29/2025, 5:53:36 AM
No.105740281
[Report]
can you guys stop arguing and add llama.cpp support to hunyuan a13b
Anonymous
6/29/2025, 6:05:47 AM
No.105740361
[Report]
>>105734428
I just want to marry Miku.
Anonymous
6/29/2025, 6:10:00 AM
No.105740385
[Report]
>>105739948
Thanks. When I got time I will play around with it, but if you can I would appreciate some buzzwords that yield the same pixelated art style like your original image.
Anonymous
6/29/2025, 6:11:55 AM
No.105740398
[Report]
Anonymous
6/29/2025, 6:27:35 AM
No.105740477
[Report]
>>105740649
>>105739631
It's literally just a RAG vector db. Wait until next week and I'll share something like kobold that does it.
Anonymous
6/29/2025, 6:28:45 AM
No.105740486
[Report]
>>105740532
>>105737820
>caring about local models in the local models general thread means you're a "local schizo"
wut
Anonymous
6/29/2025, 6:40:27 AM
No.105740532
[Report]
>>105740486
don't reply to bait anon
Anonymous
6/29/2025, 7:05:52 AM
No.105740649
[Report]
>>105740477
Recently LM Studio supports this, but idk how to use it.
Anonymous
6/29/2025, 7:30:09 AM
No.105740762
[Report]
>>105734162
We're in that early adoption liminal space with game applications still. Eventually some bright boy is going to make it work somehow and it will get Minecraft huge, and then there will be nothing but for a long time.
Anonymous
6/29/2025, 7:37:41 AM
No.105740791
[Report]
>>105740779
yeah just like American healthcare privatisation
Anonymous
6/29/2025, 7:47:37 AM
No.105740829
[Report]
>>105740779
>zhang my son
>get better, balanced data
>or
>keep stemmaxxing then apply communism to the experts
Anonymous
6/29/2025, 8:04:12 AM
No.105740899
[Report]
>>105741017
I realized we already plateaued on common sense last year. Now I just want a model that knows as much as possible for its size.
Anonymous
6/29/2025, 8:27:43 AM
No.105741017
[Report]
>>105740899
- Pretrain the models so that the mid and deep layers have better utilization (e.g. with a layer-specific learning rate).
- Introduce instructions / rewritten data / synthetic data early in the pretraining process so that more of the data is retrieavable.
- Relax data filtering; train bad/toxic/low-quality data at the beginning of the pretraining run if you really don't want to emphasize it.
- Stop brainwashing the models with math or caring too much about benchmarks.
- ...?
What are the best local models that have visual recognition for NSFW images?
Chatgpt works well up to a point in terms of NSFW image descriptions. Once details get REALLY explicitly sexual, it will either not describe those details, or blank me.
So I guess I'll turns to local models instead, but I don't know where to start and google is very unhelpful, with people recommending models that flat out don't even have visual recognition.
Anonymous
6/29/2025, 8:45:43 AM
No.105741100
[Report]
>>105741079
Gemma 12b abliterated doesn't have visual recognition. I was recommended that somewhere else but it doesn't work.
Anonymous
6/29/2025, 8:48:10 AM
No.105741116
[Report]
>>105741469
>>105741079
NTA, but although Gemma 3 is surprisingly moderately capable at describing NSFW imagery, it can't describe sexual poses very well. You also need a good prompt for that (which shouldn't normally be a problem for local users, but many here appear to be promptlets).
Anonymous
6/29/2025, 8:50:18 AM
No.105741126
[Report]
>>105741070
gemma triple N
Anonymous
6/29/2025, 8:53:08 AM
No.105741141
[Report]
>>105741107
Not captioning, but literally describing the entire image.
For example, it allows me to turn doujin scenes into novelized scenes, or simply transcribe the panels entire visual detail, including text.
Anonymous
6/29/2025, 9:09:48 AM
No.105741233
[Report]
>>105741203
>that shitter boz
lol
Ik_llama server throws ggml error after prompt processing with ud deepseek v3, but it works fine with r1 and qwen3. any advice?
Anonymous
6/29/2025, 9:23:43 AM
No.105741326
[Report]
>>105738544
The end goal is not what I have right now, it's to make the models actually play against each other and to calculate Elo scores from the win/draw/loss statistics.
I'll still make them choose from the top 10 Stockfish moves but that's primarily because it makes the data analysis from my end easier: I think it will give me a better win/draw/loss separation for a fixed number of turns and I directly can compare language model performance vs. random number generators picking from the top N Stockfish moves.
From a setup for determining the Elo scores I'll get the agreement with Stockfish for free, the main reason I did it first is due to sample size; I can get one datapoint per halfturn instead of one datapoint per game.
Ideally it will turn out that agreement with Stockfish is a good proxy for the Elo scores, one of my goals more generally is to figure out how cheap and fast metrics like differences in perplexity correlate with more expensive metrics like differences in language model benchmark scores.
Anonymous
6/29/2025, 9:24:22 AM
No.105741327
[Report]
>>105740779
This is just drop-out style MoE selection during traning and fixed number of experts at inference
Anonymous
6/29/2025, 9:49:04 AM
No.105741469
[Report]
>>105741116
I think one part of the problem is the lack of real examples. I'm using SillyTavern as an example, it took me a while to find couple of good cards and learn from them.
It's not that obvious at first altough in the end things are relatively simple - it's not rocket science.
Best way to learn is to make your own scenario and tweak it until it's good for (you). And using other cards for reference but only if you know they are good..
>>105741234
>Ik_llama
why do people even care about this piece of damp trash
>>105741653
Last I checked it had 3 times faster prompt processing than base llama.cpp
Anonymous
6/29/2025, 10:25:45 AM
No.105741691
[Report]
>>105737258
>goal is to test reasoning capabilities rather than memorization
This is exactly the kinda shit nvidia+oai disappear ppl for
Anonymous
6/29/2025, 10:29:40 AM
No.105741715
[Report]
>>105734609
>2025: encoder models are dead
>but wait there's a new ernie model
>it's now a decoder llm like the rest, they just kept the name because they're retards
Anonymous
6/29/2025, 10:31:49 AM
No.105741727
[Report]
>>105741107
joycaption beta one has a serious watermark/signature hallucination problem.
Anonymous
6/29/2025, 10:45:07 AM
No.105741792
[Report]
>>105741656
Does it support Mistral?
>>105741234
don't use UD quants. Use ubergarm's
>>105741653
works perfectly for me
Anonymous
6/29/2025, 11:37:35 AM
No.105742110
[Report]
>>105740779
sounds like llamacpp devs incompetence
Anonymous
6/29/2025, 11:47:33 AM
No.105742161
[Report]
>>105742291
gemini 2.5 pro
world's most powerful flagship llm
just found a nonexistent typo in python code with literally three methods in a fresh conversation with 1 message
Anonymous
6/29/2025, 12:04:58 PM
No.105742278
[Report]
>>105740779
Qwen team is retarded, more at 11
Anonymous
6/29/2025, 12:06:46 PM
No.105742291
[Report]
>>105742349
>>105742161
>lowcaser
Learn english first
Anonymous
6/29/2025, 12:19:15 PM
No.105742344
[Report]
>>105741203
>based
>faggot
>based
>based
Anonymous
6/29/2025, 12:19:57 PM
No.105742349
[Report]
>>105742291
>Learn english first
>english
Anonymous
6/29/2025, 12:28:26 PM
No.105742380
[Report]
>>105741957
>works perfectly for me
lucky you. did you compare its performance with gerganov's llama?
>>105741656
>Last I checked it had 3 times faster prompt processing
Unfortunately, I can't confirm this. What I observe instead, is that GPU is barely being used for prompt processing (<10% full load)
I used ubergarm quants, I used unsloth quants
The same underwhelming feeling of pp at 4t/s instead of 12-15 t/s
Anonymous
6/29/2025, 12:35:02 PM
No.105742415
[Report]
>>105742486
>>105737266
didn't he promise to release grok 2 after making grok 3? and now they're on grok 4 lawl
>>105739679
>That's how it works.
KILL YOURSELF YOU LYING FAGGOT
Anonymous
6/29/2025, 12:39:44 PM
No.105742446
[Report]
>>105743611
>>105740779
>this is extremely difficult to reimplement in llama.cpp
sounds like skill issue
Anonymous
6/29/2025, 12:41:10 PM
No.105742454
[Report]
>>105742480
>>105742419
He's not lying, but don't expect him to give you details. It's a lucrative skill to be able to properly finetune a model
>>105742454
>It's a lucrative skill to be able to properly finetune a model
KILL YOURSELF YOU LYING FAGGOT
Anonymous
6/29/2025, 12:46:34 PM
No.105742486
[Report]
>>105742511
Which software between KoboldAI and oobabooga am I choosing for my local models?
Anonymous
6/29/2025, 12:48:33 PM
No.105742499
[Report]
>>105742480
Some AI adult chatbot you can see everywhere offered me 10K$/mo to do that. Keep coping
Anonymous
6/29/2025, 12:49:41 PM
No.105742506
[Report]
>>105742495
my guess is lmstudio. how many points do i get?
Anonymous
6/29/2025, 12:50:08 PM
No.105742508
[Report]
>>105742495
obama just werks
Anonymous
6/29/2025, 12:50:17 PM
No.105742511
[Report]
>>105742486
>Elon in 2030, after releasing Grok 7 in API
>Guyzzz Grok 3 is not stable yet! Plz be patient!
Anonymous
6/29/2025, 12:50:47 PM
No.105742513
[Report]
>>105741653
in my CPU-only scenario, it had both better pp and tg, especially at higher contexts:
>>105694000.
But my old 1060 6GB didn't work for prompt processing on ubergarms quant only, maybe they've written some CUDA code assuming a higher compute capability. llama.cpp seems more reliable and less buggy for sure.
>>105742480
He's right, but it's only lucrative because boomers with too much money to waste have no clue of the limitations and because they think you need seriouz skillz to upload an ERP finetune on HuggingFace when on a surface level it's mostly a matter of data (often manual labor), compute and some hoarded knowledge. Put these finetroon retards on a real job where they'll have to design a production-ready system and they'll fold in no time due to fundamental skill issues.
Anonymous
6/29/2025, 1:11:50 PM
No.105742625
[Report]
>>105742885
>>105741957
When I try to load his quant, which is slightly larger than my ram, it begins paging to my c drive. i didn't add --no-mmap. It's not supposed to do that, is it?
Anonymous
6/29/2025, 1:23:37 PM
No.105742687
[Report]
>>105742495
If you can, you should give llama.cpp a shot.
I had significantly more tps than on ooba and slightly lower vram usage.
It was some time ago, so I don't know if the situation is better now, but llama.cpp is pretty awesome, if you aren't afraid of the command line.
Anonymous
6/29/2025, 1:29:10 PM
No.105742721
[Report]
>>105741203
what the fuck
Anonymous
6/29/2025, 1:40:35 PM
No.105742778
[Report]
>>105742877
>>105742576
When most of your value as a finetuner is in some practice with pre-made open-source tools and in limited amounts of data you've wasted months or even more than a year cleaning (or worse, made/paid people to do it), you don't really have much to offer once you allow others to peek behind the curtains.
Anonymous
6/29/2025, 1:45:00 PM
No.105742803
[Report]
>>105739679
That is not how it works and if people knew that nobody would pay money for your patreon scammer.
Anonymous
6/29/2025, 1:47:46 PM
No.105742820
[Report]
>>105737649
Still would wager it is more than decent in sequential.
Anonymous
6/29/2025, 1:51:04 PM
No.105742841
[Report]
>>105737649
You can sell the excess or share with your friends.
Anonymous
6/29/2025, 1:56:07 PM
No.105742877
[Report]
>>105742778
You underestimate how dumb is your average AI grifter. Everyone in this thread is practically a genius in this field to even know what minP does to the token distribution (it was one of the hiring questions, btw). Let's not forget the arcane knowledge that you can't find outside of this place and will end up in a paper a few years later.
Anonymous
6/29/2025, 1:57:49 PM
No.105742885
[Report]
>>105742625
Ok. the problem was -rtr which disables mmap
Anonymous
6/29/2025, 2:16:03 PM
No.105742986
[Report]
>>105742993
molmo.gguf when?
Anonymous
6/29/2025, 2:16:53 PM
No.105742993
[Report]
>>105743045
>>105742986
Be the change you want to see
Anonymous
6/29/2025, 2:28:18 PM
No.105743045
[Report]
>>105743128
>>105742993
that sounds like work
Anonymous
6/29/2025, 2:32:15 PM
No.105743065
[Report]
>>105743128
>>105737266
>Asian larping with Europeancore
Is this how they feel when some white fattie posts samurai and sun tzu quotes?
Anonymous
6/29/2025, 2:50:08 PM
No.105743128
[Report]
>>105743045
fulfilling work
>>105743065
asians don't feel feelings
Anonymous
6/29/2025, 2:59:54 PM
No.105743172
[Report]
>>105734503
I think you're posting on the wrong website.
Anonymous
6/29/2025, 3:04:34 PM
No.105743199
[Report]
>>105743224
>>105734503
It reads like a LLM shitpost.
>>105734603
>false equivalence, the post
Anonymous
6/29/2025, 3:05:20 PM
No.105743204
[Report]
>>105734503
>hentai
Is it not censored?
Anonymous
6/29/2025, 3:08:14 PM
No.105743224
[Report]
>>105743298
>>105743199
I feel like somebody must have hand-curated all the most cringe posts on locallama and then finetuned a model on them just to create an AI redditor to ruin what's left of /lmg/.
Anonymous
6/29/2025, 3:12:16 PM
No.105743244
[Report]
what are the popular models for erp for a 3090 with 32 gb ram nowadays?
there used to be a list in the op
Hi all, Drummer here...
6/29/2025, 3:16:05 PM
No.105743264
[Report]
>>105743283
>>105743298
>>105742419
I really hope you find peace at some point, newfriend. It's concerning how unhinged and baseless you're acting right now.
Even if you do clown out of amusement, your online behavior will ooze into your psyche at some point and you will lose yourself and regret it. Control your impulses and redirect your hate to bigger things. Your future self will thank you.
>>105742576
Growth only happens when you go out of your depth but soldier on. That's why jobs are framed as 'opportunities', especially when you're young. Take it from someone who has had a real job for nearly 10 years.
You guys might disagree with me, but I am a believer of Karpathy's claim that AI is software 2.0. I see finetuning as a great way for a software engineer to brush up on this domain and prepare for the future.
Anonymous
6/29/2025, 3:18:43 PM
No.105743283
[Report]
>>105743304
>>105743264
>zoomer
>redditor
kill yourself and go back in that order
Anonymous
6/29/2025, 3:20:43 PM
No.105743298
[Report]
>>105743384
>>105743224
stop! don't give him ideas
>>105743264
3.2 finetune when?
what model would you recommend to a 12gb vramlet with 48gb ram
Anonymous
6/29/2025, 3:21:57 PM
No.105743304
[Report]
>>105743329
>>105743283
Shut the fuck up retard, your contribution in this thread is 0. Go back to your containment thread in /wait/ where you can shitpost all you want.
>>105743304
your "contributions" are less than zero drummer
Anonymous
6/29/2025, 3:33:18 PM
No.105743382
[Report]
>>105741203
Everything you need to know in one image right there
Hi all, Drummer here...
6/29/2025, 3:33:24 PM
No.105743384
[Report]
>>105743440
>>105743298
You can try my Cydonia test tunes.
https://huggingface.co/BeaverAI/Cydonia-24B-v4g-GGUF is the top candidate. Reduced repetition, less slop, unaligned, overall good responses from the feedback so far.
https://huggingface.co/BeaverAI/Cydonia-24B-v4d-GGUF If v4g feels off for you, v4d is closer to OG 3.2 but with less positivity and better roleplayability.
Cydonia v3.1 and v3k both have Magistral weights. Former being a merge of it, and the latter being a tune on top of it. Magistral is surprisingly unaligned on its own, but has the Nemotron Super quirks which were ironed out with Valkyrie.
>>105743329
I am making a genuine effort to tag (not trip) myself in all my posts so you wouldn't have to accuse everyone of being me.
Anonymous
6/29/2025, 3:41:02 PM
No.105743440
[Report]
>>105743488
>>105743384
very nice, downloading both
hopefully V3 tekken formatting works
Hi all, Drummer here...
6/29/2025, 3:47:01 PM
No.105743488
[Report]
>>105743440
They are all tuned with Mistral's new V7 Tekken template ([SYSTEM_PROMPT]) and I haven't checked how it'll do without those control tokens present.
>>105743329
I'm not him. Don't worry about my contributions
Anonymous
6/29/2025, 3:54:35 PM
No.105743545
[Report]
Who the fuck uses GGUF for a tiny 24b model?
Anonymous
6/29/2025, 3:57:10 PM
No.105743567
[Report]
Anonymous
6/29/2025, 4:02:53 PM
No.105743611
[Report]
>>105743647
>>105742446
>previously stateless next-token-logits calculation now has to account for previous selections and what experts were used
I can very easily imagine why this would be absurdly ass to implement tbqh.
>>105743611
Everybody else working on top of pytorch doesn't seem to have a problem. Maybe llama.cpp should have focused less on marginal speed increases and supporting 30 binaries and more on building a core architecture that was actually extensible.
Anonymous
6/29/2025, 4:11:38 PM
No.105743677
[Report]
>>105743647
exllamav2 moved to an extensible core architecture and fucking died
Anonymous
6/29/2025, 4:11:53 PM
No.105743681
[Report]
>>105743647
Like you can manage a proper codebase with every company releasing their shitty models with their own architecture gimmick lmao
Anonymous
6/29/2025, 4:15:03 PM
No.105743702
[Report]
>>105743647
Or you could just build the one binary you want with --target. You don't build yourself? Oh...
Anonymous
6/29/2025, 4:20:50 PM
No.105743745
[Report]
>>105743647
>adding state to something previously stateless
No, no, this is actually harder to do if you were coding correctly and properly designing your interfaces, and it's easier if you're slopping out procedural code.
Anonymous
6/29/2025, 4:22:00 PM
No.105743757
[Report]
>>105743774
>>105743529
>application janny
>3 accepted 257 rejected
most homosexual poster in the thread award
Anonymous
6/29/2025, 4:23:35 PM
No.105743774
[Report]
>>105743757
Yes, I'm suffering from success
Anonymous
6/29/2025, 4:42:27 PM
No.105743966
[Report]
Anonymous
6/29/2025, 5:45:30 PM
No.105744559
[Report]
>>105741203
>Lieutenant Colonel
Demotion
Anonymous
6/29/2025, 6:25:21 PM
No.105744859
[Report]
Any model that can convert a song in wav into a midi track?