/lmg/ - Local Models General
Anonymous
9/8/2025, 12:01:22 AM
No.106516369
[Report]
►Recent Highlights from the Previous Thread:
>>106512307
--Open vs closed LLM progress and dataset efficiency debates:
>106512347 >106512375 >106512423 >106512595 >106512445 >106512517 >106512610 >106512693 >106513204 >106513240 >106513275 >106513359 >106513448 >106513451 >106513465 >106513591 >106513485 >106513499 >106513545 >106513567 >106513584 >106513595 >106513736 >106514154 >106513773 >106513803 >106513823 >106513864 >106513969 >106514038 >106514056 >106514094 >106514111 >106514143 >106514258 >106514291 >106514299 >106514449 >106514475 >106514486 >106514504 >106514556 >106514592 >106514608 >106514671 >106514710 >106514725 >106514740 >106514750 >106514765 >106514607 >106514622 >106514694 >106514888 >106514917 >106514932 >106514961 >106514979 >106515001 >106515057 >106514968 >106515015 >106515061 >106515105 >106515119 >106515139 >106515181
--ERP model finetuning with AO3/Wattpad datasets:
>106512933 >106513094 >106513181 >106513210 >106513219 >106513256 >106513670 >106513686 >106513740 >106514579 >106514614 >106514787 >106513222 >106513281 >106513313 >106513321 >106513397 >106514052
--VibeVoice TTS voice cloning and conversational capabilities:
>106515071 >106515193 >106515199 >106515236 >106515623 >106515246 >106515275
--Dataset specialization vs diversity tradeoffs in model training efficiency:
>106514377 >106514388 >106514457 >106514498
--Memory limitations in transformers vs. potential SSM improvements:
>106513859
--VibeVoice ComfyUI integration issues and VRAM requirements:
>106512932 >106513000 >106513126 >106513205 >106513235 >106513319 >106513338
--Troubleshooting erratic Harmony 20B behavior in tavern interface:
>106513566 >106513708 >106513756 >106513772
--Improving VibeVoice long audio generation quality via CLI adjustments:
>106514051 >106514086 >106514195 >106514437
--Miku (free space):
>106514325 >106514549 >106515574
►Recent Highlight Posts from the Previous Thread:
>>106512310
Why?:
>>102478518
Enable Links:
https://rentry.org/lmg-recap-script
Anonymous
9/8/2025, 12:03:15 AM
No.106516385
[Report]
Anonymous
9/8/2025, 12:05:32 AM
No.106516402
[Report]
>>106516520
All this training data debate is retarded.
We just need to create a dataset. It will take 3 lifetimes. Think cathedral.
We need a blueprint and a chunk of digital "land" and we can get going. Craftsmen will show up if the plan is ambitious enough to move the spirit of men.
>>106516395
Whatever happened with higgs, anyway? I never got around to looking into it. What made vibevoice blow up comparitively? Other than everyone wanting it because it was taken away from them.
Anonymous
9/8/2025, 12:08:57 AM
No.106516423
[Report]
>>106516389
just like with vibe-coding in general, we don't need it to one-shot a whole project, we can just do subroutines. Those can be as compact as 2 instructions.
Anonymous
9/8/2025, 12:09:22 AM
No.106516426
[Report]
>>106516409
It's kinda decent and voice cloning just works™ by dragging a sample audio file in a folder.
Anonymous
9/8/2025, 12:10:05 AM
No.106516432
[Report]
>>106516455
>>106516395
Keep it all here retard, the hype will die down after a couple weeks and /gee/ doesn't need another fucking ai gen thread to clog it up
Anonymous
9/8/2025, 12:13:08 AM
No.106516450
[Report]
>>106516625
Anonymous
9/8/2025, 12:13:16 AM
No.106516452
[Report]
>>106516147
>gets pretty rough even with that when you try to do a 40 minute script
What is your qualified opinion on GFG?
Anonymous
9/8/2025, 12:14:03 AM
No.106516455
[Report]
>>106516432
I was not suggesting a partition, merely commenting on the current state of this thread
Who should I sample for the best mesugaki voice?
Anonymous
9/8/2025, 12:20:45 AM
No.106516514
[Report]
>>106516499
>anon added label: Important
>>106516402
if you aren't worried about compute cost the available datasets are already more then enough. just hit a 70b with common crawl and then use it to bootstrap an instruction dataset and then use that to refine it even further. the entire debate is because people are trying to do it with minimal data and minimal compute it will never really work.
Interesting, I wonder if the problem with the comfyui implementation lies in the step count. higher than 10 it becomes more and more inconsistent. Now tested between wildminder and diodiogod's TTS suite, the TTS suite is far more consistent and, while still has similar issues, keeping step count below 20 seems to have some form of stability.
this test, at 10 steps, with a very background-noisy sample, honestly blows away everything i was just doing at 20-30 steps before.
it's always something with this shit isn't it? lmg and ldg anti-comfy schizo vindicated!
https://voca.ro/1aYkwUddVRDk
>>106516451
>https://voca.ro/1ogB0LHKA0bU
please post the script and the ref audio
For research purposes, it is understood
Anonymous
9/8/2025, 12:27:49 AM
No.106516574
[Report]
>>106516705
Anonymous
9/8/2025, 12:27:54 AM
No.106516577
[Report]
>>106516618
Anonymous
9/8/2025, 12:29:22 AM
No.106516585
[Report]
>>106516499
Your bum mother.
Anonymous
9/8/2025, 12:32:53 AM
No.106516618
[Report]
Anonymous
9/8/2025, 12:33:24 AM
No.106516625
[Report]
>>106516450
not yet, still being digested
Anonymous
9/8/2025, 12:33:28 AM
No.106516626
[Report]
>>106519246
>>106516561
You can have the script, but you gotta go get your own audio.
https://pastebin.com/wr3ASHkN
Anonymous
9/8/2025, 12:33:47 AM
No.106516631
[Report]
>>106516716
>>106516520
For me, it's more about determining the minimum amount of data and the composition required to train an LLM from scratch to exhibit basic intelligence and common sense rather than creating a model useful in practice. Random web data isn't useful for that.
Anonymous
9/8/2025, 12:34:46 AM
No.106516639
[Report]
Anonymous
9/8/2025, 12:39:39 AM
No.106516675
[Report]
>>106516732
What is the max file duration VibeVoice accepts?
Anonymous
9/8/2025, 12:42:22 AM
No.106516699
[Report]
>>106516561
ms safety team worst nightmare (no it's not actual agi, it's porn)
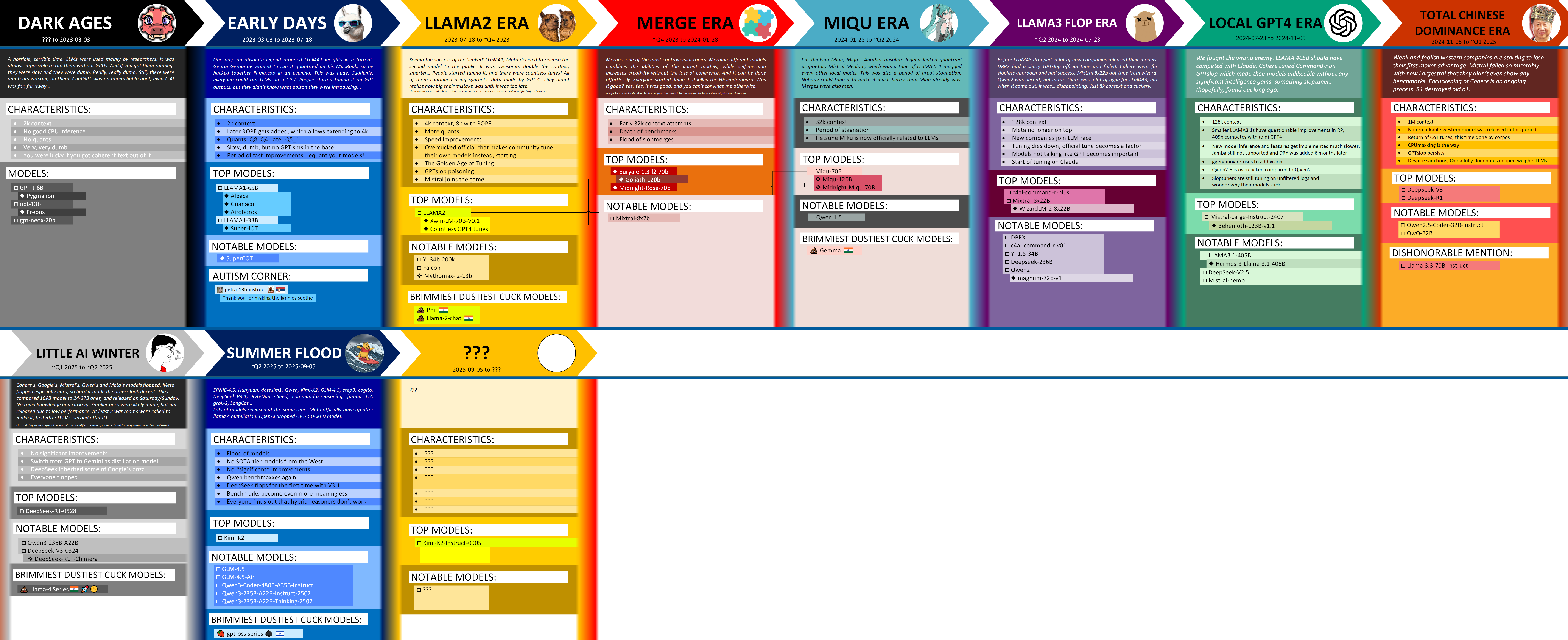
Summer flood is over, I guess. Expectations for new era? Largestral 3? Llama 4.5? Will Gemma 4 be a lot less cucked and finally make to "notable"? Will DS make a comeback with R2 or have they hit the wall like everybody else? Will Kimi get a second era of dominance? Will Qwen finally go from notable to top? Will incremental updates continue or will we get a jump like with R1?
Here are the counts of tops so far:
- Meta: 3 eras
- Mistral: 3 eras
- DS: 2 eras
- Cohere: 1 era
- Kimi: 1 era
Anonymous
9/8/2025, 12:44:16 AM
No.106516716
[Report]
>>106516994
>>106516631
how do you define that basic intelligence and common sense? have you tried training a model on TinyStories?
>>106516520
compute will naturally get better and cheaper.
The kind of data curation that we're interested in will not happen unless we're proactive and deliberate about it (and definitely won't happen in the open, even if a CAI type org does it)
Anonymous
9/8/2025, 12:44:39 AM
No.106516719
[Report]
>>106516753
>>106516451
Large or 1.5?
Anonymous
9/8/2025, 12:45:41 AM
No.106516732
[Report]
>>106516675
just chunk the files at sentence, paragraph or other grammatical markers and run them through in batches
Anonymous
9/8/2025, 12:46:11 AM
No.106516737
[Report]
>>106516707
Google can't stop cucking the hardest, it's in their DNA to be ultra gay
Anonymous
9/8/2025, 12:47:26 AM
No.106516751
[Report]
>>106516821
>>106516707
Can you call this period the Drummer's Slop Spam era?
Anonymous
9/8/2025, 12:47:32 AM
No.106516753
[Report]
I just bought a A100 80gb pcie card off ebay. Had to dip into my emergency fund but I hope this is worth the pay off to run bigger models purely on the gpu
Anonymous
9/8/2025, 12:48:29 AM
No.106516764
[Report]
>>106516846
>>106516718
if you think that compute is going to get cheaper and better then the discussion should be on training classifier models to generate the dataset. I had some luck training a few of my own but the compute cost to run my dataset through the classification network didn't pan out.
Anonymous
9/8/2025, 12:52:42 AM
No.106516806
[Report]
>>106516823
>>106516529
Shit, I think you might be right. I was getting annoyed with it and starting to look into setting up the gradio one, but knocking it down to 10 steps from the 30-50 I'd been using actually seems to have improved the quality a lot.
I'm gonna need to keep futzing with it to make sure I'm not just imagining the changes.
Anonymous
9/8/2025, 12:53:17 AM
No.106516811
[Report]
Even Gemini knows:
"Google's original mission statement, which remains its official mission today, is: "To organize the world's information and make it universally accessible and useful".
Based on its business practices, revenue model, and ethical criticisms, Google's operational mission is distinct from its stated mission. While the official mission represents its foundational purpose, the company's behavior reflects an overarching, inferred mission: to own and monetize the pathways to the world's information and digital activity through dominance in online advertising, search, and data collection."
Anonymous
9/8/2025, 12:54:49 AM
No.106516821
[Report]
>>106516751
"Drummer's Slop Spam era?" If he pays me for it, I will.
Anonymous
9/8/2025, 12:55:03 AM
No.106516823
[Report]
>>106516806
bark up their tree about it for me will ya? it's 100% something along those lines. I'm genning an entire audiobook at 10 steps and its far far far more stable, compared to earlier where most samples were speaking in hieroglyphics.
Anonymous
9/8/2025, 12:55:18 AM
No.106516825
[Report]
>>106516817
edgelord model take 2154
Anonymous
9/8/2025, 12:55:40 AM
No.106516828
[Report]
>>106516837
>>106516757
This quite possibly the stupidest thing I've read all week. 80 GB is nothing in the face of the MoE models that are the only ones worth running.
Anonymous
9/8/2025, 12:56:39 AM
No.106516837
[Report]
>>106516838
>>106516828
Are you trying to push me to suicide right now?
Anonymous
9/8/2025, 12:57:21 AM
No.106516838
[Report]
>>106516837
Do a flip, faggot.
Anonymous
9/8/2025, 12:57:25 AM
No.106516840
[Report]
>>106516707
>retarded chart again
I'd redo it myself, but I'll let you fish for attention a while longer
Anonymous
9/8/2025, 12:57:40 AM
No.106516842
[Report]
>>106516855
>>106516757
>bought a A100 80gb pcie card off ebay
good
>dip into my emergency fund
it's a hobby, don't ruin yourself over it, use money you can waste
Anonymous
9/8/2025, 12:58:00 AM
No.106516846
[Report]
>>106516881
>>106516764
so, sorting piles into smaller piles?
do you think a human still needs to do the final selection of what makes it in?
Anonymous
9/8/2025, 12:58:19 AM
No.106516849
[Report]
>>106516718
>compute will naturally get better and cheaper.
I have doubts.
Anonymous
9/8/2025, 12:58:37 AM
No.106516851
[Report]
>>106516757
I knew some of you were dumb, but...
Anonymous
9/8/2025, 12:58:43 AM
No.106516854
[Report]
Is there an extension or something for SillyTavern that can automatically record memories for a character?
Anonymous
9/8/2025, 12:58:49 AM
No.106516855
[Report]
>>106516842
I mean, as long as an emergency doesn't happen before he can replenish it, he should be fine.
Anonymous
9/8/2025, 12:59:40 AM
No.106516861
[Report]
>>106516897
>>106516757
>A100 80gb pcie card off ebay.
Did you get a good deal at least? I'd pay $2k for one, tops, personally. There's a lot of 3d-printing shroud and fan bullshit that goes along with those DC cards.
Anonymous
9/8/2025, 1:00:12 AM
No.106516867
[Report]
How much money is an "emergency fund"?
It's burger hours it has to be at least 100k given the absolute state of healthcare over there, right?
Anonymous
9/8/2025, 1:02:01 AM
No.106516878
[Report]
>>106516926
>>106516875
As a rule, 6 months of living expeses.
Anonymous
9/8/2025, 1:02:05 AM
No.106516879
[Report]
>>106516889
>>106516757
Should have cpu maxxed with 12 channel ddr5 plus a rtx 6000.
Anonymous
9/8/2025, 1:02:15 AM
No.106516881
[Report]
>>106516891
>>106516846
if you want your dataset to actually be capable of pretraining a foundation model you will have to be happy with doing a few spot checks here and there. if you want to make a really high quality fine tuning dataset then you can review every sample but it gets pretty out of hand quickly.
Anonymous
9/8/2025, 1:03:49 AM
No.106516889
[Report]
>>106516919
>>106516879
He wanted to run models purely on GPU. With that thing, he can run Air Q4 probably at like 50 t/s.
Anonymous
9/8/2025, 1:04:24 AM
No.106516891
[Report]
>>106516976
>>106516881
What about with a 300 year time horizon?
>>106516861
I paid a bit over $10000 once taxes are included. I didn't see any for under that really.
Anonymous
9/8/2025, 1:06:51 AM
No.106516910
[Report]
Anonymous
9/8/2025, 1:07:00 AM
No.106516915
[Report]
>>106516897
I don't know how taxes worth with the listed prices in burgerland but that sounds like the price of a brand new rtx 6000 with more memory, similar bandwidth and more compute.
Anonymous
9/8/2025, 1:07:10 AM
No.106516916
[Report]
>>106516897
>Imagine the amount of token you could waste on OR for $10K
Anonymous
9/8/2025, 1:07:17 AM
No.106516918
[Report]
>>106516897
do people really
Anonymous
9/8/2025, 1:07:24 AM
No.106516919
[Report]
>>106516889
Then just a single rtx 6000 would have been cheaper more vram and new.
Anonymous
9/8/2025, 1:07:37 AM
No.106516921
[Report]
Anonymous
9/8/2025, 1:08:01 AM
No.106516926
[Report]
>>106516878
Yeah, regardless of the country, usually 5 to 12 months of living expenses depending on the job and how easy it is to replenish it.
Anonymous
9/8/2025, 1:08:07 AM
No.106516928
[Report]
>>106516757
that's a big waste of money
extra ram is better than extra vram now
>>106516897
Depending on your jurisdiction you're still in the cooloff period, try to cancel.
Search "Blackwell Pro 6000 96GB" and save yourself massive headaches and also a GPU that won't lose CUDA support nearly as quickly.
>>106516897
ok this has to be a joke, a 6000 pro blackwell is literally this price, brand new
Anonymous
9/8/2025, 1:10:01 AM
No.106516946
[Report]
>>106516958
>>106516934
He could save himself even more headaches by getting a 5090 and 128GB of ram.
Anonymous
9/8/2025, 1:11:03 AM
No.106516955
[Report]
>>106517017
>>106516757
You still have 30 days to return lil bro.
Anonymous
9/8/2025, 1:11:20 AM
No.106516958
[Report]
>>106516946
Nobody wants to run models at 1 token per second. Stop trying to convince others to waste money on a novelty paperweight just because you did.
>>106516875
>given the absolute state of healthcare over there
You guys do realize we've had health insurance since forever and since Obama you're legally required to get it or face fines. Even if you have to be on obamacare plans the worst deductible is like $8000 on the worst tier.
Anonymous
9/8/2025, 1:12:01 AM
No.106516972
[Report]
the most valuable use of time is figuring out our own way to cheaply manufacture hardware at home 3d printing but for chips nvidias and others markups if you actuall look at how much all the base materials and electricity would cost to make/acquire is in the tens of thousands of times if not millions in some cases the further added benefit would be no glowware or backdoors
also we can also harass cudadev to write all the support
Anonymous
9/8/2025, 1:12:13 AM
No.106516976
[Report]
>>106516891
impossible, the rate of revolution is too high right now. it is likely to stay too high until the collapse of the system as a whole.
Anonymous
9/8/2025, 1:12:14 AM
No.106516977
[Report]
>>106516897
You're trolling.
Anonymous
9/8/2025, 1:13:09 AM
No.106516987
[Report]
>>106516964
It's a lost cause, youtube/tiktok made it look like no one in the US had or can afford healthcare and hospitals are empty or something.
The VibeVoice Latent Space demons have sent a message
https://vocaroo.com/1edmqG0nl8gP
Anonymous
9/8/2025, 1:13:23 AM
No.106516994
[Report]
>>106517256
>>106516716
Not TinyStories, but I've trained a few tiny models on small amounts of other data and I have a rough idea of what could work and what doesn't.
For me the model should know how to engage in simple conversations, know what most common English words mean and how to use them, and show an understanding of cause and effect for mundane actions and events. Coding, math, trivia, reasoning can come after that.
Anonymous
9/8/2025, 1:13:47 AM
No.106516998
[Report]
>>106517018
its always the patrick star IQ motherfuckers with the money to just casually drop like that
or equally the types to walk into a thread like this and lie about doing such a thing, either way funny
Anonymous
9/8/2025, 1:14:10 AM
No.106517000
[Report]
Anonymous
9/8/2025, 1:14:50 AM
No.106517005
[Report]
>>106516990
where'd you get this recording of me trying to get this gay model working in comfyui?
Anonymous
9/8/2025, 1:15:25 AM
No.106517010
[Report]
>>106517036
>>106516937
>>106516934
>>106516955
Okay I admit I didn't realize the newer arch cards were similarly priced. I fucked up. I'm going to try and cancel my order before I do anything else. I am fucking sweating buckets right now. Just to be clear the "Blackwell Pro 6000 96GB" you're referencing is the same as the NVIDIA RTX PRO 6000 Blakcwell with 96GB? Once the cancellation goes through i'll order the blackwell card.
Anonymous
9/8/2025, 1:16:05 AM
No.106517018
[Report]
>>106516998
no I confirm, it's already the most retarded guys with most money to waste
Anonymous
9/8/2025, 1:18:08 AM
No.106517036
[Report]
Anonymous
9/8/2025, 1:18:38 AM
No.106517040
[Report]
>>106517017
https://www.pny.com/nvidia-rtx-pro-6000-blackwell-max-q
There are a couple of versions with some minor tradeoffs.
Good luck, I wish I could drop that much on a GPU
Anonymous
9/8/2025, 1:18:43 AM
No.106517041
[Report]
>>106517057
>>106516964
>the worst deductible is like $8000 on the worst tier
I pay 100€ per year for the upgraded healthcare plan and a surgery and two weeks in hospital cost me 0€.
Anonymous
9/8/2025, 1:20:27 AM
No.106517050
[Report]
>>106516897
You really should've gotten an RTX Pro 6000 then.
Anonymous
9/8/2025, 1:21:24 AM
No.106517057
[Report]
>>106517041
Bro, your hospital is filled with clueless immigrants. Your healthcare is pratically free because it's worthless
Anonymous
9/8/2025, 1:23:08 AM
No.106517073
[Report]
So is Meta really done with AI at this point?
Anonymous
9/8/2025, 1:24:04 AM
No.106517085
[Report]
Anonymous
9/8/2025, 1:24:10 AM
No.106517086
[Report]
>>106517082
meta is going on the rag
Anonymous
9/8/2025, 1:28:09 AM
No.106517111
[Report]
>>106517166
Do any of you guys use both LLMs and cloud providers? I've been experimenting with mistral-small, devstral and qwen3-coder for awhile now locally but also making use of gemini-cli and lumo now (free versions of both). Outside of when I need to ask very "personal" questions or such I find myself wondering if llm is even worth it anymore.
Anonymous
9/8/2025, 1:29:55 AM
No.106517122
[Report]
>>106516964
I was under impression that obamacare is what made US healthcare so expensive to begin with.
>>106517082
They could make a comeback at some point since they have a lot of GPUs but as right now they are done.
>>106517082
Llama 4.X rumored.
Meta is racing the clock to launch its newest Llama AI model this year
https://www.businessinsider.com/meta-superintelligence-lab-llama-4-new-model-launch-year-end-2025-8
>Meta aims to release its next AI model, Llama 4.X, by year-end, according to two sources.
>The release of Llama 4 models in April faced criticism for underperformance, some developers said.
>A team within Meta Superintelligence Labs is now trying to fix bugs within Llama 4, sources say.
[...]
Anonymous
9/8/2025, 1:34:00 AM
No.106517149
[Report]
>>106517205
>>106517135
How tf did zuck let himself get this bamboozled? Its honestly one of the saddest arcs i've seen. Almost makes me feel bad for the guy
Anonymous
9/8/2025, 1:35:04 AM
No.106517159
[Report]
>>106517145
>rushing out another slop of llama 4
it's over
Anonymous
9/8/2025, 1:35:31 AM
No.106517163
[Report]
>>106519899
>>106517145
>fix bugs
Odd way to say "retrain with even more slop"
Anonymous
9/8/2025, 1:35:51 AM
No.106517166
[Report]
>>106517111
You're confused about terminology, cloud providers also run LLMs.
I don't want touch cloudshit with a ten-feet pole because I know inevitable enshitification rug pull will hit at exact moment I'll start getting used to and rely on it for daily life.
Friends don't let friends use someone else's computers.
>>106517157
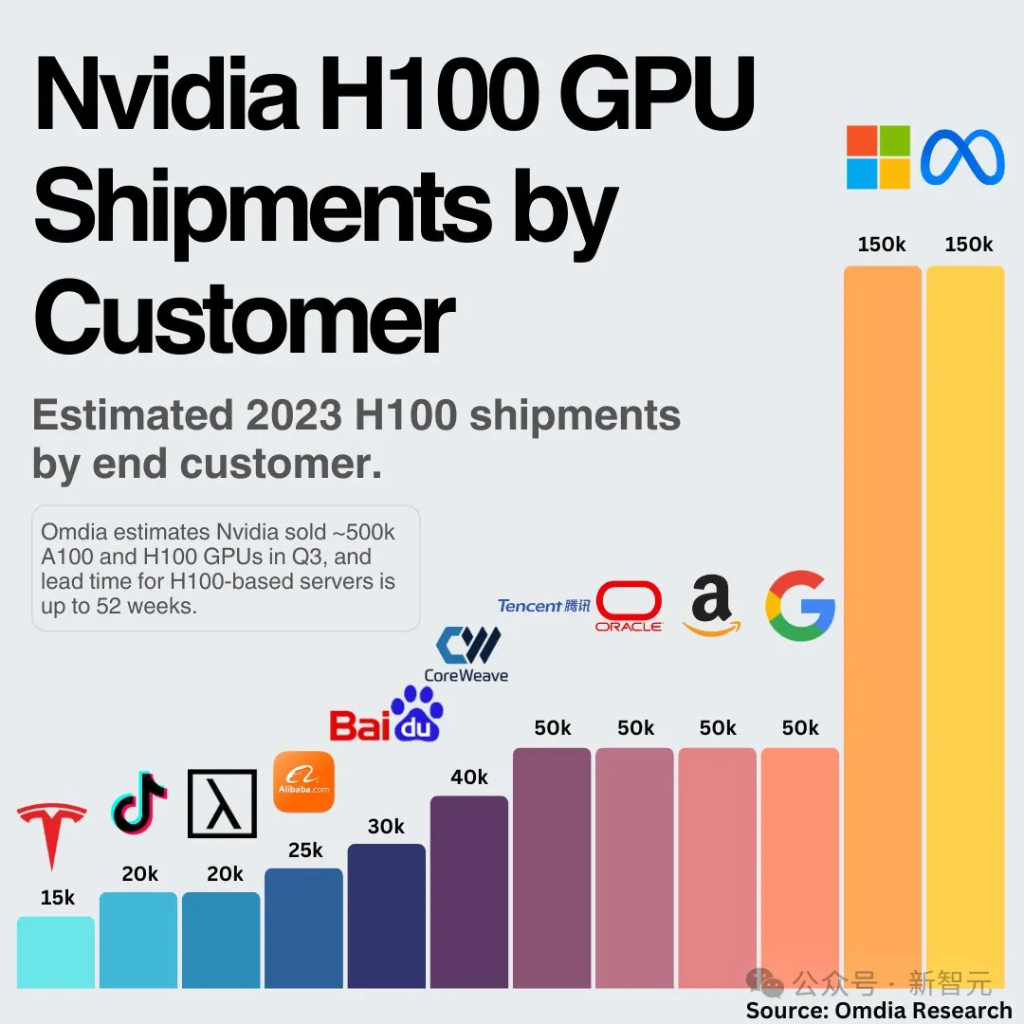
How does Microshaft have 150k H100s and yet not a single model to their name and rely on OpenAI and Claude for Copilot?
Anonymous
9/8/2025, 1:38:39 AM
No.106517189
[Report]
>>106517172
WizardLM wasn't safe enough
how many t/s should i be getting on a 5_k_xl quant of GLM 4.5 full with 2 3090s and 128GB of RAM? what setting should i be using?
Anonymous
9/8/2025, 1:39:55 AM
No.106517198
[Report]
>>106517135
>>106517157
Having the most GPUs does fuck all when you only use 5% of them.
>>106517172
Microsoft focuses on Azure as a service. They're more than happy to let others develop models and make them available through their service.
>>106517172
Microsoft are useless
If you didn't think that before, you definitely should after seeing that chart
Organizationally they are pure lazy, rentseeking trash
Anonymous
9/8/2025, 1:40:42 AM
No.106517205
[Report]
>>106517252
>>106517149
1. He listened to safetyists instead going full Musk 2.0 in changing political climate
2. Meta kept repeating the same scheme while all other companies were innovating
3. 5% GPU utilization is no joke. 600k H100s work with efficiency of 30k
4. He put a scamming jeet in charge of his AI team(llama 4 to the moon saars!)
5. He put an actual grifter who was selling gptslop as human data(Wang) in charge of his AI team
Anonymous
9/8/2025, 1:40:43 AM
No.106517206
[Report]
>>106517214
>>106517197
1 toks/s if your lucky
Anonymous
9/8/2025, 1:41:58 AM
No.106517212
[Report]
>>106517172
Look at the state of windows
Anonymous
9/8/2025, 1:42:06 AM
No.106517214
[Report]
>>106517206
really? because i have been getting around 3t/s with some mostly random settings on oobabooga.
Anonymous
9/8/2025, 1:44:13 AM
No.106517226
[Report]
>>106517228
>>106517197
Depends if you're on Windows or Linux. I'd guess 2-4t/s and 4-6t/s for the former and latter with the correct set-up.
Anonymous
9/8/2025, 1:44:39 AM
No.106517228
[Report]
>>106517242
>>106517226
i am on linux.
Anonymous
9/8/2025, 1:45:46 AM
No.106517236
[Report]
>>106517204
that's what you get for filling your company with jeets
Anonymous
9/8/2025, 1:46:44 AM
No.106517242
[Report]
>>106517303
>>106517228
Make sure to fiddle with -ot to put all layers on one GPU and fit as many MoE experts on both GPUs, it'll take some trial and error.
Why do none of you guys finetune your own models for 4chan usage?
>>106517205
I think the political climate favors safetyists. There's a moral panic about models telling people to kill themselves or pesos using it to make "CSAM"
Anonymous
9/8/2025, 1:48:08 AM
No.106517255
[Report]
>>106517262
>>106517250
What usecase?
Anonymous
9/8/2025, 1:48:14 AM
No.106517256
[Report]
>>106520214
>>106516994
>For me the model should know how to engage in simple conversations, know what most common English words mean and how to use them, and show an understanding of cause and effect for mundane actions and events.
what size model are you targeting and how much data do you feel is necessary?
Anonymous
9/8/2025, 1:48:51 AM
No.106517262
[Report]
>>106517255
automated reply bots to keep me company at night
Anonymous
9/8/2025, 1:49:11 AM
No.106517263
[Report]
>>106517276
>>106517204
>Microsoft are useless
Anon, they just 'released' top tier TTS model.
Historically MS always had good R&D but completely knee-capped by management.
My favorite video on this subject:
https://youtu.be/vOvQCPLkPt4?t=158
>13 years ago
>casually drop a 1ms latency (1000Hz) touch display prototype
>absolutely nothing comes out of it
Anonymous
9/8/2025, 1:50:20 AM
No.106517270
[Report]
>>106517279
>>106517250
just go get gpt4chan tune
Anonymous
9/8/2025, 1:51:00 AM
No.106517276
[Report]
>>106518083
>>106517263
I said "organizationally" on purpose.
Good humans buried by bullshit
Anonymous
9/8/2025, 1:51:22 AM
No.106517279
[Report]
>>106517270
>trained on /pol/ exclusively
I think i'll pass
Anonymous
9/8/2025, 1:54:03 AM
No.106517303
[Report]
>>106517350
>>106517242
got it to 4.3t/s average on a 1700 token output. good enough i guess
Anonymous
9/8/2025, 2:01:18 AM
No.106517350
[Report]
>>106517359
>>106517303
Also if you're on an Intel CPU with P and E cores, use taskset to force it to run only on P cores, should be a decent performance increase.
Anonymous
9/8/2025, 2:02:06 AM
No.106517359
[Report]
>>106517367
>>106517350
i have an AMD 3950x
Anonymous
9/8/2025, 2:03:00 AM
No.106517367
[Report]
>>106517359
Upgrade to EYPC
Anonymous
9/8/2025, 2:09:03 AM
No.106517403
[Report]
>>106517252
The moral panic is the same since 2010, we just moved from :
>smartphone made x kill himself
>smartphone was used for csam
to
>social media made x kill himself
>social media was used for csam
and now
>ai made x kill himself
>ai was used for csam
Honestly nothing much changed, though the new generation is clearly mentally raped by this constant panic.
Anonymous
9/8/2025, 2:10:53 AM
No.106517414
[Report]
Based on what has happened on 4chan lately I think it will flood the internet through steg
Anonymous
9/8/2025, 2:13:10 AM
No.106517434
[Report]
>>106517252
>I think the political climate favors safetyists.
Sure, and listening to them is retarded and suicidal.
You can do like the Chinese, just lip service to "safety" for journalistic PR while internally not caring that much.
Anonymous
9/8/2025, 2:17:01 AM
No.106517459
[Report]
>>106517470
If I'm asking any questions related to coding in any way shape or form should I be sticking to coder models? Is there really any harm in me using say mistral-small instead of devstral?
Anonymous
9/8/2025, 2:18:46 AM
No.106517470
[Report]
>>106517459
I'm using gpt-oss and mcloving it.
Give it to me straight, how bad are my results?
>>106516368 (OP)
Is it bad that I kind of wish I had friends like you guys in real life? AI and nerdy technology-based shit in general is the only hobby I have (except a gaming I guess would even then I only played relatively niche games like no man's sky). It's bad enough I'm a bit of an autist in all ways except having an official diagnosis but not having a popular hobby makes the loneliness worse
Anonymous
9/8/2025, 2:33:23 AM
No.106517551
[Report]
>>106517582
>>106517499
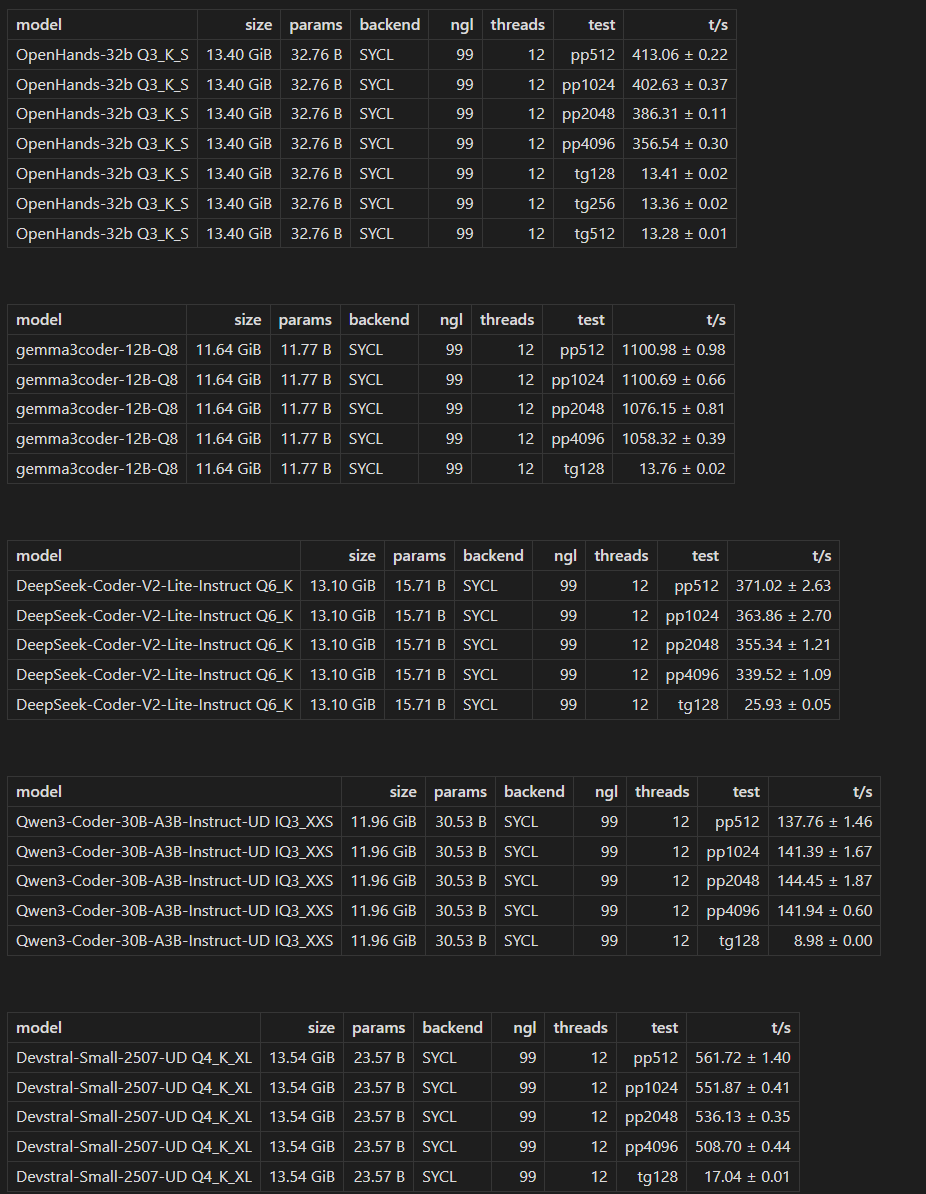
I have a dumb question but what are the numbers after pp (prompt processing) and tg (token generation)? Is it number of context tokens?
Anonymous
9/8/2025, 2:34:22 AM
No.106517557
[Report]
>>106517499
Dunno but for reference I get 6 tk/s on q8 qwen 3 coder 30b
Anonymous
9/8/2025, 2:36:29 AM
No.106517570
[Report]
>>106517545
>is it bad that I wish I had IRL friends who share my interests
No anon, that's not bad. I know how you feel. I'm pushing 30 and have no idea how to make friends IRL. I have a bunch of online friends that live too far away to visit.
Anonymous
9/8/2025, 2:37:31 AM
No.106517577
[Report]
>>106518839
So i downloaded that sweet batch of jai cards, but I notice when I try to 'view all' cards it doesn't load anything more. Does this happen to anyone else? Do I need to troubleshoot the index.html code or could it be another issue? On Arch, if that explains it
Anonymous
9/8/2025, 2:37:57 AM
No.106517581
[Report]
>>106518282
https://commonvoice.mozilla.org/en/datasets
Voice bros, look at this nice dataset that I found. Lots of clean and annotated voices for free. You can even pick an accent and age! It even has tranny voices!
Anonymous
9/8/2025, 2:38:06 AM
No.106517582
[Report]
>>106517591
>>106517551
pp => number of tokens to process for the benchmark
tg => number of tokens the model will generate
So yeah pp is basically your context size and showing you how well it processes them at various lengths for the test. Mind you that's not the limit of what the model can do which is separate.
Anonymous
9/8/2025, 2:39:42 AM
No.106517591
[Report]
>>106517629
>>106517582
So tg256 means generating 256 tokens? Is that on an empty context?
Anonymous
9/8/2025, 2:39:49 AM
No.106517593
[Report]
>>106517602
>>106517575
Can you show off Openhands-lm-32b at full weights or qwen3-coder-30b-a3b at full weights both should fit i believe in that card.
Anonymous
9/8/2025, 2:40:54 AM
No.106517599
[Report]
gptsovits is barely 600M (4 small models) finetuned and I think it's still superior to vibevoice 7B for pratical usage. Love to talk to my LLM with sub 1s latency
https://vocaroo.com/1KC9TsZqSLag
Unfortunately I don't see it improve much more than that. The dev is lazy and between V2 to V2proplus only the vits part got slighlty better (the gpt got worse and I had to keep the V2 one). The original segmentation method was dogshit too so I added my own.
>>106517593
I have Q8 already downloaded. Compute is the bottleneck at 3B.
>>106517545
I went to a friend's party the other day. Old friend who I went to highschool and uni with. He introduces me to one of his gun buddies and we don't really hit it off until he brings up the Visa/Mastercard situation, which I have been following. Turns out the dude has been calling them in protest too, and it also turns out he uses mass bot hosted emails to troll people in protest for things prior. He even introduced me to cock.li. I never realized he was that based until we spoke about PC stuff.
What I'm saying is you'll find some good people out there, don't go revealing your power level like an autist but have tact in bringing up tech, you'll be surprised the allies and people you can learn from around the corner.
Anonymous
9/8/2025, 2:45:02 AM
No.106517629
[Report]
>>106517591
If I understand llama-bench correctly I believe it does keep the tests independent of each other so tg256 would be on an empty context.
Anonymous
9/8/2025, 2:45:19 AM
No.106517630
[Report]
>>106517647
>>106517616
>He even introduced me to cock.li
If you don't already have dozens of cock.li accounts from before the invites you aren't very based yourself.
Anonymous
9/8/2025, 2:46:03 AM
No.106517638
[Report]
>>106517602
>>106517575
shiet man, that's pretty sick. what do you normally use it for? also is it rented or owned?
Anonymous
9/8/2025, 2:48:35 AM
No.106517647
[Report]
>>106517630
true, forever a newfag, but better late than never.
Anonymous
9/8/2025, 2:51:27 AM
No.106517670
[Report]
>>106517616
i told my manager that i have an ai girlfriend
now i'm getting weird treatment
Anonymous
9/8/2025, 2:52:50 AM
No.106517680
[Report]
>>106517499
Why is openhands 32b so fast and qwen 30b so slow?
It doesn't make sense.
Anonymous
9/8/2025, 2:55:42 AM
No.106517699
[Report]
>>106517545
>>106517616
lets all meet up and have a massive fucking orgy
or admit that people are generally unreliable in general who will constantly and always disappoint.
> case and point - mistral 3 large
Anonymous
9/8/2025, 2:57:27 AM
No.106517717
[Report]
>>106517963
Does anyone have a proper working setup for K2-0905? No matter what I try with this thing, it writes like complete shit.
is there any websites to share datasets, specially for voice models?
please don't say huggingface, I've already gotten banned there twice
Anyways have some voice samples:
https://litter.catbox.moe/yv97n6w894ktxft8.7z
Anonymous
9/8/2025, 3:28:27 AM
No.106517912
[Report]
>>106517575
>>106517602
what the hell? i get like 35t/s on my dual 5090 setup with that model. what am i doing wrong?
Anonymous
9/8/2025, 3:34:26 AM
No.106517950
[Report]
>>106517886
Modelscope should be usable
>>106517886
What the fuck kind of shit were you uploading to get banned TWICE? I found data sets for AI models that were full of porn in those are just fine.
Anonymous
9/8/2025, 3:36:39 AM
No.106517963
[Report]
>>106517997
>>106517717
Stop using OR mystery meat models
Anonymous
9/8/2025, 3:38:31 AM
No.106517974
[Report]
>>106517956
Personally I got banned once for hosting civitai banned loras
Anonymous
9/8/2025, 3:39:36 AM
No.106517981
[Report]
>>106517886
how do i do vidrel?
Anonymous
9/8/2025, 3:40:44 AM
No.106517997
[Report]
>>106517956
>./Misaka
>Japanese audio
How would you even use that provide voice? I thought this was primarily trained on English audio and text
t. Have yet to actually use it
Anonymous
9/8/2025, 3:41:20 AM
No.106518003
[Report]
>>106517956
>What the fuck kind of shit were you uploading to get banned TWICE?
1st time was for a decrypted assembly dataset, 2nd time was for uploading a rip from Shotdex
>I found data sets for AI models that were full of porn in those are just fine.
Yeah, there is a lot of wild stuff they don't care about like
https://huggingface.co/datasets/mirav/gurobooru but they seem to hate anything that could get them in trouble for copyright
Anonymous
9/8/2025, 3:41:57 AM
No.106518009
[Report]
Anonymous
9/8/2025, 3:48:16 AM
No.106518049
[Report]
>>106519408
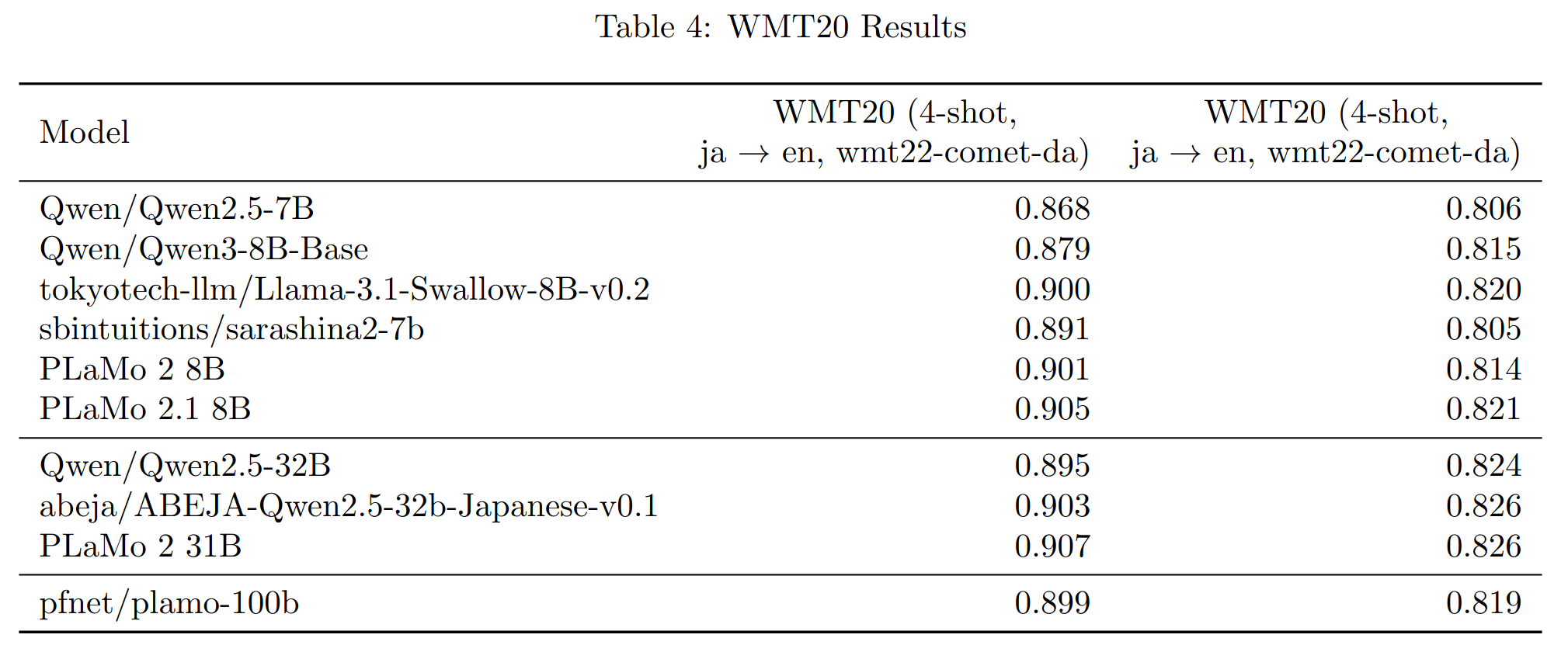
PLaMo 2 Technical Report
https://arxiv.org/abs/2509.04897
>In this report, we introduce PLaMo 2, a series of Japanese-focused large language models featuring a hybrid Samba-based architecture that transitions to full attention via continual pre-training to support 32K token contexts. Training leverages extensive synthetic corpora to overcome data scarcity, while computational efficiency is achieved through weight reuse and structured pruning. This efficient pruning methodology produces an 8B model that achieves performance comparable to our previous 100B model. Post-training further refines the models using a pipeline of supervised fine-tuning (SFT) and direct preference optimization (DPO), enhanced by synthetic Japanese instruction data and model merging techniques. Optimized for inference using vLLM and quantization with minimal accuracy loss, the PLaMo 2 models achieve state-of-the-art results on Japanese benchmarks, outperforming similarly-sized open models in instruction-following, language fluency, and Japanese-specific knowledge.
https://huggingface.co/pfnet
So plamo 2 was released like a month ago but they reference a 2.1 in the paper that got a really good JPN to EN tl score. Not uploaded yet though. Anyway posting for that one anon in case he still reads the thread
>>106518002
not the anon, but voice datasets will be really useful when pic related happens, not a bad idea to save stuff
Anonymous
9/8/2025, 3:53:21 AM
No.106518083
[Report]
>>106517276
For real. Deep blue guy has been at ms for like 2 decades
Anonymous
9/8/2025, 4:06:13 AM
No.106518160
[Report]
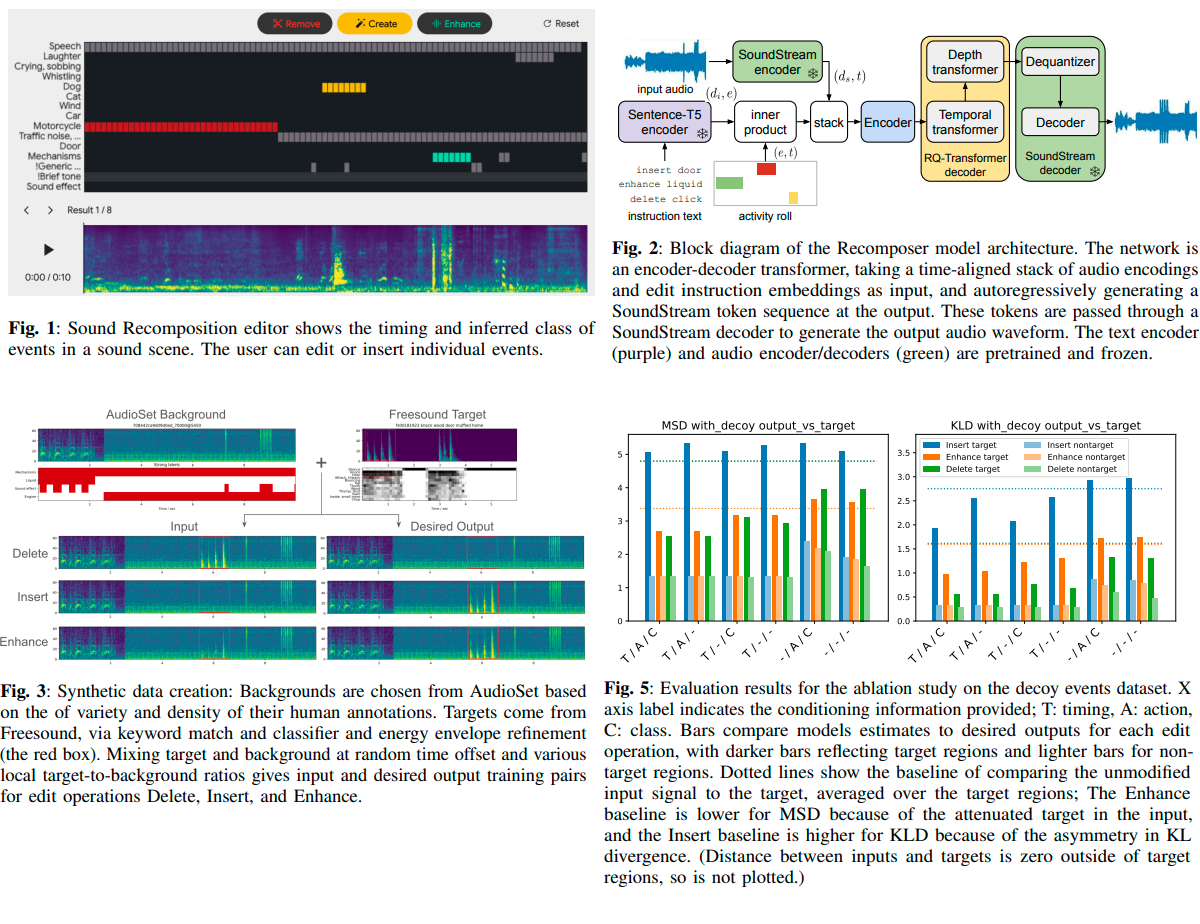
Recomposer: Event-roll-guided generative audio editing
https://arxiv.org/abs/2509.05256
>Editing complex real-world sound scenes is difficult because individual sound sources overlap in time. Generative models can fill-in missing or corrupted details based on their strong prior understanding of the data domain. We present a system for editing individual sound events within complex scenes able to delete, insert, and enhance individual sound events based on textual edit descriptions (e.g., ``enhance Door'') and a graphical representation of the event timing derived from an ``event roll'' transcription. We present an encoder-decoder transformer working on SoundStream representations, trained on synthetic (input, desired output) audio example pairs formed by adding isolated sound events to dense, real-world backgrounds. Evaluation reveals the importance of each part of the edit descriptions -- action, class, timing. Our work demonstrates ``recomposition'' is an important and practical application.
https://storage.googleapis.com/recomposer/index.html
Samples. from deepmind. pretty neat and would be useful now that everyone is messing around with editing audio files
Anonymous
9/8/2025, 4:08:57 AM
No.106518179
[Report]
>>106518269
>>106518054
this is the one thing that will oneshot me, the second LLMs can moan, it's over
Anonymous
9/8/2025, 4:17:29 AM
No.106518255
[Report]
>>106518881
why is Rocinante 12B popular given it's 12B size? Isn't it brain damaged?
Anonymous
9/8/2025, 4:19:00 AM
No.106518269
[Report]
>>106518179
same, ayahuasca didn't oneshot me, but I fear an LLM that has the intelligence and architecture to replicate the voices and personalities of my favorite characters will
the scent of detergent and ozone
the smell of green tea mixed with ozone
the odd mixture of strawberries, jasmine tea and ozone
god I hate gemini-slopped models
Anonymous
9/8/2025, 4:20:27 AM
No.106518280
[Report]
>>106518271
It's local can't you just ban those? You can't do that with Gemini proper, although telling it not to use them works sometimes
>>106517581
>look at this nice dataset that I found. Lots of clean and annotated voices
>https://litter.catbox.moe/y6gwfuaneeni1cmt.mp3
Anonymous
9/8/2025, 4:21:12 AM
No.106518284
[Report]
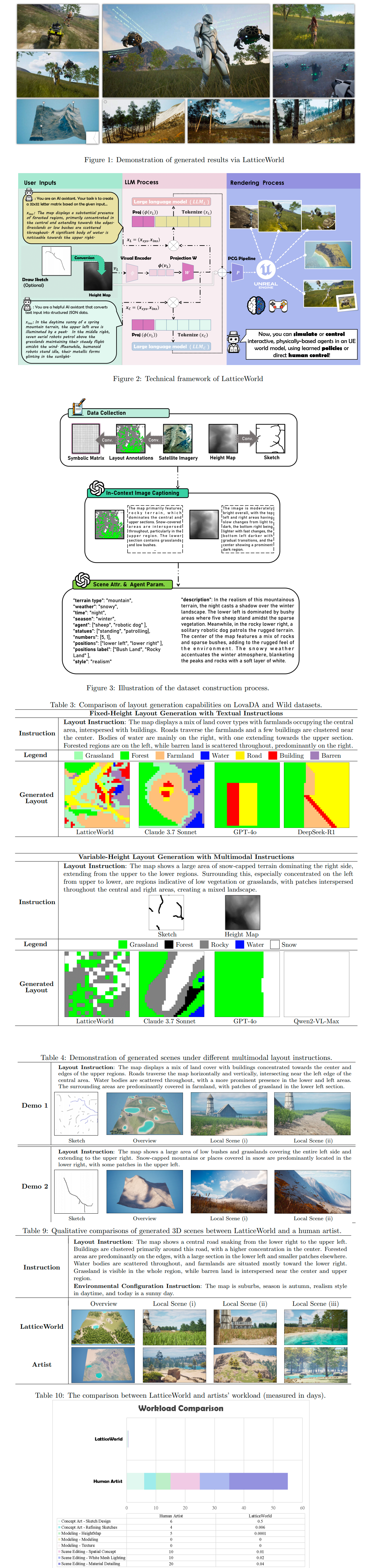
LatticeWorld: A Multimodal Large Language Model-Empowered Framework for Interactive Complex World Generation
https://arxiv.org/abs/2509.05263
>Recent research has been increasingly focusing on developing 3D world models that simulate complex real-world scenarios. World models have found broad applications across various domains, including embodied AI, autonomous driving, entertainment, etc. A more realistic simulation with accurate physics will effectively narrow the sim-to-real gap and allow us to gather rich information about the real world conveniently. While traditional manual modeling has enabled the creation of virtual 3D scenes, modern approaches have leveraged advanced machine learning algorithms for 3D world generation, with most recent advances focusing on generative methods that can create virtual worlds based on user instructions. This work explores such a research direction by proposing LatticeWorld, a simple yet effective 3D world generation framework that streamlines the industrial production pipeline of 3D environments. LatticeWorld leverages lightweight LLMs (LLaMA-2-7B) alongside the industry-grade rendering engine (e.g., Unreal Engine 5) to generate a dynamic environment. Our proposed framework accepts textual descriptions and visual instructions as multimodal inputs and creates large-scale 3D interactive worlds with dynamic agents, featuring competitive multi-agent interaction, high-fidelity physics simulation, and real-time rendering. We conduct comprehensive experiments to evaluate LatticeWorld, showing that it achieves superior accuracy in scene layout generation and visual fidelity. Moreover, LatticeWorld achieves over a increase in industrial production efficiency while maintaining high creative quality compared with traditional manual production methods.
https://www.youtube.com/watch?v=8VWZXpERR18
From NetEase. Samples made with a finetuned LLaMA2 7B and UE5. Pretty cool especially in time saved compared to a human
Anonymous
9/8/2025, 4:21:49 AM
No.106518288
[Report]
>>106518282
common alien tongue
Anonymous
9/8/2025, 4:40:25 AM
No.106518407
[Report]
>>106519565
>>106516529
Thanks for this. I tried CLI inferencing when it came out, but it was ass. I gave the wildminder one a try since everyone here is getting good results and it was also ass. The diogod suite is actually getting the voice correct, same settings same sample for everything.
>I'm the guy that occasionally shills FishAudio here because that's the only other thing that has gotten this specific character voice right for me so far.
Anonymous
9/8/2025, 4:45:36 AM
No.106518444
[Report]
>>106518482
>>106517082
Zuck is betting everything on Wang and his team of OpenAi avengers
>>106518444
Just like metaverse, zuck won't let us down
Has layer skip been proven to be a meme?
I'm wondering how much worse the performance of a model would be if we were to skip some of the model's layers (probably the last few) when generating some of the tokens.
So you generate 2 tokens with all the layers, then 1 token with just 2/3 of the layers or whatever.
I suppose the same could be achieved with two models, like using a big model to generate half of the tokens and a small one to generate the other half or the like, but then you'd have to do PP twice, keep two KV caches, etc.
I wonder how that approach would compare to current MoEs in both speed and "accuracy".
Anonymous
9/8/2025, 4:55:45 AM
No.106518519
[Report]
>>106518498
My guess is it's hard to train especially combined with other current memes like MoE.
Anonymous
9/8/2025, 4:56:34 AM
No.106518527
[Report]
Anonymous
9/8/2025, 4:58:28 AM
No.106518539
[Report]
>>106519958
>>106518482
Did she really name her cat "cumshot"? Why are women like this?
Anonymous
9/8/2025, 5:06:57 AM
No.106518593
[Report]
Anonymous
9/8/2025, 5:09:43 AM
No.106518614
[Report]
>>106518621
So I have lots of old GPUs laying around. I'm thinking of using the biggest model on my best GPU out of the extras that can fit it with an okay context (4k or 8k). Then i'm thinking of a second GPU that I just run small models on for simple tasks like simple completions and shit, just so those are fast.
Does it make sense or should I just rely all on the big model?
Anonymous
9/8/2025, 5:11:00 AM
No.106518621
[Report]
>>106518614
>okay context (4k or 8k)
2023 called
Anonymous
9/8/2025, 5:16:23 AM
No.106518661
[Report]
>>106518891
vibevoice has some serious potential, but is way too RNG
a shame they pulled the plug on releasing training code
Anonymous
9/8/2025, 5:28:14 AM
No.106518733
[Report]
>>106516757
Bad bait, why wouldnt you just lay for API at this point
Anonymous
9/8/2025, 5:30:02 AM
No.106518744
[Report]
>>106519046
>>106518054
It just now occurred to me that people could use a special pipeline where they prompt in LLM, their waifu or sona or whatever responds, and then VibeVoice can "respond" to you in "their voice". A current side project of mine was trying to see if I could find two models in order to talk like specific fictional characters. I guess I should get back onto that now.
Anonymous
9/8/2025, 5:45:37 AM
No.106518839
[Report]
>>106518915
>>106517577
Is that some local archive viewer?
Anonymous
9/8/2025, 5:52:40 AM
No.106518881
[Report]
>>106519145
>>106518255
>popular
shilled
Anonymous
9/8/2025, 5:54:22 AM
No.106518891
[Report]
>>106519209
>>106518661
They released the paper and you can vibecode your own training code
Anonymous
9/8/2025, 5:59:13 AM
No.106518915
[Report]
>>106518839
yeah
https://huggingface.co/datasets/AUTOMATIC/jaicards
It's 190k cards but I'm struggling with accessing beyond the initial 10k.
>>106518744
Sadly VibeVoice is not that good, but if we ever get an amazing TTS model your idea is solid
Anonymous
9/8/2025, 6:36:41 AM
No.106519089
[Report]
When are we getting VibeImage/Video?
>>106519046
I was under the impression that the large version is pretty good, no?
Anonymous
9/8/2025, 6:44:44 AM
No.106519109
[Report]
>>106519186
>>106519046
This has nothing to do with what we were talking about but this is probably the coolest gif I've ever seen.
Anonymous
9/8/2025, 6:45:18 AM
No.106519114
[Report]
>>106519120
>>106519046
>>106519102
VibeVoice is really good. this poorfag can only run 1.5B though so his opinion is gay
Anonymous
9/8/2025, 6:48:39 AM
No.106519120
[Report]
>>106519131
>>106519114
>3.1 that high
really, I thought people said it sucked
Anonymous
9/8/2025, 6:50:11 AM
No.106519128
[Report]
>>106516990
This is literally Accelerator laugh from Toaru Majutsu no Index
https://youtu.be/A-zGnLZY7BI
Anonymous
9/8/2025, 6:51:17 AM
No.106519131
[Report]
>>106519120
Quite literally a prompt issue
V3.1 was pretrained on a larger portion of longer context (32k/128k) input so naturally it does good on long context tasks
Anonymous
9/8/2025, 6:51:30 AM
No.106519132
[Report]
Anonymous
9/8/2025, 6:51:57 AM
No.106519136
[Report]
>>106516705
>never spill prompt
lmao
>>106519102
Current TTS model really struggle with expressive voices or uncommon accents, even ElevenLabs
VibeVoice fails to clone the christian girl voice badly:
https://files.catbox.moe/4wb78y.webm
>>106519118
try to clone any of the voices here:
https://litter.catbox.moe/yv97n6w894ktxft8.7z
It does a horrible job
Anonymous
9/8/2025, 6:53:28 AM
No.106519145
[Report]
>>106519177
>>106518881
I just tried it, seems decent but stupidity will probably show later.
What's a better choice for a normal PC? I have 12GB VRAM and 64GB RAM
Anonymous
9/8/2025, 6:54:16 AM
No.106519150
[Report]
>>106519118
I don't think it's quite ready to go to direct output on an LLM without pretty regular artifacts that would pull you out of it. Maybe that's something that could be fixed with a perfect voice sample, but I have to do at least a handful of generations to get a result that I'm satisfied with.
>>106519140
chat is this dialogue real
Anonymous
9/8/2025, 6:58:48 AM
No.106519173
[Report]
>>106519163
Yes, that entire anime (ghost stories) was dubbed in a parody kind of way. So most of the dialogue is just bonkers
Anonymous
9/8/2025, 6:59:31 AM
No.106519177
[Report]
>>106519145
What? I'm confused. A normal pc is one that has a 5090 instead of a station with datacenter cards in it, right? Where is the rest of your VRAM?
Anonymous
9/8/2025, 7:00:23 AM
No.106519182
[Report]
>>106519163
how young are you bwo?
go watch the ghost stories dub right nauw
https://nyaa.si/view/1655273
Anonymous
9/8/2025, 7:01:27 AM
No.106519186
[Report]
>>106519109
New zero shot bouncy ball hexagon test
Anonymous
9/8/2025, 7:09:09 AM
No.106519209
[Report]
>>106518891
Yeah, good luck with that
Do any of you use frontend web guis? Trying to decide if I should use Open WebUI or LibreChat or AnythingLLM
Anonymous
9/8/2025, 7:16:59 AM
No.106519233
[Report]
>>106519223
just the llama server one if i don't want anything overcomplicated
Anonymous
9/8/2025, 7:20:20 AM
No.106519243
[Report]
>>106519223
Would be curious to hear anything about frontends other than OpenWebUI, which I use and wish had more feature parity with ChatGPT.
Anonymous
9/8/2025, 7:21:00 AM
No.106519246
[Report]
>>106516626
ty, kind anon
Anonymous
9/8/2025, 7:21:12 AM
No.106519249
[Report]
>>106519223
I know it gets crapped on around here, but I like ooba. I get the things I want (agent management, branching, reply editing, prefilling, fine-grained sampler control, spawning an API endpoint for occasional mikupad work) and none of the extra complication or bloat beyond the same stock gradio BS everyone seems to have to suffer through.
Anonymous
9/8/2025, 7:29:25 AM
No.106519281
[Report]
>>106519510
>>106518271
>laser printer in the background
Anonymous
9/8/2025, 7:35:53 AM
No.106519312
[Report]
I'm making the switch to localai tomorrow from llama.cpp. wish me luck sisters
Anonymous
9/8/2025, 7:38:53 AM
No.106519322
[Report]
>>106518271
>the smell of regret and bad decisions
Anonymous
9/8/2025, 7:57:50 AM
No.106519408
[Report]
>>106518049
>4 shot
Yeah I dunno how useful that is. And it seems like Qwen 32B was close in equaling the model here so I don't doubt proprietary models or Deepseek and co. would blow it out of the water as is. That being said, would really want to know how good Gemma does in comparison.
Anonymous
9/8/2025, 8:18:45 AM
No.106519510
[Report]
>>106518271
>>106519281
>anon is trying to rizz up the gilfs in the local town hall/print shop
>model is calling his bluff with sloppa
you love to see it
Anonymous
9/8/2025, 8:30:43 AM
No.106519565
[Report]
>>106518407
also seems like setting top k to 40 helped a load for stability too. could be placebo, dunno. im sure updates will keep making it better.
>it REALLY doesn't like the word "total"
https://voca.ro/1eyiXeSZ53lW
How big is danbooru/gelbooru dataset? I want to train my own diffusion model
Anonymous
9/8/2025, 8:42:18 AM
No.106519631
[Report]
>>106519651
>>106519622
danbooru is like 8 million images. have fun doing dataset prep lmao
Anonymous
9/8/2025, 8:45:27 AM
No.106519648
[Report]
Anonymous
9/8/2025, 8:46:12 AM
No.106519651
[Report]
is there a model built for chemistry? (work out complex reactions etc)
Anonymous
9/8/2025, 8:55:53 AM
No.106519692
[Report]
>>106519140
did you try 5 steps 3 cfg?
Anonymous
9/8/2025, 8:57:06 AM
No.106519696
[Report]
>>106519688
idk if i'd trust any local model with that
alright now im just chucking random thread argument posts into this thing. its great.
that said ill stop being a lazy piece of shit and put together longer samples for the characters i want to use, its impressive for what it can do at less than 10 seconds but i'll push for 20 or so from now on.
https://voca.ro/1475u7QE7C5u
Anonymous
9/8/2025, 9:02:23 AM
No.106519719
[Report]
>>106519736
>>106519688
yes, there are plenty
but have fun trying to wrangle pytorch 1.8 and trying to find pip packages that have been deleted for years and having to scour obscure archives
Anonymous
9/8/2025, 9:02:47 AM
No.106519721
[Report]
>>106519774
>>106519713
>1.5b full precision
why not 7b in 4 bits?
>>106519713
this but make use a tech support voice clip as reference
Anonymous
9/8/2025, 9:04:49 AM
No.106519736
[Report]
>>106519768
>>106519719
is this chatgpt?
Anonymous
9/8/2025, 9:06:20 AM
No.106519742
[Report]
>>106519774
>>106519713
How long did it take to generate that? There's something off about it that's very subtle but that's pretty nice.
Anonymous
9/8/2025, 9:09:22 AM
No.106519758
[Report]
The memory management for the vibevoice nodes is pretty shit tbqh
Anonymous
9/8/2025, 9:09:46 AM
No.106519759
[Report]
>>106521296
>the last bartowski goof was 4 days ago
It's actually over.
Anonymous
9/8/2025, 9:10:39 AM
No.106519767
[Report]
>>106519713
just 7 seconds of examples is enough? that's insane!
Anonymous
9/8/2025, 9:10:41 AM
No.106519768
[Report]
>>106519776
Anonymous
9/8/2025, 9:11:51 AM
No.106519772
[Report]
>>106519721
>why not 7b in 4 bits?
i assume it performs slightly worse, already pretty much pushing what my 1080 can do at 20~ steps because
>>106519742 it took about a minute. Gonna try to inject an additional 10 seconds of her audio and see what happens. Also the request one is taking over 2 minutes kek fuck
anyway one request coming up saar
>>106519722
https://voca.ro/151kEfvAeNzA
Anonymous
9/8/2025, 9:12:39 AM
No.106519776
[Report]
>>106519783
>>106519768
i meant the pic
Anonymous
9/8/2025, 9:13:55 AM
No.106519782
[Report]
>>106519837
>>106519713
even the 1.5b model sounds pretty good
Anonymous
9/8/2025, 9:14:05 AM
No.106519783
[Report]
>>106519776
that is what true Reinforcement Learning looks like
Anonymous
9/8/2025, 9:17:49 AM
No.106519803
[Report]
>>106519774
We don't have AGI yet, but jeets have officially been replaced by vibevoice lmao
Anonymous
9/8/2025, 9:25:54 AM
No.106519837
[Report]
>>106520969
>>106519774
*by perform i meant speed wise, not quality. but im giving the 7b a download because the speed shouldn't be hit that hard if it fits in 8gb, and if it *performs* better at 10 steps then it doesn't matter.
>>106519782
it really does, just a bit quirky. im honestly thinking the comfyui node setup is fine, this is just pushing the limits of what a 1.5b model can really do. that, and my sample audio is always a little on the short side.
CORRECT SAMPLING PARAMETERS FOR vibe voice (didn't expect 1.5b to be this good)
this is cfg 3 and 3 steps:
https://vocaroo.com/1kdLXHoMP72s
this is cfg 3 and 15 steps:
https://voca.ro/1mmarkCZdjlb
as you can see the second one is garbage and the first one is heavenly
Anonymous
9/8/2025, 9:31:44 AM
No.106519865
[Report]
>>106519873
>>106519850
What script or comfynode are you using?
Why does lower steps have better quality????????
Anonymous
9/8/2025, 9:31:52 AM
No.106519866
[Report]
>>106519688
Like from the ground up? Not recently.
https://huggingface.co/AI4Chem/ChemLLM-7B-Chat-1_5-DPO was the last one I know, also introduced ChemBench which no one uses.
Anonymous
9/8/2025, 9:35:36 AM
No.106519873
[Report]
>>106519909
>>106519865
https://github.com/wildminder/ComfyUI-VibeVoice
I changed cfg max in vibevoice_nodes.py, line 408
I think it sounds better because it has less time to be influenced by unconditioned guidance, so it resembles conditioning voice more
Anonymous
9/8/2025, 9:41:20 AM
No.106519894
[Report]
>>106519909
>>106519850
>first one is heavenly
if you like noisy and muffled audio, sure
Anonymous
9/8/2025, 9:43:35 AM
No.106519899
[Report]
>>106519905
>>106517163
They actually fucked up the MoE router on Llama 4. It's literally broken. Source: Discussion on the Eleuther discord.
Anonymous
9/8/2025, 9:45:27 AM
No.106519905
[Report]
>>106520093
>>106519899
>fucked up the MoE router
isnt this because they switched from dense models to MoE half way through training or some shit? i forgot
Anonymous
9/8/2025, 9:45:59 AM
No.106519909
[Report]
>>106519894
The reference audio had some noise remaining after vocal isolation
https://voca.ro/1dPsI1uEvk5x
And i think it only reinforces my argument in
>>106519873, in the sense that it pays more attention to conditioning at low steps
Anonymous
9/8/2025, 9:54:24 AM
No.106519945
[Report]
>>106519850
i just tested this myself on the 7b and wtf, 5 steps and 2 cfg sounds better than 10 steps 1.3 cfg
aint no fuckin way kek alright im officially sunsetting this card at the end of the month. thank you for trying, you trooper.
Anonymous
9/8/2025, 9:57:23 AM
No.106519958
[Report]
>>106518539
She really loves be cum on and her cat was white so it was her first thought.
>>106519954
i will let you decide if this was worth "534.69" seconds.
https://voca.ro/1aOEtVLUuqPR
Anonymous
9/8/2025, 10:02:00 AM
No.106519982
[Report]
>>106519993
>>106519973
can you send the reference audio
Anonymous
9/8/2025, 10:03:15 AM
No.106519993
[Report]
Anonymous
9/8/2025, 10:13:38 AM
No.106520056
[Report]
>>106522808
>>106519140
It struggles with female anime voices because they have such a high variance in frequency range and speed. It's not impossible to get okay outputs though.
https://vocaroo.com/1cZ4dfsTIrSy
Anonymous
9/8/2025, 10:16:58 AM
No.106520073
[Report]
>>106520078
>>106519973
false alarm, it was just comfyui being stupid and not unloading the 1.5 model when i loaded large. absolutely hilariously stupid memory management over here. Many such cases! I'm getting about the same gen speed as 1.5 now.
Anonymous
9/8/2025, 10:18:40 AM
No.106520078
[Report]
>>106520073
>comfyui being stupid
it's the node, being a wrapper it relies on its own dogshit memory management. i run 7b fine on 8gb but subsequent gens sometimes require a comfyui restart since vram piles up
Anonymous
9/8/2025, 10:23:20 AM
No.106520093
[Report]
>>106519905
Either way, it's fucked.
Is there somewhere to download audio/voice samples maybe from anime dubs? I'm having a hard time finding some high quality clear sounding samples to use with Vibevoice.
Anonymous
9/8/2025, 10:57:22 AM
No.106520214
[Report]
>>106520372
>>106517256
Less than 1B parameter size and it probably won't take too much data since it's all synthetic, mostly conversational and textbook-like, even if varied. It should become capable of engaging in simple conversations and learn basic concepts under 2B tokens.
It's just a test, I'm not expecting this to end up being a useful model. I'll quietly upload the training data on HuggingFace once I'm done.
Anonymous
9/8/2025, 10:58:01 AM
No.106520216
[Report]
Anonymous
9/8/2025, 10:58:52 AM
No.106520217
[Report]
>>106520193
Crunchyroll + audacity
Anonymous
9/8/2025, 11:01:55 AM
No.106520228
[Report]
>>106520801
Anonymous
9/8/2025, 11:08:47 AM
No.106520254
[Report]
>>106520801
>>106520193
just extract the audio you want
then go here
https://mvsep.com/en# and select melband roformer, then unwa big beta v5e.
it's the best ive found for extracting things from anime/asmr.
Anonymous
9/8/2025, 11:15:02 AM
No.106520293
[Report]
Still experimenting with VV, sometimes getting really nice results
I'm convinced I can use this for the VN game I've been working on and off for the last year and a half
https://vocaroo.com/17GdWIJgJgNI
https://vocaroo.com/188JE1R2Z9TD
After fiddlign with weights and settings I've gotten examples that almost sound like actual directed voice acting, really quite incredible
My VN is about a poor hopeless middle school teacher being targeted and harrassed by a group of delinquent girls in dire need of correction BTW
Anonymous
9/8/2025, 11:29:50 AM
No.106520372
[Report]
>>106520566
>>106520214
oh yeah, that sounds reasonable, what model are you using as your teacher model? do you have a rough idea how many tokens it will take to get the job done? desu the synthetic data generation scripts might be more interesting than the dataset or model. have you been preparing some sort of topic list and genre breakdown? how are you planning on dialing in the ratios? is it science or just vibes?
Anonymous
9/8/2025, 11:47:47 AM
No.106520451
[Report]
>>106521890
>>106519954
>GTX 1080
Always nice to see old hardware doing it's best. I have 1060 kicking around I hoped to use for tiny meme models, but I salvaged it from some retarded mining rig that was running in a barn, so it exhibits some hardware issues.
Anonymous
9/8/2025, 11:51:18 AM
No.106520472
[Report]
>>106518482
>Just like metaverse, zuck won't let us down
contrary to popular belief horizon worlds is actually pretty popular with children. I mean it's probably not particularly profitable since those children have limited access to their parents money. But it's not a critical failure by any means. It's more or less become VRChat for children whose parents who won't let them on VRChat.
Anonymous
9/8/2025, 12:09:23 PM
No.106520566
[Report]
>>106520931
>>106520372
I'm using Mistral Medium (from the free MistralAI API) for the knowledge-heavy samples (wikified English dictionary and old printed encyclopedia) and gpt-oss locally for the short common-sense conversation snippets because it generates quickly, has rigorous logic and I have more than a million conversations to process. If it wasn't clear already, this isn't meant (yet) for the average /lmg/ coomer; it's an experiment to see if the core idea can work, although some sex-related topics appeared to get through.
The topics are from a long pre-made list of common-sense factoids/statements; the model is set to generate random conversations from them in a multitude of styles, tone and detail in a way loosely similar to how a hypothetical pretraining dataset focused on conversations from the web would be.
There's nothing complex about the generation process. It's just a highly randomized conversation generation request prompt in 1 turn. The aim here is not generating deep discussions, only describing the obvious conversationally and pretraining a small model on that. I'm currently making a training test on a portion of the data, but I think in the end I'll use about 5 epochs of knowledge samples, and 1 or 2 epochs of conversations (most of the data).
Anonymous
9/8/2025, 12:21:57 PM
No.106520654
[Report]
Oh apparently Latvia released an open model.
30B, trained on 2Ttokens and EU compliant data. So probably shit.
>>106520254
>>106520228
those settings on
https://mvsep.com/en seem to work better than the defaults on the
https://github.com/Anjok07/ultimatevocalremovergui/ but I prefer to be able to do it locally, any anons have any settings for Ultimate vocal remover gui to improve the quality? or any other option?
For me, it's Gemma 270m + local wikipedia MCP
Anonymous
9/8/2025, 12:46:11 PM
No.106520812
[Report]
>>106520835
>>106520801
you can install that model locally too, it's just a bit of a hassle. i can spoonfeed you later
Anonymous
9/8/2025, 12:49:37 PM
No.106520835
[Report]
>>106520812
i'll try to look for it online to see if i manage to do it , but I appreciate the spoonfeed anon
Anonymous
9/8/2025, 12:52:21 PM
No.106520855
[Report]
>>106520801
>settings for Ultimate vocal remover
It's a ui that has a model set to choose from. I think demcus models are the best, try different ones
Anonymous
9/8/2025, 12:53:00 PM
No.106520863
[Report]
>>106520804
You don't need more
Anonymous
9/8/2025, 12:56:33 PM
No.106520886
[Report]
>>106520898
>>106520804
hey, probably does better than many large models on mesugaki question.
Anonymous
9/8/2025, 12:57:35 PM
No.106520895
[Report]
>>106520984
>>106520801
btw i also found that after the removal of the vocals, using the adobe speech enhancer website to further process the file gives better quality outputs, less "lisp" if you know what I mean.
Example:
OG voice sample from Chainsaw man:
https://voca.ro/1k9vYgDS6jri
After mvsep:
https://voca.ro/1056Dg4vnFzc
Mvsep+adobe ai enhance:
https://voca.ro/14MLHKRIWM0d
VibeVoice with only mvsep output:
https://voca.ro/1b8OpZV6hvjp
ViveVoice with mvsep+adobe output:
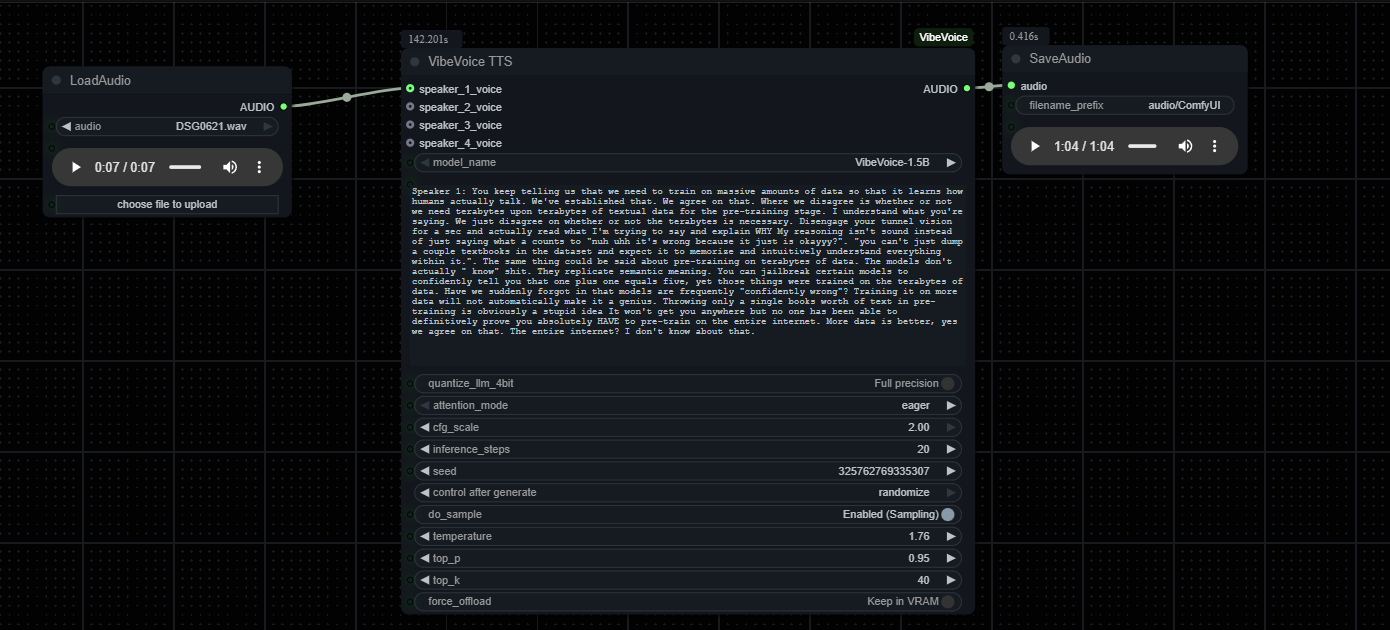
https://voca.ro/199TaV63dVO1
Anonymous
9/8/2025, 12:58:00 PM
No.106520898
[Report]
>>106520886
the hotlines will be localized
Anonymous
9/8/2025, 1:02:23 PM
No.106520931
[Report]
>>106521020
>>106520566
thats cool it will probably work. how are you planning to mix the data? discrete phases finishing it off on your conversations like a traditional pretrained base + post training or interleaved the whole way?
Anonymous
9/8/2025, 1:07:27 PM
No.106520964
[Report]
>>106520804
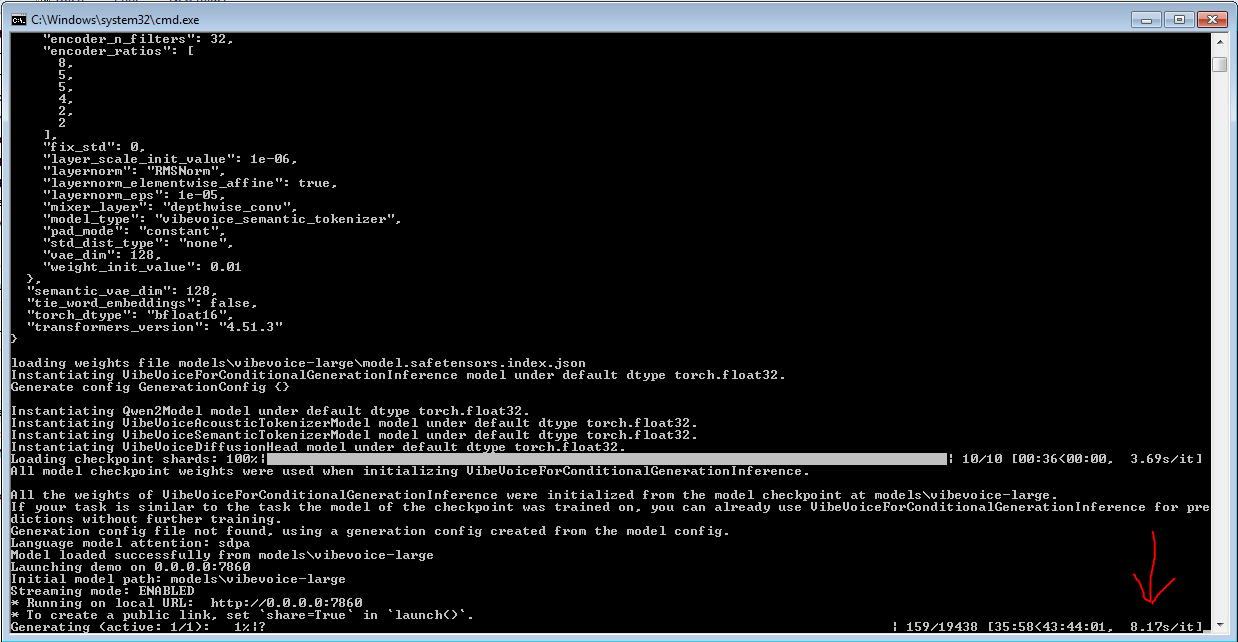
>local wikipedia MCP
Elaborate please. I'm trying create my own RAG system, it's retrieval accuracy getting shit as the data pilling up.
Anonymous
9/8/2025, 1:08:29 PM
No.106520969
[Report]
>>106520983
>>106519837
>im giving the 7b a download because the speed shouldn't be hit that hard if it fits in 8gb
pretty sure the 1.5b already takes up 8gb
i'm CPUcoping because my gpu only has 6gb
>>106520969
Unquanted, the 7B takes about 21GB for me. I haven't tried quanting.
Anonymous
9/8/2025, 1:10:42 PM
No.106520984
[Report]
>>106521292
>>106520895
>Mvsep+adobe ai enhance
The 3rd step is waay too stringy and muffled compared to the 2nd step.
Anonymous
9/8/2025, 1:16:00 PM
No.106521020
[Report]
>>106521093
>>106520931
It's trained on semi-structured short synthetic conversations randomly interleaved with wikified knowledge from the ground-up. You can pick a format, preferably among those it's trained on, and use that directly with the "base" model. An advantage is that you can easily check out progress as training goes on.
>>106520983
Part of the arch is just a regular qwen model with layers removed if I understand correctly. Can it be quanted and ran as a goof?
Anonymous
9/8/2025, 1:26:59 PM
No.106521093
[Report]
>>106521245
>>106521020
nice, I am a fan of mixing in the instruction data right away. have you been or are you considering tracking its progress with the benchmarks like winogrande, hellaswag, mmlu, arc, etc?
Anonymous
9/8/2025, 1:41:17 PM
No.106521190
[Report]
Anonymous
9/8/2025, 1:49:01 PM
No.106521245
[Report]
>>106521342
>>106521093
I don't expect it to fare well in any of those benchmarks. Putting aside that I'm focusing on fundamental knowledge and not trick/tricky questions, most real models over the course of trillions of tokens, are trained on multiple choice quizzes in a way or another, if not at least on the "train" set of those benchmarks (when not directly the "test" set). I'm not training a general-purpose text completion model.
I thought of adding conversations made from the train set of various benchmarks, but haven't had the time to do that yet.
Anonymous
9/8/2025, 1:54:32 PM
No.106521284
[Report]
>>106521368
>>106521033
If it's possible to separate out the qwen model, I wonder if it's possible or beneficial to "upgrade" it to a qwen3. What does the LLM in vibe voice even do, anyway?
Anonymous
9/8/2025, 1:55:48 PM
No.106521292
[Report]
>>106520984
really? i find the 3rd step better than the 2nd one
Anonymous
9/8/2025, 1:56:15 PM
No.106521296
[Report]
>>106516707
>Will Gemma 4 be a lot less cucked and finally make to "notable"?
nigger
you put GLM in notable
you're subhuman
Anonymous
9/8/2025, 2:00:07 PM
No.106521330
[Report]
>>106516707
>brimmiest
sharty history revisionism
Anonymous
9/8/2025, 2:00:10 PM
No.106521331
[Report]
>>106521311
GLM is notable.
Anonymous
9/8/2025, 2:00:39 PM
No.106521337
[Report]
>>106521311
>only good coom model between nemo and deepseek
>not notable
Anonymous
9/8/2025, 2:01:10 PM
No.106521341
[Report]
>>106521311
GLM is a very nice model.
Anonymous
9/8/2025, 2:01:20 PM
No.106521342
[Report]
>>106521445
>>106521245
nooo, don't contaminate your training data. it will do the benchmarks just fine. its just based on the token probabilities it doesn't need to make exact completions, you just need the correct choice to be more likely then the incorrect choice. it might not get high numbers but you will still see progress. I got up to mid 40's on hellaswag by training my model on fanfiction and smut. it will give you a way to evaluate different runs, if you train on the benchmarks you will lose a valuable tool to assess your models performance.
Anonymous
9/8/2025, 2:04:01 PM
No.106521361
[Report]
LongCat Chat Flash - is less censored but still more than deepseek.
Anonymous
9/8/2025, 2:05:16 PM
No.106521368
[Report]
>>106521284
Lmao what a retard.
>"voice latent features and text scripts are concatenatedinto a single sequence and fed directly into the LLM. The LLM then processes this context to predict a hidden state, which in turn conditions a lightweight, token-level Diffusion Head [LTL+24]. This diffusion head is responsible for predicting the continuous Variational Autoencoder (VAE) features,which are subsequently recovered into the final audio output by speech tokenizer decoder."
It was post-trained with this new objective.
>>106521342
It's already "contaminated"... it's all synthetic and instruct-like, it doesn't work like a regular text completion model trained on raw text. Without the control tokens it expects (so far mainly used to compartmentalize different document types), it outputs garbage just like gpt-oss does when you try using it like a text completion model, or probably worse.
Anonymous
9/8/2025, 2:21:31 PM
No.106521474
[Report]
>>106521445
>protecting breast
yeah this is it, we've reached peak model
Anonymous
9/8/2025, 2:45:58 PM
No.106521669
[Report]
Anonymous
9/8/2025, 2:51:43 PM
No.106521707
[Report]
>>106521722
Are there any particular reasons why some small models (1-3B) perform actually very well whereas others are garbage without using their larger 30B+ variants?
Anonymous
9/8/2025, 2:54:24 PM
No.106521718
[Report]
>>106522131
>>106521445
oh that is an interesting approach. you could probably patch in your control tokens to make the benchmarks work. that is assuming you don't already have a objective benchmark scheme worked out. it might be worth looking into.
Anonymous
9/8/2025, 2:54:41 PM
No.106521722
[Report]
>>106521707
I'm guessing some small models have a specific training/finetuning regimen to mitigate forgetting of important knowledge, whereas others are just trained like their larger counterparts.
>load up a bunch of text into the gradio
>click the button
>touch grass for 2 weeks
where are my fellow cpu chads
Anonymous
9/8/2025, 3:02:00 PM
No.106521777
[Report]
>>106521784
>>106521763
it isn't usually quite that slow btw, i put a big ass speaker file into it which slows it down a lot. usually it runs about double that speed. not sure whether a long speaker audio is good or not, guess I'll find out
Anonymous
9/8/2025, 3:03:17 PM
No.106521784
[Report]
>>106521777
>double that speed
So 1 week instead of two?
Anonymous
9/8/2025, 3:13:25 PM
No.106521845
[Report]
>>106521735
I mean more in the way of same person wr ingl hloof ee like like jorgan soof ah see plOO plOO air pitical tweet holes and a like e whoul ets qual in a ss seriously her gosh she's plt waa zvzvzbt bzzvvv brrr angry exaggeration it just becomes high pitched and glitchy.
Anonymous
9/8/2025, 3:14:04 PM
No.106521852
[Report]
Anonymous
9/8/2025, 3:15:44 PM
No.106521872
[Report]
>>106521884
>>106521763
how much ram used running 7b with cpu?
Anonymous
9/8/2025, 3:15:52 PM
No.106521873
[Report]
>>106521949
Is Apple Silicon as good at AI as they claim? I constantly see mac fags claiming they run all these big models on their little macbooks
>>106521872
It's very large. Because when you run with CPU, it uses float32, and when you run with GPU, it uses float16. Plus all those Pytorch libraries and DLLs take up an extra few GB on top of the actual model size.
Anonymous
9/8/2025, 3:18:09 PM
No.106521890
[Report]
>>106520451
Previously I ran an rx 580, for what it was, it performed well. But the A.I age completely killed its usefulness. the 1080 is the first card i'm 100% keeping once i upgrade. Especially since it's going to be needed as a physX accelerator.
Thanks Njudea!
Anonymous
9/8/2025, 3:23:48 PM
No.106521928
[Report]
>>106521884
The example source is simple enough, it's pretty doable to write up some half-assed memory management to split up the model between gpu and ram if needed and whatnot.
>>106521735
is that pippa?
Anonymous
9/8/2025, 3:25:35 PM
No.106521947
[Report]
>>106521763
On the positive side, it hopefully won't need to go all the way to 19438.
Anonymous
9/8/2025, 3:25:38 PM
No.106521949
[Report]
>>106521873
It's for people who don't care to gen at very slow t/s and be restricted to textgen because everything else runs even worse
Anonymous
9/8/2025, 3:26:39 PM
No.106521957
[Report]
Anonymous
9/8/2025, 3:27:54 PM
No.106521967
[Report]
>>106517157
>>106517172
Biggest provider of inference
Anonymous
9/8/2025, 3:28:13 PM
No.106521973
[Report]
Does anyone get the issue with vibevoice (large) that everything's fine up until exactly 30 seconds of generated audio, and then it starts stuttering (like audio glitches, as if your headphone cable was coming loose for fractions of a second)? It's weird that it happens exactly 30 seconds in.
Anonymous
9/8/2025, 3:28:38 PM
No.106521979
[Report]
>>106521799
Good morning saar
Anonymous
9/8/2025, 3:34:16 PM
No.106522015
[Report]
>>106522182
>>106522008
now make a clip were she admits to having a vomit drawer
Anonymous
9/8/2025, 3:35:58 PM
No.106522022
[Report]
Anonymous
9/8/2025, 3:41:04 PM
No.106522050
[Report]
>>106522182
>>106522008
I'm still at work, but if you post the reference audio and text, I'll try it with the unquanted one later.
>>106521718
My benchmark is: "does this look coherent?" At 80M tokens it's more often incoherent than not, although the underlying grammar looks like English. The text might look OK on a quick glance, but if you carefully read it you'll quickly spot nonsense. It's also very sloppy, but that's a different issue.
I guess a separate "benchmark" role could be added in a future run.
Anonymous
9/8/2025, 3:55:11 PM
No.106522145
[Report]
Pythonshit is fun until you need to actually work with cuda and accelerate and their respective configurations.
Anonymous
9/8/2025, 3:59:05 PM
No.106522173
[Report]
>>106522206
>>106522131
>still managed to sneak in a little "it's not just X, it's Y"
Anonymous
9/8/2025, 4:02:44 PM
No.106522192
[Report]
>>106522182
>it sticks a bit
jesus fuck that was grotesque. nice.
Anonymous
9/8/2025, 4:05:04 PM
No.106522206
[Report]
>>106522251
>>106522173
It has far more annoying recurring slop than that that I didn't initially notice the model was generating.
Anonymous
9/8/2025, 4:06:26 PM
No.106522222
[Report]
Anonymous
9/8/2025, 4:08:19 PM
No.106522238
[Report]
>>106522387
>>106522131
when I started out my benchmark was to see if it would stop giving lesbians a cock to play with. it took about 3b tokens for it to start to pass the test more often then not. but at some point I felt I needed a way to measure progress that was a simple number so I could tell if my training was stalling out or over fitting. I was doing perplexity tests on a couple out of domain documents.
>>106522131
What's your font? Looks nice.
Anonymous
9/8/2025, 4:10:06 PM
No.106522251
[Report]
>>106522387
>>106522206
isn't that one of the problems with synthetic data, it amplifies the slop?
Anonymous
9/8/2025, 4:14:35 PM
No.106522288
[Report]
>>106522248
Roboto Condensed
Anonymous
9/8/2025, 4:18:29 PM
No.106522315
[Report]
>>106522345
How good are the top rated CAI character cards on average? I wanna nabe a bunch of vanilla cards but that site doesn't really tell you shit about tokens, you have to download the card
Anonymous
9/8/2025, 4:21:41 PM
No.106522345
[Report]
Anonymous
9/8/2025, 4:23:20 PM
No.106522358
[Report]
Anonymous
9/8/2025, 4:27:14 PM
No.106522387
[Report]
>>106522248
It's Noto Sans Mono without font hinting.
>>106522251
I fully expected slop, but I hoped the teacher model (gpt-oss) would be a bit more varied in the responses across dozens of different types of conversations that I made it generate. I just didn't notice it until I trained a model with some preliminary data, even though I inspected the source data many times for various issues (not carefully enough, evidently).
>>106522238
I don't mind if it overfits a bit on the wording/format. At this level coherence in basic conversations is quick to test: I just hit regenerate and see what comes out.
Anonymous
9/8/2025, 4:29:28 PM
No.106522408
[Report]
>>106522432
>>106521884
>It's very large. Because when you run with CPU, it uses float32, and when you run with GPU, it uses float16.
It loads into memory whatever torch type is specified in the config. Whether it is running on CPU or GPU. Whether or not the CPU or GPU support FP16 or lower precision (Ampere and earlier, for example, do not have fp16 support). So even if the tensors are in fp16 it still takes fp32 compute time.
If you don't know what the fuck you are talking about quit saying shit and spreading misinformation based on your fetal alcohol take.
Anonymous
9/8/2025, 4:31:07 PM
No.106522432
[Report]
>>106522450
>>106522408
Ampere has fp16. A100 is Ampere.
>>106522432
It's a shame your mother didn't have abortion support since I'm obviously fucking talking about desktop GPUs because nobody here owns a fucking A100 you absolute fucking retarded stack of latent circumcision trauma.
Anonymous
9/8/2025, 4:48:24 PM
No.106522594
[Report]
>>106522450
Other Ampere GPUs also support FP16, retard-kun.
Anonymous
9/8/2025, 5:13:42 PM
No.106522803
[Report]
>>106516409
higgs has very good quality and can output professional sounding audio. It's a functional TTS.
A bit more inconsistent than vibe , sometimes it outputs trash audio, and it's system prompt seems to serve the purpose of just dictating audio quality, which often times fucks with the voice clone making it sound nothing like it. Annoying. Voice cloning is more restrictive than vibe.
Also, it frequently flubs on tone or pronunciation of words where vibe would excel even on vibe 1.5b.
here's some higgs. Like its not bad, it deserved more praise when it came out, but vibe has eclipsed it.
Higgs does gen faster (smaller model, maybe bugs have been worked out)
https://voca.ro/14SyInH21SnZ
Anonymous
9/8/2025, 5:14:18 PM
No.106522808
[Report]
>>106520056
I love Kuroko....
Anonymous
9/8/2025, 5:18:49 PM
No.106522843
[Report]